
























































































产品介绍

数据湖分析
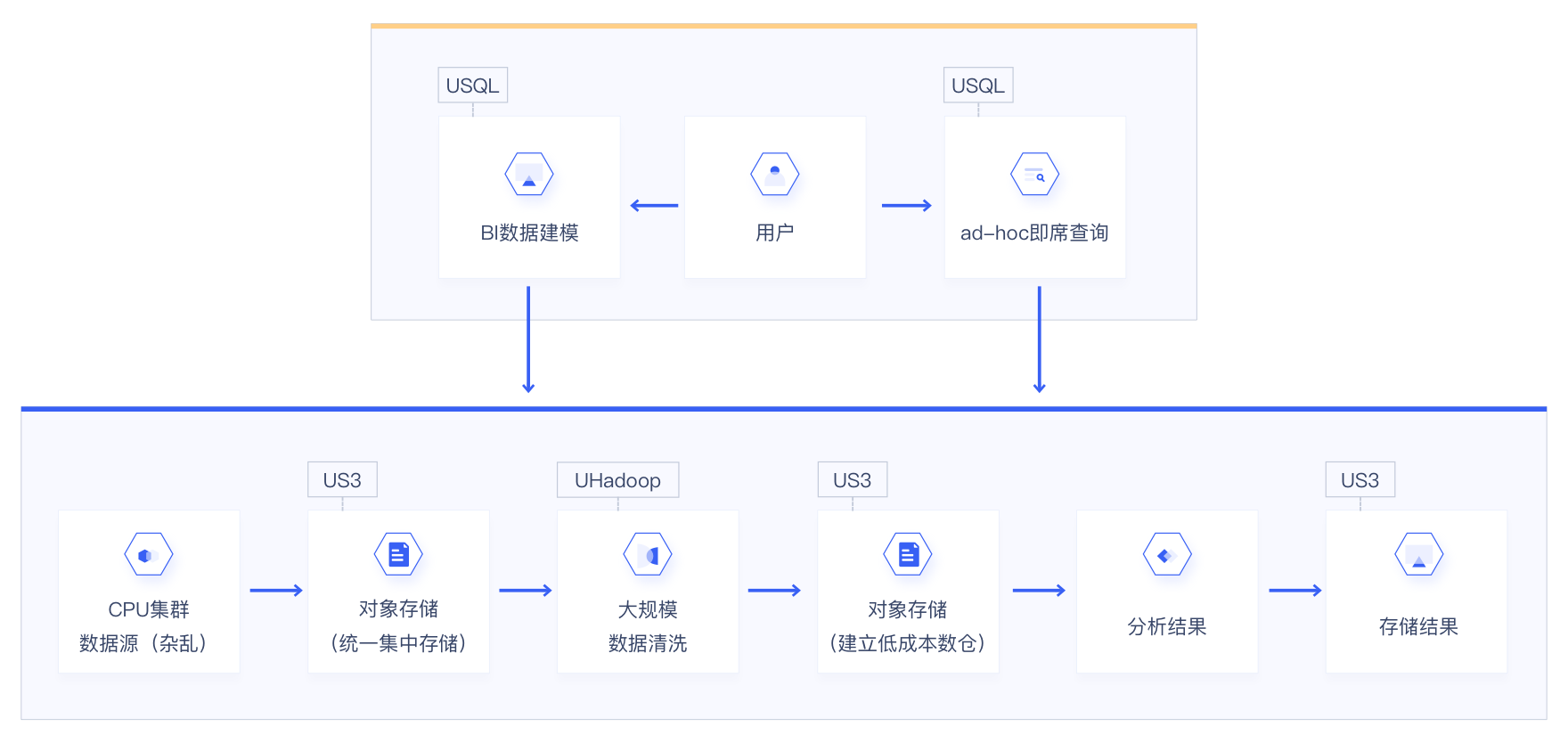
数据湖分析(USQL)是一种可扩展性强,成本低廉的无服务器的SQL分析计算引擎,用户可轻松完成面向海量数据的数据建模工作,极大降低用户使用大数据的门槛,从而使用户使用所熟悉的SQL专注于业务数据,无需数据库管理员和运维人员,大幅度减少对大数据开发工程师的依赖。
产品优势
-
 Serverless数据分析
Serverless数据分析USQL是一款Serverless的数据分析产品,拥有一键启动、开箱即用的特性,帮助您摆脱运行后端应用程序所需的服务器搭建、设置和管理工作。
-
 低成本、高效率
低成本、高效率您只需根据数据分析量费,不使用不收费,为您节约成本和人力支出。相较原有数仓ETL分析及自建Hadoop集群分析,USQL可将计算成本降低99%,将分析效率提升21.6倍。
-
 异构数据关联查询
异构数据关联查询USQL采用存储、计算相分离的模式,支持在您读取数据时灵活定义、修改数据结构,解决了传统数据仓库写入时定义数据结构带来的局限性。
-
 简单易用
简单易用您无需掌握Hadoop、Spark等大数据技术,只需学会使用SQL就可完成数据查询、提取工作。
特性对比
| 特性 | USQL | 传统方式 |
|---|---|---|
| 简化操作流程 | 数据源 → UFILE → USQL → 应用数据 | 数据源 → 数据库 → ETL → 数仓 → 存储 → 应用数据 |
| 数据格式丰富 | 读取时定义数据结构,支持关联分析JSON、ORC、CSV、PARQUET、GZIP、TAR格式存储的结构化数据 | 写入时定义数据结构,无法进行不同格式的结构化数据关联分析 |
| 高性能高效率 | USQL采用全内存计算,支持GB-PB量级数据分析,10GB级数据分析秒级完成 | 导入数据耗时久,分析数据受性能限制,GB级数据分析需数分钟至数小时 |
| 一键启动,开箱即用 | 开箱即用,操作简单,零管理成本,零启动时间 | 需要自建搭建集群,配置基础服务 |
| 计算存储分离 | 采用Shared Disk架构,纯内存计算SQL引擎,不带任何存储功能 | 计算存储不完全分离,需要缓存数据 |
| 数据迁移成本低 | 灵活兼容数据存储方式,只需将现有数据放入ufile中,就可使用DDL&SQL查询 | 数据迁移工作量大,需要提前定义数据结构,进行数据清洗, |







使用USQL产品,对原有数据文件改动较小,用户不用关注大数据分布式处理的过程,业务迁移方便。 对比我们现有的大数据处理方案,节省80%的服务器成本,提升50%数据分析速度,同时也缩短了新业务的开发周期,值得推荐。
案例详情