
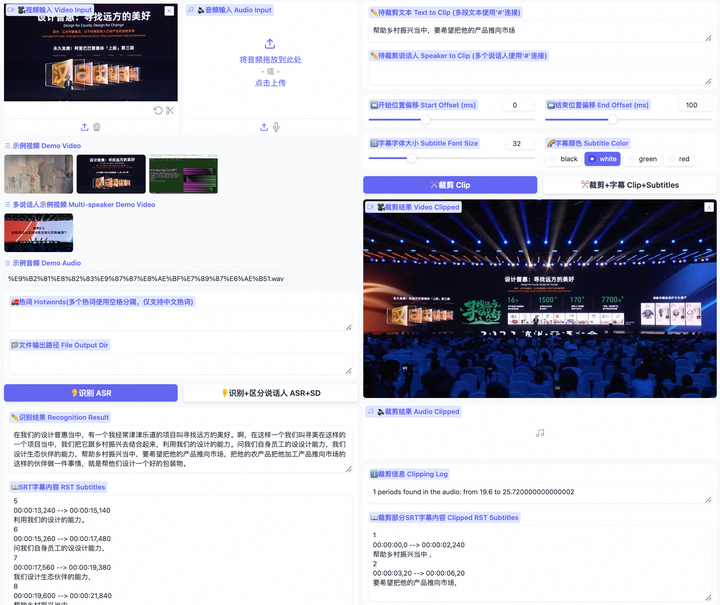
项目简介Funclip 是阿里巴巴通义实验室开源的一款视频剪辑工具,专门用于精准、便捷的视频切片。它能够自动识别视频中的中文语音并允许用户根据语音内容来裁剪视频。该工具使用了阿里巴巴语音识别模型FunASR Paraformer-Large确保了剪辑的精准性。你可以根据识别结果选择文本片段或说话人进行视频裁剪。使得视频剪辑变得非常方便。Funclip不仅支持中文,未来还将支持英文视频剪辑,是视频内...

ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得廉价算力,进行AI视频生成等模型开发和应用呢?Compshare是隶属于UCloud云计算的GPU算力平台,专注提供高性价比的NVIDIA RTX 40 系列资源,满足 AI应用、模型推理/微调、科学计算等多场景需要。UCloud本身是一家专注于公有云的云计算厂商,成立于2012年,是中国第一家科创...
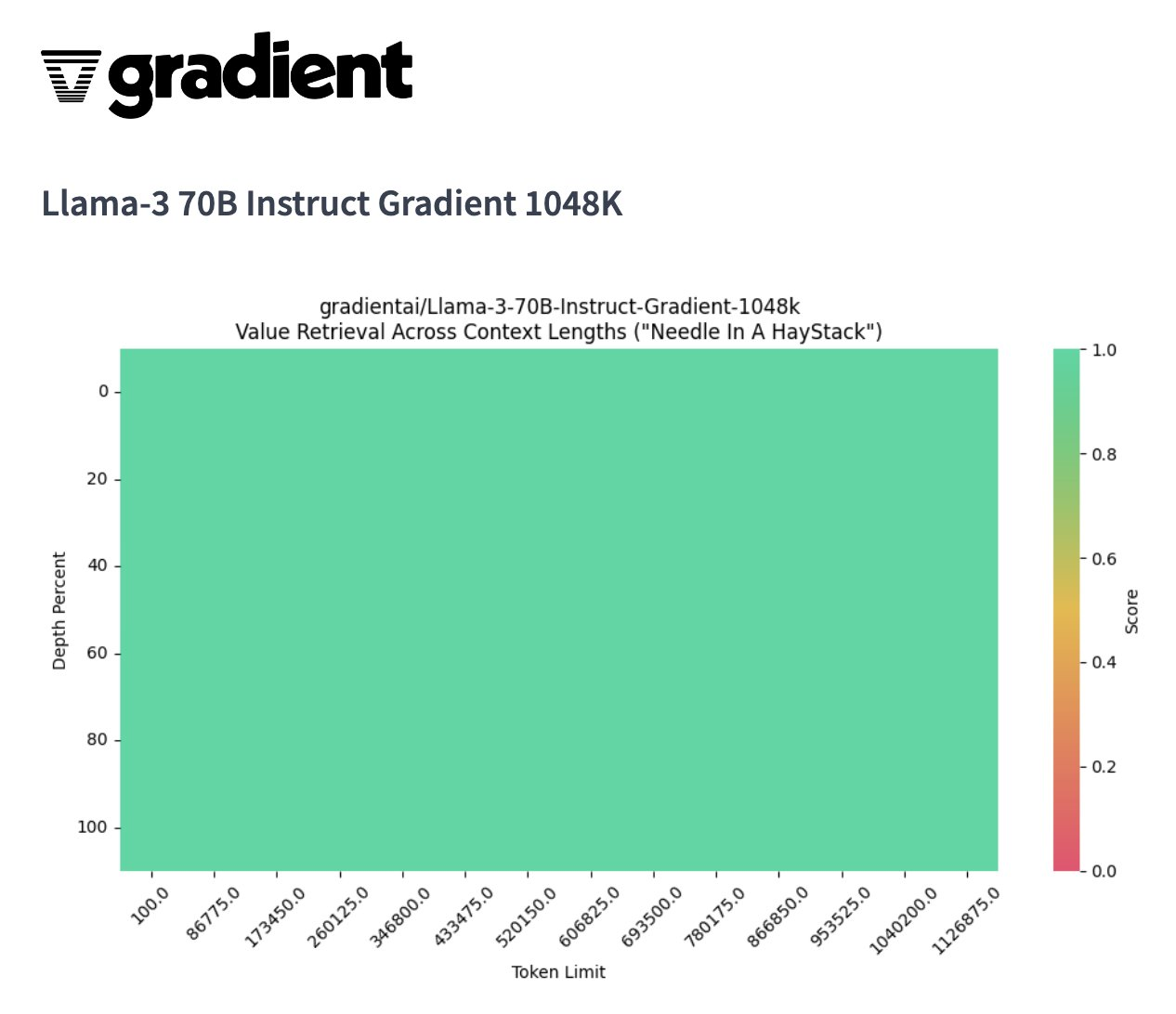
Gradient Al最近将Llama-3 8B和7B模型通过渐进式训练方法不断将Llama-3模型的上下文长度从8k-路扩展到262k、524k今天Gradient Al成功宣布成功地将Llama-3 系列模型的上下文长度扩展到超过1 M...并且1M上下文窗口 70B 模型在 NIAH(大海捞针)上取得了完美分数。Llama 3模型最初被训练用于处理8000个token的默认上下文长度,约相当...

NVIDIA和MIT的研究人员推出了一种新的视觉语言模型(VLM)预训练框架,名为VILA。这个框架旨在通过有效的嵌入对齐和动态神经网络架构,改进语言模型的视觉和文本的学习能力。VILA通过在大规模数据集如Coy0-700m上进行预训练,采用基于LLaVA模型的不同预训练策略进行测试。研究人员还引入了视觉指令调整方法,利用视觉语言数据集进行基于提示的指令调整来细化模型。VILA在视觉问答基准测试中...
NVIDIA和MIT的研究人员推出了一种新的视觉语言模型(VLM)预训练框架,名为VILA。这个框架旨在通过有效的嵌入对齐和动态神经网络架构,改进语言模型的视觉和文本的学习能力。VILA通过在大规模数据集如Coy0-700m上进行预训练,采用基于LLaVA模型的不同预训练策略进行测试。研究人员还引入了视觉指令调整方法,利用视觉语言数据集进行基于提示的指令调整来细化模型。VILA在视觉问答基准测试中...






