

项目简介AniTalker是一个开源项目,它利用静态照片和音频文件来创造动态的面部说话视频。AniTalker采用了一种通用的运动表示方法。这种创新的表示方法有效地捕捉了广泛的面部动态,包括微妙的表情和头部动作。AniTalker通过两种自监督学习策略增强了运动描述:第一种策略是通过同一身份内的源帧重建目标视频帧来学习微妙的运动表示;第二种策略是使用度量学习开发身份编码器,同时积极减少身份和运动编...

Veo是什么Veo是由Google DeepMind开发的一款视频生成模型,用户可以通过文本、图像或视频提示来指导其生成所需的视频内容,能够生成时长超过一分钟1080P分辨率的高质量视频。Veo拥有对自然语言的深入理解能够准确捕捉和执行各种电影制作术语和效果,如延时摄影或航拍镜头。Veo生成的视频不仅在视觉上更加连贯一致,而且在人物、动物和物体的动作表现上也更加逼真。Veo的开发旨在使视频制作更加...

5月20日,微软在其特别活动上,向世界介绍了一种新类别的WindowsPC,一款专为AI设计的Copilot+ PC。Copilot+ PC引入了全新的系统架构,将 CPU、GPU和高性能神经处理单元(NPU)结合在一起,并与 Azure 云中的大语言模型(LLM)和小语言模型(SLM)协同工作,带来前所未有的性能水平。微软宣称Copilot+ PC是迄今为止最快、最智能的Windows PC。它...
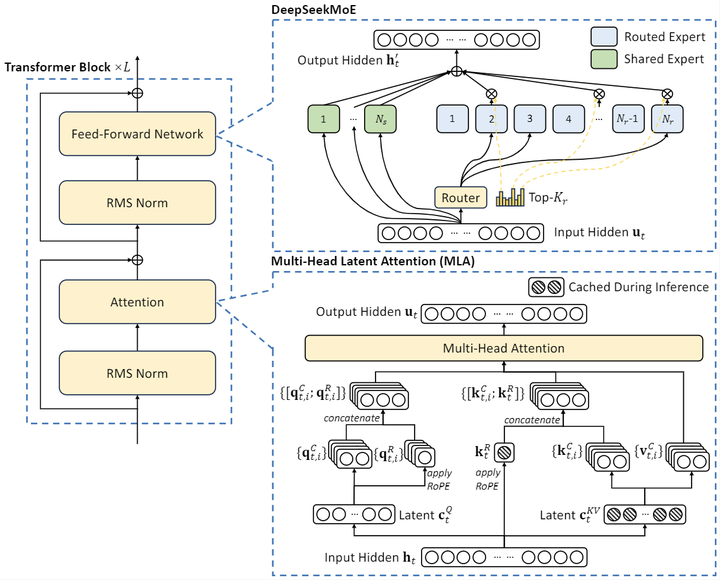
项目简介DeepSeek-V2,一个专家混合(MoE)语言模型,其特点是经济高效的训练和推理。它包含 2360 亿个总参数,其中每个token激活了21亿个参数。与 DeepSeek67B相比,DeepSeek-V2 实现了更强的性能,同时节省了 42.5%的训练成本,将 KV 缓存减少了 93.3%,并将最大生成吞吐量提高了 5.76 倍。在 AlignBench 中排名前三,超越 GPT-4,...

Llama3 中文聊天项目综合资源库,该文档集合了与Lama3 模型相关的各种中文资料,包括微调版本、有趣的权重、训练、推理、评测和部署的教程视频与文档。1. 多版本支持与创新:该仓库提供了多个版本的Lama3 模型,包括基于不同技术和偏好的微调版本,如直接中文SFT版、Instruct偏好强化学习版、趣味版等。此外,还有Phi3模型中文资料仓库的链接,和性能超越了8b版本的Llama3。2. 部...






