

回答:Hadoop生态Apache™Hadoop®项目开发了用于可靠,可扩展的分布式计算的开源软件。Apache Hadoop软件库是一个框架,该框架允许使用简单的编程模型跨计算机集群对大型数据集进行分布式处理。 它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。 库本身不是设计用来依靠硬件来提供高可用性,而是设计为在应用程序层检测和处理故障,因此可以在计算机集群的顶部提供高可用性服务,...
 娣辩孩
|
1609人阅读
娣辩孩
|
1609人阅读
回答:1998年9月4日,Google公司在美国硅谷成立。正如大家所知,它是一家做搜索引擎起家的公司。无独有偶,一位名叫Doug Cutting的美国工程师,也迷上了搜索引擎。他做了一个用于文本搜索的函数库(姑且理解为软件的功能组件),命名为Lucene。左为Doug Cutting,右为Lucene的LOGOLucene是用JAVA写成的,目标是为各种中小型应用软件加入全文检索功能。因为好用而且开源(...
 ctriptech
|
917人阅读
ctriptech
|
917人阅读
回答:MySQL是单机性能很好,基本都是内存操作,而且没有任何中间步骤。所以数据量在几千万级别一般都是直接MySQL了。hadoop是大型分布式系统,最经典的就是MapReduce的思想,特别适合处理TB以上的数据。每次处理其实内部都是分了很多步骤的,可以调度大量机器,还会对中间结果再进行汇总计算等。所以数据量小的时候就特别繁琐。但是数据量一旦起来了,优势也就来了。
 李世赞
|
569人阅读
李世赞
|
569人阅读

...Apache Spark现在非常热门。它是Apache软件基础中最活跃的大数据项目,最近也被IBM神化——其中IBM还投入了3, 500个工程师来推动它。尽管一些人还对Spark是什么有所疑惑,或者声称它将会淘汰Hadoop(也许它并不会,或者至少不...
前言 有赞数据平台从2017年上半年开始,逐步使用 SparkSQL 替代 Hive 执行离线任务,目前 SparkSQL 每天的运行作业数量5000个,占离线作业数目的55%,消耗的 cpu 资源占集群总资源的50%左右。本文介绍由 SparkSQL 替换 Hive 过程中碰到...
前言 有赞数据平台从2017年上半年开始,逐步使用 SparkSQL 替代 Hive 执行离线任务,目前 SparkSQL 每天的运行作业数量5000个,占离线作业数目的55%,消耗的 cpu 资源占集群总资源的50%左右。本文介绍由 SparkSQL 替换 Hive 过程中碰到...
...开源工具和技术,例如 Apache Spark,它是一种用于大规模数据处理的快速灵活的数据处理引擎。 CDH Spark2 是 Apache Spark 的一个版本,包含在 Cloudera Distribution for Apache Hadoop (CDH) 中。它是一个强大而灵活的数据处...
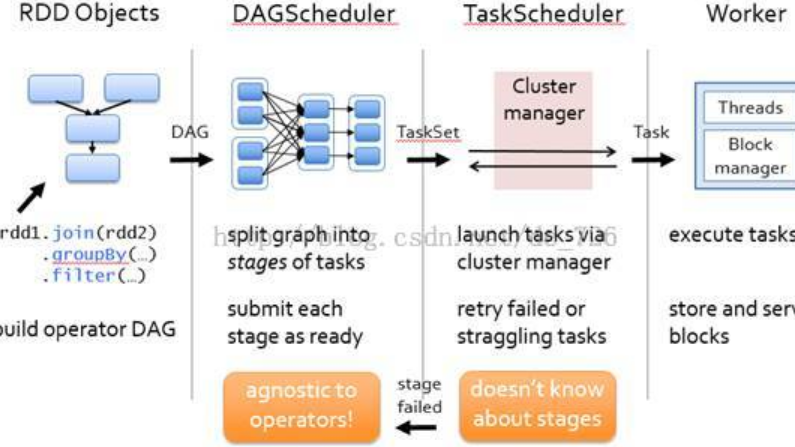
...定义一个 spark 应用程序所需要的三大步骤的逻辑:加载数据集,处理数据,结果展示。 3. Cluster Manager 集群的资源管理器,在集群上获取资源的外部服务。拿 Yarn 举例,客户端程序会向 Yarn 申请计算我这个任务需要多少的 memory...
ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得...
一、活动亮点:全球31个节点覆盖 + 线路升级,跨境业务福音!爆款云主机0.5折起:香港、海外多节点...
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,...




 刘德刚
刘德刚 刘永祥
刘永祥 未东兴
未东兴









