

回答:在Linux中,创建快捷方式可以使用符号链接(Symbolic Link)来实现。以下是创建快捷方式的步骤: 1. 打开终端并进入要创建快捷方式的目录。 2. 使用`ln -s`命令来创建符号链接。该命令的一般语法如下: ln -s 例如,如果要在当前目录下创建一个指向`/home/user/documents`目录的符号链接,可以执行以下命令: ...
 yunhao
|
1174人阅读
yunhao
|
1174人阅读

...极深的技术,首次系统表达了自己的产品理念,而大会主视觉也始终紧贴着这一理念进行设计。本文将具体介绍我们的设计思路和主要过程。 关于设计原则:知觉律与格式塔原理 1910年,心理学家Max Wertheimer在铁道口观察...
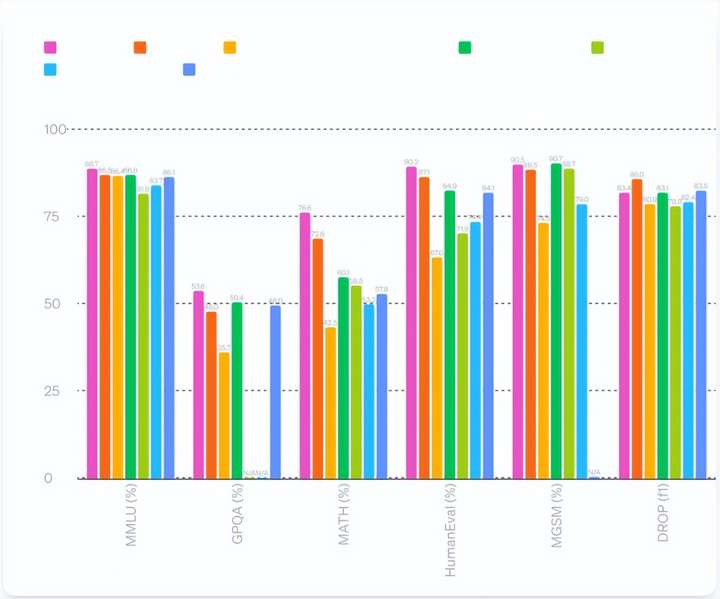
...兴地宣布,推出了全新的旗舰模型 GPT-4o,能够在音频、视觉和文本之间实时进行推理。GPT-4o(o代表omni 全方位)能够实时处理音频、视觉和文本信息,使人机交互更加自然流畅。这款模型支持多种输入(文本、音频、...
...7 月 26 日,将标志着一个时代的终结。那一天,与计算机视觉顶会 CVPR 2017 同期举行的 Workshop——超越 ILSVRC(Beyond ImageNet Large Scale Visual Recogition Challenge),将宣布计算机视觉乃至整个人工智能发展史上的里程碑——IamgeNet ...
...做了实验,然后写了篇论文。他们指出,在深度模型中,视觉任务性能随训练数据量(取对数)的增加,线性上升。以下是Google Research机器感知组指导教师,卡耐基梅隆大学助理教授Abhinav Gupta对这项工作的介绍,发布在Google Research...
摘要: 深度学习大潮为什么淹没传统的计算机视觉技术?听听大牛怎么说~ 这篇文章是受到论坛中经常出现的问题所创作的: 深度学习是否可以取代传统的计算机视觉? 这明显是一个很好的问题,深度学习(DL)已经彻底改...
...实现以及论文链接。为保证文章简明,我只总结了计算机视觉领域的成功架构。什么是高级架构?相比于单一的传统机器学习算法,深度学习算法由多样化的模型组成;这是由于神经网络在构建一个完整的端到端的模型时所提供...
最初针对视觉信号设计出来的 CNN 也能处理听觉信号,最终帮助机器倾听和更好地理解我们。 CNN 在某些程度上能迁移学习,掌握多种模式的共同特征。有一系列神经网络机器学习方法不只是「有深度的」。在这段时间,针对先...
...l.edu/papers/olshausen_field_1997.pdf) 表明,编码理论可以被用在视觉皮层的接收域中。他们证明了我们大脑中的基本视觉旋涡 (V1) 使用稀疏性原理来创建一个能够被用于重建输入图像的基本功能的最小集合。下面的链接是 2014 年伦敦微...
...ng model.CSS盒模型描述了通过 文档树中的元素 以及相应的 视觉格式化模型(visual formatting model) 所生成的矩形盒子。 基础盒模型(CSS basic box model) 当浏览器对一个 render tree 进行渲染时,浏览器的渲染引擎就会根据 基础盒模型(CSS bas...

NVIDIA和MIT的研究人员推出了一种新的视觉语言模型(VLM)预训练框架,名为VILA。这个框架旨在通过有效的嵌入对齐和动态神经网络架构,改进语言模型的视觉和文本的学习能力。VILA通过在大规模数据集如Coy0-70...
...lt;p>NVIDIA和MIT的研究人员推出了一种新的视觉语言模型(VLM)预训练框架,名为VILA。这个框架旨在通过有效的嵌入对齐和动态神经网络架构,改进语言模型的视觉和文本的学习能力。VILA通过在大规模...
...院、清华大学电子工程系的研究人员共同参与的关于高效视觉目标检测的研究已经被 CVPR 2017 接收。论文题目是 RON: Reverse Connection with Objectness Prior Networks for Object Detection。研究者包括孔涛、孙富春、Anbang Yao、刘华平、Ming Lu 和陈...
ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得...
一、活动亮点:全球31个节点覆盖 + 线路升级,跨境业务福音!爆款云主机0.5折起:香港、海外多节点...
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,...




 孙淑建
孙淑建 王岩威
王岩威 李世赞
李世赞 刘厚水
刘厚水 邹立鹏
邹立鹏














