

回答:语音助手可以分为几个步骤,语音的输入,语音分析,语音输出,输入和输出是需要依赖硬件设备的,而语音分析这里需要使用NLP技术,自然语言处理是人工智能的一个分支,Java,C,Python都可以实现的,现在人工智能方面比较火的是Python。
 doodlewind
|
871人阅读
doodlewind
|
871人阅读
回答:当然有啦,我一般都是用黑狐文字提取神器 小程序,使用简单,只要把你的英文音频导入进去,然后就可以看到系统语音识别后,转成成文字的形式,最后如果想要进行中英互译也可以哦,点击立即转化,语音准确率非常高,可以达到98%以上,几乎都不用二次修改,香!除了语音转文字,它还能够视频转文字呢!支持的格式非常多,比如wav、mp3、m4a、flv、mp4、wma、3gp、amr、aac、ogg-opus、fla...
 yy736044583
|
2001人阅读
yy736044583
|
2001人阅读
回答:人脸识别系统是计算机科学的最新应用,它利用计算机技术和生物统计技术,在各种背景下识别出人脸,更进一步可以实施跟踪,它基于人的脸部特征,属于生物识别技术。人脸识别的过程可以分成人脸检测,人脸跟踪和人脸比对三个过程。人脸检测是在动态背景或者复杂背景下将人的面部找到,并从背景中分离出来。找到人脸,有数种方法可以实施。1.设计人脸的标准模板,然后系统将采集到的图像和标准人脸模板进行对比,从匹配程度上判断是...
 BicycleWarrior
|
4623人阅读
BicycleWarrior
|
4623人阅读
...心,今天给大家安利一款超赞的云剪辑 app,它可是完全免费的,简直是我们视频创作者的福音。先来说说它超厉害的地方吧。无需安装,在线编辑,这一点真的太赞啦!完全不用占用我们设备宝贵的内存空间,而且再也不用经...

...网络结构在鲁棒性上更加出色,同时可以实现短延时的准在线解码,从而可用于工业系统中。(DFCNN 结构图)口语化和篇章级语言模型处理技术语音识别的语言模型主要用于建模音素与字词之间的对应关系。由于人类的口语为无...
...现过的,如果有,那自然是拿来即用。 首先,说说一些在线版的PDF图片转文字,对文件大小有限制为2M(似乎有很多的文件处理都是限制在这个数),超过了便要收费了。 第二,那就是WPS的PDF图片转文字了。别说大小限制了,直接...
...发。同时将用一款全新的移动端软件开发工具包资源来做语音识别,将我们想听歌曲的名字从声音转化成文字。之后,通过苹果iTtunes搜索API接口来获取歌名的专辑图片和歌曲试听资源。最后,将这些资源整合在一起,用精细的UI...
为了方便广大的开发者,特此统计了网上诸多的免费API,为您收集免费的接口服务,做一个api的搬运工,以后会每月定时更新新的接口。有些接口来自第三方,在第三方注册就可以成为他们的会员,免费使用他们的部分接口...
...台的发音支持类库,支持超过56种语言和168种声音,分为免费版和商业版。Demo speak.js 基于eSpeack改造而来的一款js单词拼读类库. meSpeak.js 是一个100%的客户端发音类库,支持chrome和safari,并且无需要任何html元素; say.js一款基于node...
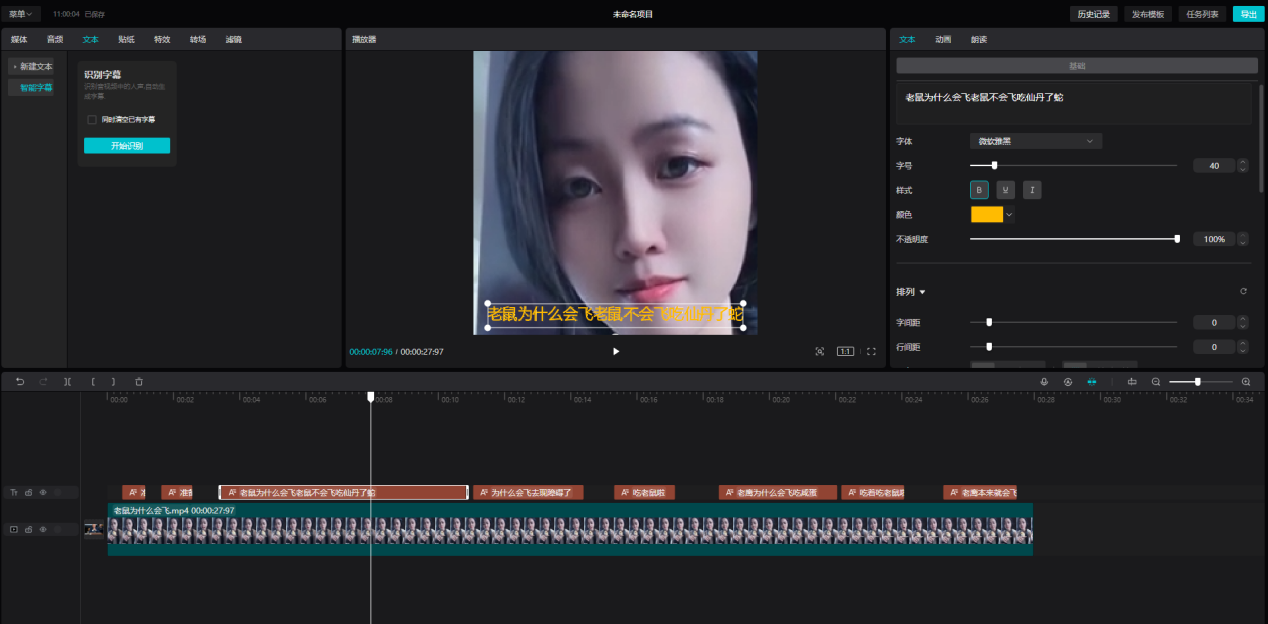
...VIP收费模式,那有没有其他的产品也能实现这个功能并且免费呢?答案当然是有,下面给大家介绍一款剪映的平替产品云剪辑,它的优点在于完全的在线编辑不需要安装臃肿的软件系统占用宝贵内存空间,最主要的是它免费...
...节或是字母组合入手,比如像th这样的组合?过去的语音识别是这么做的。过去的语音识别都有一个标准管道,你输入音频,预计这些音节到底是什么。然后你再用另一套系统,把这些音节转化成文字。不过近来人们一直在...
ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得...
一、活动亮点:全球31个节点覆盖 + 线路升级,跨境业务福音!爆款云主机0.5折起:香港、海外多节点...
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,...




 Binguner
Binguner 付永刚
付永刚 ernest
ernest










