

回答:如果你研究足够深入,可以用dd执行各种任务,但它最出色的功能就是让你可以玩转分区。当然,可以使用tar甚至scp来复制整个文件系统,办法就是从一台计算机复制文件,然后将它们原封不动地粘贴到另一台计算机上新安装的Linux。但是,由于那些文件系统归档不是完整的镜像,它们需要在两头都运行主机操作系统作为基础。另一方面,使用dd可以为几乎任何数字化内容制作逐字节对应的完美镜像。但是在你开始将分区从一个地...
 roundstones
|
1069人阅读
roundstones
|
1069人阅读
回答:Linux系统和Windows系统不同,在Linux系统中,一切都是文件,目录其实也是文件。Linux中统计文件占用磁盘空间用一个命令(du)就行了,十分简单。du命令虽然很简单,但它的功能却很强大,有很多内置参数选项,我们可以查看此文件的帮助文件,如下图示:统计目录或文件的物理大小具体指令格式为:# du -sh 文件(夹)名称比如我要统计指定目录(如 /home)下所有文件及文件夹占用的磁盘空...
 MarvinZhang
|
1261人阅读
MarvinZhang
|
1261人阅读
回答:曾经有一段时间,微软对 Linux 的态度并不友好。但随着企业战略的全面转型,该公司已经积极投身相关应用与服务的开发。甚至在 Windows 10 操作系统层面,都有专门的 Linux 子系统。最新消息是,作为开发者与 IT 经理们必不可少的一款趁手工具,微软已经完成了新版 Linux 子系统的开发(简称 WSL2),并将随 Windows 10 2004 一起提供。【资料图,来自:Microso...
 wawor4827
|
940人阅读
wawor4827
|
940人阅读
回答:linux系统是主流的话其实对于我们普通人来说没有太大区别,对于学习计算机技术的人来说才会有很大的帮助。所以世界大概还是这样子。不会因为一个计算机系统的变化而有多少不同
 Anonymous1
|
669人阅读
Anonymous1
|
669人阅读
回答:这个问题,看来提问的人下过功夫,我许久不做大型计算机设计了。复杂系统管理经验也不是很充足,因为以前一直以研发为主。系统性能最大化是个好问题,建议速去我们,ucloud云,百度云这种拥有巨大用户群的企业去做系统管理,就能把握这类技能。云管理与维护是重大任务,需要大量技术人员。前途无量,祝邀请者前程似锦。我现在只写实验用程序,是一台跑不动win10的笔记本。
 NotFound
|
1606人阅读
NotFound
|
1606人阅读

...例。 持久存储通常以分层方式实现,在块设备(如旋转磁盘或SSD)之上使用文件系统(如ext4)。然后,应用程序读取和写入文件,而不是在块上操作。操作系统负责使用指定的文件系统,将文件作为块读取和写入底层设备。 值...
...例。 持久存储通常以分层方式实现,在块设备(如旋转磁盘或SSD)之上使用文件系统(如ext4)。然后,应用程序读取和写入文件,而不是在块上操作。操作系统负责使用指定的文件系统,将文件作为块读取和写入底层设备。 值...
...运行、数据库。以下测试比较了数据库型物理云主机(SAS磁盘)与SSD型云主机在Raid10与Raid5下的三项性能指标。测试数据测试1. 顺序读/写512K测试2. 随机读/写 4K (IOPS)测试3. 随机读/写 4K (IO延迟)测试详情工具:fio官方网站:http://fr...
注意:此文档仅为IO性能的基准值测试,由于本地磁盘为共享磁盘,其IO会有一定波动,使性能达不到文档中测试出的水准。若您希望更稳定的IO,建议您选择云盘。 硬盘性能指标 顺序读写 (吞吐量,常用单位为MB/s)...
云主机UHost本地磁盘I/O性能测试注意:此文档仅为IO性能的基准值测试,由于本地磁盘为共享磁盘,其IO会有一定波动,使性能达不到文档中测试出的水准。若您希望更稳定的IO,建议您选择云盘。硬盘性能指标顺序读写 (吞吐量...
...于 CDN 来说,每台 Cache 机器每天的请求量是十分惊人的,磁盘上所存储的内容量也多得可怕,十几块 TB 级的硬盘被塞满数据也是很正常的事情,因此当一个请求到来时,能迅速检索出磁盘上的文件并读取、吐给最终用户成了一...
...于 CDN 来说,每台 Cache 机器每天的请求量是十分惊人的,磁盘上所存储的内容量也多得可怕,十几块 TB 级的硬盘被塞满数据也是很正常的事情,因此当一个请求到来时,能迅速检索出磁盘上的文件并读取、吐给最终用户成了一...
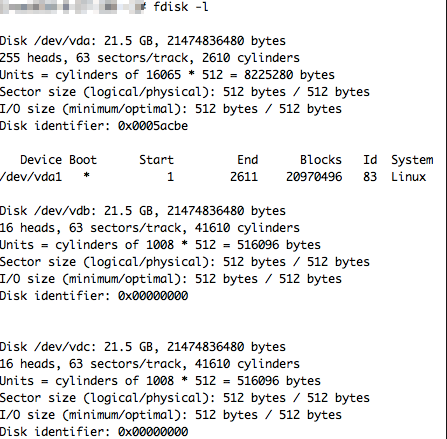
磁盘本篇目录查看硬盘分区系统盘扩容数据盘扩容挂载云硬盘卸载云硬盘本地磁盘缩容磁盘快照查看硬盘分区登陆云主机后,使用fdisk -l命令查看云主机的硬盘分区(Ubuntu中需要root权限)。系统盘:/dev/vda 数据盘1:/dev/vdb ...
...b 数据盘2:/dev/vdc云主机UHost系统盘扩容1、扩容规则不同磁盘类型,遵循不同的磁盘扩容规则:2、扩容步骤创建/重装主机时扩容:1)在创建/重装主机页面,选择系统盘大小;2)等待创建/重装完毕,此时底层块设备已扩容完成...
...在内核缓冲区中找不到这块数据,内核会先将这块数据从磁盘中读出来放到内核缓冲区中,应用程序再从缓冲区中读取。当应用程序需要将数据输出(write())时,同样需要先将数据拷贝到输出堆栈相关的内核缓冲区,再从内核...
...在内核缓冲区中找不到这块数据,内核会先将这块数据从磁盘中读出来放到内核缓冲区中,应用程序再从缓冲区中读取。当应用程序需要将数据输出(write())时,同样需要先将数据拷贝到输出堆栈相关的内核缓冲区,再从内核...
...在内核缓冲区中找不到这块数据,内核会先将这块数据从磁盘中读出来放到内核缓冲区中,应用程序再从缓冲区中读取。当应用程序需要将数据输出(write())时,同样需要先将数据拷贝到输出堆栈相关的内核缓冲区,再从内核...
ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得...
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,...
图示为GPU性能排行榜,我们可以看到所有GPU的原始相关性能图表。同时根据训练、推理能力由高到低做了...




 william
william















