

回答:安装 HBase(Hadoop Database)是在 Linux 操作系统上进行大规模数据存储和处理的一种分布式数据库解决方案。以下是在 Linux 上安装 HBase 的一般步骤: 步骤 1:安装 Java 在 Linux 上安装 HBase 需要 Java 运行时环境(JRE)或 Java 开发工具包(JDK)。您可以通过以下命令安装 OpenJDK: 对于 Ubuntu/Debian...
 hyuan
|
993人阅读
hyuan
|
993人阅读
回答:一、区别:1、Hbase: 基于Hadoop数据库,是一种NoSQL数据库;HBase表是物理表,适合存放非结构化的数据。2、hive:本身不存储数据,通过SQL来计算和处理HDFS上的结构化数据,依赖HDFS和MapReduce;hive中的表是纯逻辑表。Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,二者通常协作配合使用。二、适用场景:1、Hbase:海量明细数据的随机...
 wizChen
|
2843人阅读
wizChen
|
2843人阅读
问题描述:[hadoop@usdp01 ~]$ hbase shellSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/opt/usdp-srv/srv/udp/2.0.0.0/hdfs/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]...
回答:1. 如果你对数据的读写要求极高,并且你的数据规模不大,也不需要长期存储,选redis;2. 如果你的数据规模较大,对数据的读性能要求很高,数据表的结构需要经常变,有时还需要做一些聚合查询,选MongoDB;3. 如果你需要构造一个搜索引擎或者你想搞一个看着高大上的数据可视化平台,并且你的数据有一定的分析价值或者你的老板是土豪,选ElasticSearch;4. 如果你需要存储海量数据,连你自己都...
 xiao7cn
|
1050人阅读
xiao7cn
|
1050人阅读
回答:MySQL是单机性能很好,基本都是内存操作,而且没有任何中间步骤。所以数据量在几千万级别一般都是直接MySQL了。hadoop是大型分布式系统,最经典的就是MapReduce的思想,特别适合处理TB以上的数据。每次处理其实内部都是分了很多步骤的,可以调度大量机器,还会对中间结果再进行汇总计算等。所以数据量小的时候就特别繁琐。但是数据量一旦起来了,优势也就来了。
 李世赞
|
572人阅读
李世赞
|
572人阅读

...件存储系统——HDFS 分布式计算框架——MapReduce 集群资源管理器——YARN Hadoop单机伪集群环境搭建 Hadoop集群环境搭建 HDFS常用Shell命令 HDFS Java API的使用 基于Zookeeper搭建Hadoop高可用集群 二、Hive Hive简介及核心概念 Linux环境下Hive...
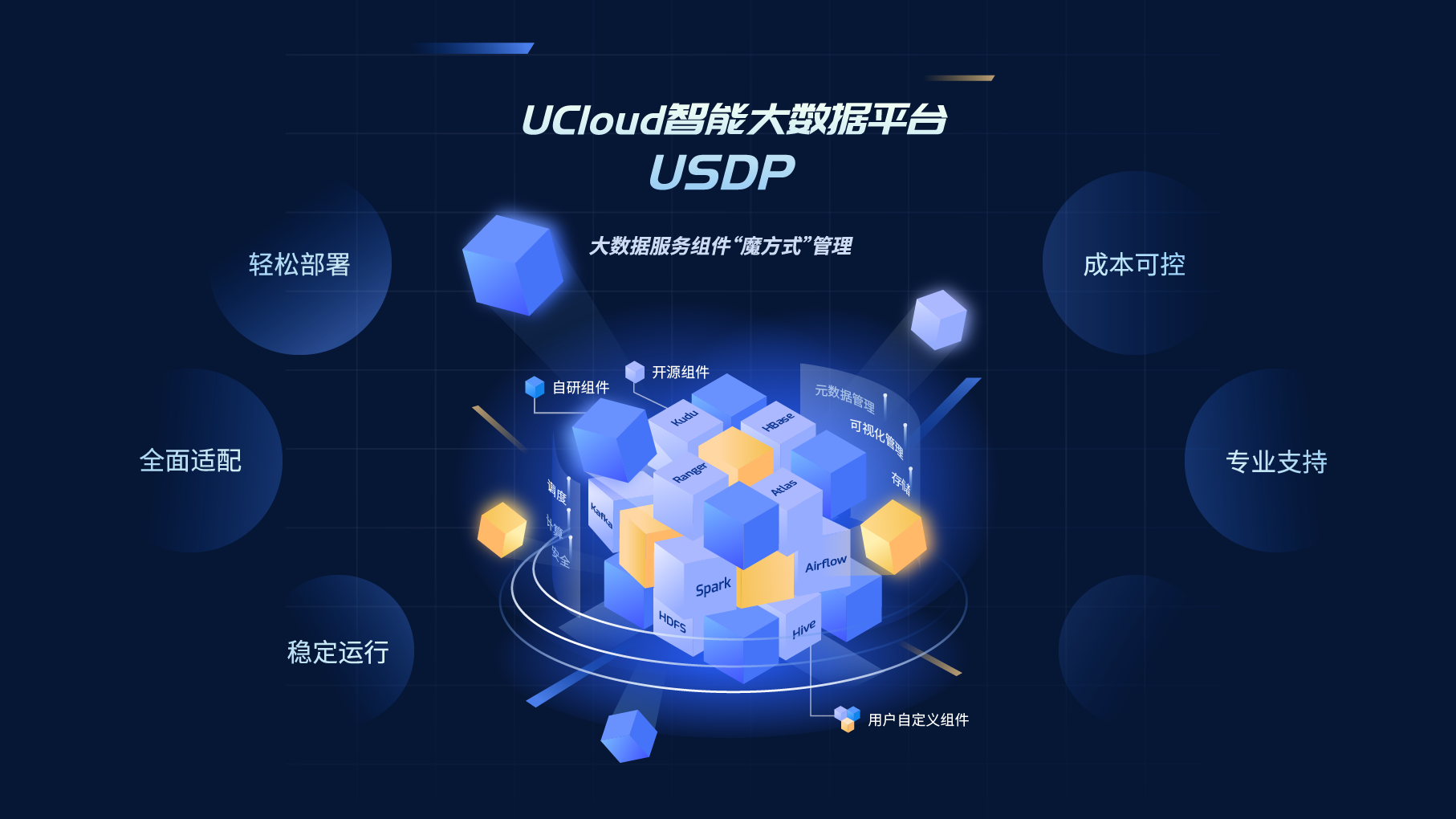
...上,无缝集成云端 IaaS 资源能力,通过自研的 USDP Manager 管理工具,支持用户创建资源独享的大数据集群,在集群中部署 Hadoop、Hive、HBase、Spark、Flink、Presto 等开源的大数据组件,并对这些组件进行配置管理、监控告警、故障诊...
...上,无缝集成云端 IaaS 资源能力,通过自研的 USDP Manager 管理工具,支持用户创建资源独享的大数据集群,在集群中部署 Hadoop、Hive、HBase、Spark、Flink、Presto 等开源的大数据组件,并对这些组件进行配置管理、监控告警、故障诊...
...上,无缝集成云端 IaaS 资源能力,通过自研的 USDP Manager 管理工具,支持用户创建资源独享的大数据集群,在集群中部署 Hadoop、Hive、HBase、Spark、Flink、Presto 等开源的大数据组件,并对这些组件进行配置管理、监控告警、故障诊...
...MySQL王者晋级之路》 《深入浅出MySQL 数据库开发、优化与管理维护》 《MongoDB权威指南(第2版)》 Redis类 《Redis开发与运维》 《Redis设计与实现(第二版)》 《Redis深度历险:核心原理与应用实践》 Spring类 《Spring 5核心原理与30个...
...上,无缝集成云端 IaaS 资源能力,通过自研的 USDP Manager 管理工具,支持用户创建资源独享的大数据集群,在集群中部署 Hadoop、Hive、HBase、Spark、Flink、Presto 等开源的大数据组件,并对这些组件进行配置管理、监控告警、故障诊...
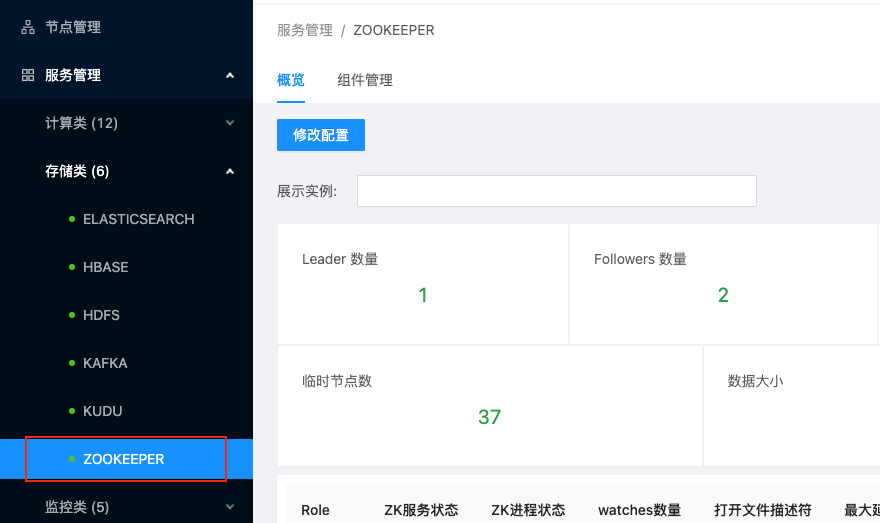
存储类服务管理本篇目录Zookeeper服务管理HDFS服务管理其他存储类服务管理在USDP1.0.0.0版本中,集群存储类服务组件主要有Elasticsearch、HBase、HDFS、Kafka、KUDU、Zookeeper在内的6个服务组件,下面将以Zookeeper及HDFS为代表展示存储类组...
...如果build失败,那肯定是缺少Make或者Autotools等东西,用包管理器安装即可。 $ git clone git://github.com/OpenTSDB/opentsdb.git$ cd opentsdb$ ./build.sh 创建表OpenTSDB所需要的表结构: $ env COMPRESSION=NONE ./src/create_table.sh2016-01-08...
...rafodion集群中安装并启动Sqoop。更多信息,请参阅Scoop用户指南。 安装必需软件 在Trafodion集群中安装JDK 1.8 and the Oracle JDBC 驱动,仅用于将数据从RDBMS导入Hive表。请设置以下环境变量: export JAVA_HOME=/opt/java/jdk1.8.0_11 export JAVA_OPTIONS=...
...ls torchvision.transforms torchvision.utils HBase 参考指南 3.0 翻译活动 参与方式:https://github.com/apachecn/h... 整体进度:https://github.com/apachecn/h... 项目仓库:https://github.com/apachecn/h... ...
ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得...
一、活动亮点:全球31个节点覆盖 + 线路升级,跨境业务福音!爆款云主机0.5折起:香港、海外多节点...
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,...















