

回答:首先咱们需要明白这两个的概念平均差平均差是表示各个变量值之间差异程度的数值之一。指各个变量值同平均数的的离差绝对值的算术平均数。标准差标准差是离均差平方的算术平均数的平方根,用σ表示。标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。那我们为什么使用标准差而非平均差来反映离散程度呢?之前问过很多人这个问题,但一直没有得到满意的解答。大部分的回答集中为以下两条:1,两者都能反映离散程度,只...
 tracy
|
3293人阅读
tracy
|
3293人阅读
回答:谢谢邀请!如果已经有一定的编程基础,比如具备C语言的编程基础,那么通过知识迁移是可以快速掌握Java编程的,但是如果自身并没有编程语言的基础,那么学习Java则要一步一个脚印,在求快的同时也要求稳。Java语言经过多年的发展已经形成了一个比较完善的语言生态,在Web开发、Android开发、大数据开发等领域都有广泛的应用,可以说如今的Java已经是一个语言帝国了。Java语言虽然内容比较多,但是基...
 lily_wang
|
1187人阅读
lily_wang
|
1187人阅读
回答:云服务器是强大的物理或虚拟基础架构,可执行应用程序和信息处理存储。云服务器使用虚拟化软件创建,将物理(裸金属)服务器划分为多个虚拟服务器。组织使用基础设施即服务(IaaS)模型来处理工作负载和存储信息。他们可以通过在线界面远程访问虚拟服务器功能。主要特点:可以是物理(裸金属)、虚拟或两者的混合的计算基础结构,具体取决于用例。具有本地服务器的所有功能。使用户能够处理密集的工作负载并存储大量信息。自动...
 付伦
|
1295人阅读
付伦
|
1295人阅读

... 前不久,我们讨论了运维不容错过的 4个关键指标,其中平均解决时间(MTTR)被认为是衡量业务的最佳标准,随后也分析了「告警等级」对MTTR的重要性。 正确看待 MTTR MTTR 为从故障发生到故障修复所经历的时间。总故障时间是...
...包括应用是否能以足够好的性能处理请求。对于一个大型服务器而言,重启 MySQL 后,可能需要几个小时才能预热数据以保证请求的响应时间。这里的几个小时也应该包括在宕机时间内。 到此为止,我们应该有个大致的印象,可...
...包括应用是否能以足够好的性能处理请求。对于一个大型服务器而言,重启 MySQL 后,可能需要几个小时才能预热数据以保证请求的响应时间。这里的几个小时也应该包括在宕机时间内。 到此为止,我们应该有个大致的印象,可...
...应该是,actionable的。 告警的实质可以用下图表明: 服务器的设计应该是以这样的无人值守为目的的。假设所有的运维全部放假了,服务也能7*24自动运转。 告警的实质就是把人当服务用。在一些事情还没有办法做到程...
...长不出故障的时间,那就是做冗余,冗余的越多,系统的故障率就越低,并且是呈指数级降低。不管是机房故障,还是存储故障,甚至是网络故障,都能依赖冗余去解决,比如数据库可以通过增加从库的方式做冗余,服务层可以...
...获取赞誉,而是经营一个不会出现大量突发事故的健康的服务器环境。由「平均恢复前时间」所驱动的生产运作系统管理通常会误认为,一个迅速解决大量突发事故的团队十分高效,而实际上这更有可能意味着该团队的基础设施...
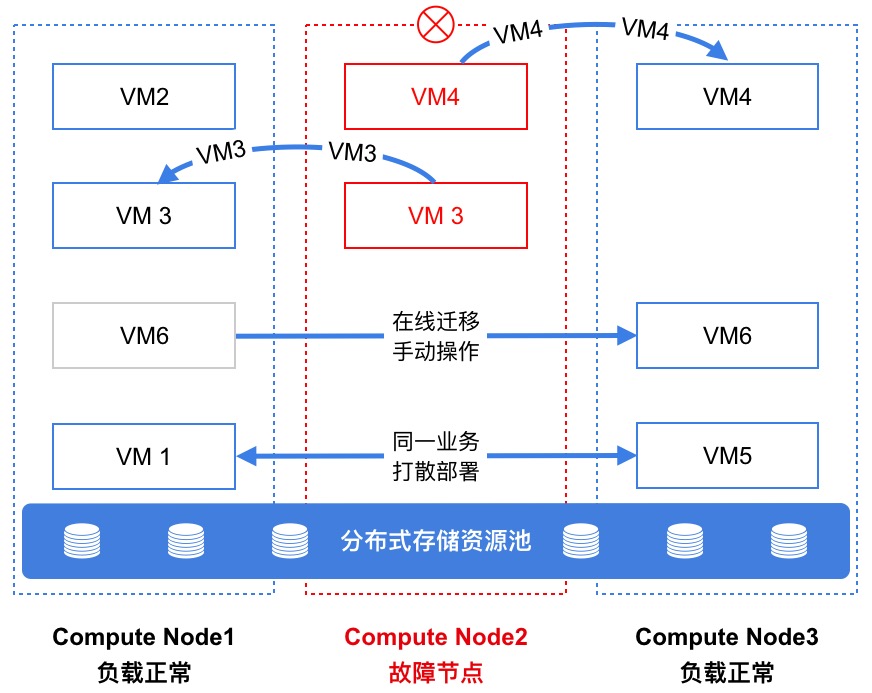
...度任务的控制和管理,用于决策虚拟机运行在哪一台物理服务器上,同时管理虚拟机状态及迁移计划,保证虚拟机可用性和可靠性。智能调度系统实时监测集群所有计算节点计算、存储、网络等负载信息,作为虚拟机调度和管理...
调查研究表明,当数据中心停机时间的损失平均每分钟近9,000美元时,避免这种事件是节省数据中心成本的首个也是效果最为显著的方法。不过,以下有四种方法可以帮助组织的数据中心避免停机,并优化性能。1.调试数据中...
...以解决。 通过上述例子,我们可以发现,在用户与业务服务器之间,存在着一个漫长的路径: 从手机侧到附近基站,再到移动的GGSN,再经过互联网骨干网,再到腾讯服务器。 香港数码通与新世界电讯联网问题 QQ日活跃用户有...
...务需求即时部署数据库资源,无需在业务初期采购高成本服务器,有效减少前期一次性大规模成本投入,弹性付费模式也能避免资源的闲置浪费。 总结 随着企业的数据量越来越大,数据库性能的提升变得尤为重要。快杰UDB...
ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得...
一、活动亮点:全球31个节点覆盖 + 线路升级,跨境业务福音!爆款云主机0.5折起:香港、海外多节点...
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,...




 刘明
刘明 张利勇
张利勇 张宪坤
张宪坤















