

回答:您好,我是数据僧(头条,公众号,简书),,一名数据相关从业者。下面讲讲我对您这个问题的理解。Hive是为了解决什么问题,Hive产生的背景,我们以这个为引子,展开回答。1,MapReduce编程的不变性,如果要处理一些数据处理的任务,会有一定的门槛,并且操作起来不方便。2,Hdfs上的文件缺少Schema。例如:缺少 字段名,数据类型等,不方面数据进行有效管理。3,用于解决海量结构化数据的统计问题...
 Leo_chen
|
649人阅读
Leo_chen
|
649人阅读
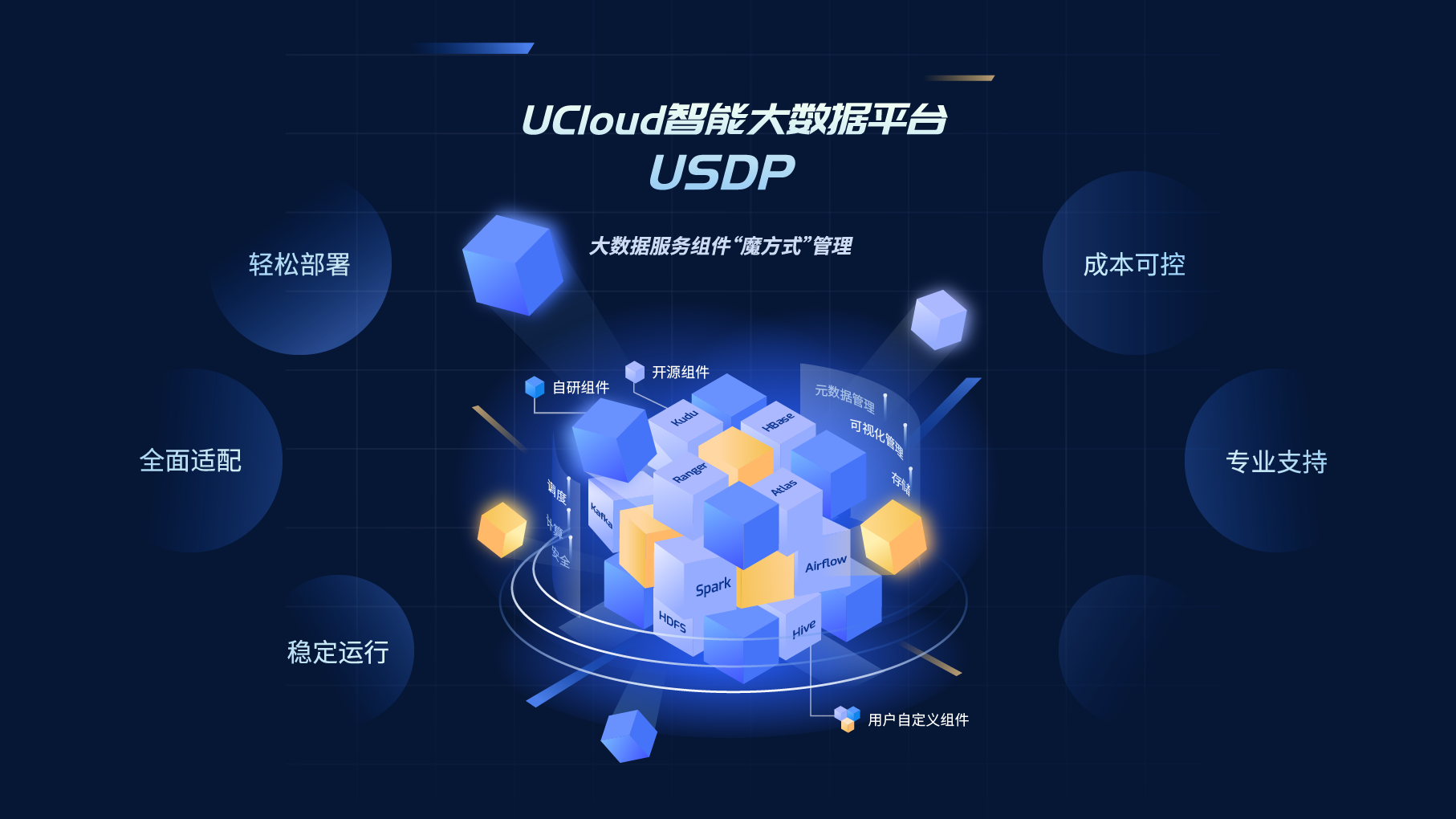
...的 USDP Manager 管理工具,支持用户创建资源独享的大数据集群,在集群中部署 Hadoop、Hive、HBase、Spark、Flink、Presto 等开源的大数据组件,并对这些组件进行配置管理、监控告警、故障诊断等智能化的运维管理,从而帮助您快速构...
...的 USDP Manager 管理工具,支持用户创建资源独享的大数据集群,在集群中部署 Hadoop、Hive、HBase、Spark、Flink、Presto 等开源的大数据组件,并对这些组件进行配置管理、监控告警、故障诊断等智能化的运维管理,从而帮助您快速构...
...的 USDP Manager 管理工具,支持用户创建资源独享的大数据集群,在集群中部署 Hadoop、Hive、HBase、Spark、Flink、Presto 等开源的大数据组件,并对这些组件进行配置管理、监控告警、故障诊断等智能化的运维管理,从而帮助您快速构...
...的 USDP Manager 管理工具,支持用户创建资源独享的大数据集群,在集群中部署 Hadoop、Hive、HBase、Spark、Flink、Presto 等开源的大数据组件,并对这些组件进行配置管理、监控告警、故障诊断等智能化的运维管理,从而帮助您快速构...

...术专家刘峥和张维,对弹性计算最新上线的 serverless (无服务器化)计算技术Bazaar及基于该技术的容器服务产品 Severless Kubernetes 进行了解析。并就满足 serverless 用户在不管理底层基础设施的情况下,如何简化用户业务部署流程...
...kafka是最合适的。因为它的性能是最高的。即使在廉价的服务器上,也能支持单机每秒100k条以上的数据量。所以说它的性能是非常好的。kafka仅仅使用内存进行存储,只要有足够的内存,就能够足够大的吞吐量。因为kafka并没有...
...由超级计算集群scch5实例组成。SCC与弹性裸金属(神龙)服务器一脉相承,既提供了云计算的成熟管控、弹性资源优势,又达到了物理机的性能,并在此之上加入高速RDMA互联支持,大幅提升网络性能,显著提高大规模集群加速比...
...素 性能,可用性,伸缩性这几个要素基本都涉及到应用服务器,缓存服务器,存储服务器这几个方面 概述 三个纬度:演化、模式、要素 五个要素: 性能,可用性,伸缩性,扩展性,安全 演化历程 图例可参考 大型网站架构...
...面虚拟化。(5)云计算平台管理技术云计算资源规模庞大,服务器数量众多并分布在不同的地点,同时运行着数百种应用,如何有效的管理这些服务器,保证整个系统提供不间断的服务是巨大的挑战。云计算系统的平台管理技术能...
...障层QOS,如果我们做存储计算分离,就意味着底层的三个集群需要布三套,这样每个集群就会有几十台甚至几百台的节点,此时存储力是由大家来均摊的,这就意味着分布式安全隔离保障层要做好隔离性,引入QOS就意味着会增加...
ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得...
一、活动亮点:全球31个节点覆盖 + 线路升级,跨境业务福音!爆款云主机0.5折起:香港、海外多节点...
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,...




 李增田
李增田 张巨伟
张巨伟 godiscoder
godiscoder 付伦
付伦 韩冰
韩冰











