

回答:这个太范化了吧。大数据架构选择的方案就有很多,海量数据的即席查询本省就是业内目前的痛点,暂时没有太好的解决方案,kylin等框架也只是一个折中方案,如果你不是要求海量数据分析的秒级响应的话sparkSql、presto等都是不错的方案,分钟级别可以返回。
 Paul_King
|
714人阅读
Paul_King
|
714人阅读
回答:首先建议题主描述清楚应用场景,否则别人做的方案可能都不符合需求。就Hadoop和OpenStack的纠结而言,支撑数据分析用前者,做资源管理用后者。=================补充=============题主的需求,实质是搭建一个IoT实时大数据平台,而不是一般意义的私有云。IoTa大数据平台除了数据采集和结果反馈,其余部分和一般的大数据平台相差不多。OpenStack长于管理VM资源管理...
 MonoLog
|
1091人阅读
MonoLog
|
1091人阅读
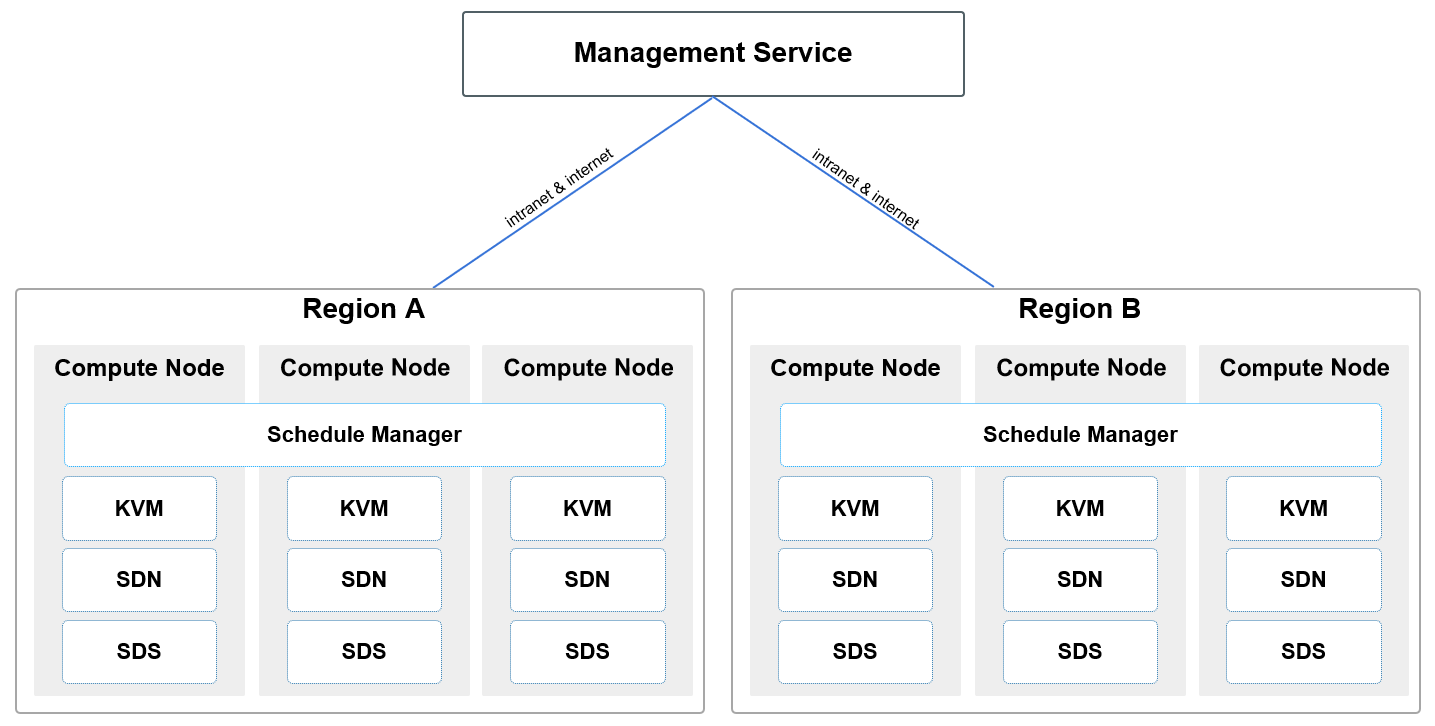

...、并发控制、系统管理等方面具有自身独特的技术。海量分布式存储技术为保证高可用、高可靠和经济性,云计算采用分布式存储的方式来存储数据和冗余存储的方式来保证存储数据的可靠性,从而提供廉价可靠的系统。为了满...

...数据生态服务有: 大数据生态服务服务版本描述FLINK1.10.1分布式计算引擎FLUME1.9.0数据采集与转储服务HIVE2.3.6常用的HQL数仓工具IMPALA2.10.0分布式计算服务KYLIN3.1.0数仓维度建模服务LIVY0.7.0Spark的REST服务PHOENIX4.14.3HBaseSQL化查询分析工...
...项maven依赖至较新版本,如spring等; 简介 XXL-CONF 是一个分布式配置管理平台,拥有强一致性、毫秒级动态推送、多环境、多语言、配置监听、权限控制、版本回滚等特性。现已开放源代码,开箱即用。 特性 1、简单: 部署简...
...控制增强,细粒度到环境权限校验; 简介 XXL-CONF 是一个分布式配置管理平台,拥有强一致性、毫秒级动态推送、多环境、多语言、配置监听、权限控制、版本回滚等特性。现已开放源代码,开箱即用。 特性 1、简单: 部署简...
...上进行处理。主要特点是能把所有数据保存在一个地方。分布式管理中,数据的存储和处理都是在本地工作站上进行的通过网络主要是得到更快、更便捷的数据访问。优点是可以快速访问、多用户使用。每台计算机可以访问系统...
...定要处理的数据量。对于大量数据,我们需要大型机器或分布式系统。计算时间随数据量的增加而增加。所以如果我们能并行化计算,最好使用分布式系统。数据可以是结构化数据、非结构化数据或介于两者之间的数据。如果我...
一、背景简介 分布式系统中存在很多拆分的服务,在不断迭代升级的过程中,会出现如下常见的棘手情况: 某个技术组件版本升级,依赖包升级导致部分语法或者API过期,或者组件修复紧急的问题,从而会导致分布式系...
...把存放在传统ECM系统中的文件、图片、影像等内容向开放分布式平台迁移。一般来说,用户可以选择的方案根据场景与数据类型来看可以分为几类,包括HDFS方案、对象存储方案、NAS方案、以及分布式数据库方案等。 其中,HDFS方...
...f/ 下载地址 https://github.com/xuxueli/xx... 概述 XXL-CONF 是一个分布式配置管理平台,提供统一的配置管理服务。现已开放源代码,开箱即用。 特性 1、简单: 提供简洁实用的API,多种方式灵活获取配置,上手简单; 2、在线管理: 提...
...gistry层,避免逐个请求耗时; 简介 XXL-CONF 是一个轻量级分布式配置管理平台,拥有轻量级、秒级动态推送、多环境、多语言、配置监听、权限控制、版本回滚等特性。现已开放源代码,开箱即用。 特性 1、简单易用: 接入灵...
...域网)。VXLAN已获得多个行业领先厂商的支持。3、大规模分布式存储技术进入创新高峰期在云计算环境下,存储技术将主要朝着从安全性、便携性及数据访问等方向发展。分布存储的目标是利用多台服务器的存储资源来满足单台...
ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得...
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,...
图示为GPU性能排行榜,我们可以看到所有GPU的原始相关性能图表。同时根据训练、推理能力由高到低做了...




 马永翠
马永翠 张汉庆
张汉庆 高璐
高璐















