

监控告警原型图 原型图解释 prometheus与alertmanager作为container运行在同一个pods中并交由Deployment控制器管理,alertmanager默认开启9093端口,因为我们的prometheus与alertmanager是处于同一个pod中,所以prometheus直接使用localhost:9093就可以...
...使用Prometheus+Grafana来监控JVM。本文介绍如何使用Prometheus+Alertmanager来对JVM的某些情况作出告警。 本文所提到的脚本可以在这里下载。 摘要 用到的工具: Docker,本文大量使用了Docker来启动各个应用。 Prometheus,负责抓取/存储指...
... TYPE DATA AGE alertmanager-main Opaque 1 27d 我们可以看到这个secrect,看下里面具体内容: [root@dev-86-...
... TYPE DATA AGE alertmanager-main Opaque 1 27d 我们可以看到这个secrect,看下里面具体内容: [root@dev-86-...
...部署在UK8S集群中,包含三大监控模块,分别是Prometheus、Alertmanager、Grafana,高可用模式下,Prometheus及Alertmanager分别部署2个和3个副本,也支持单节点模式。同时,为了简化监控服务部署的负担,监控中心启动后,会默认安装NodeEx...
...字报警是一个重要功能,对于监控报警主要用Prometheus + Alertmanager实现。应用运行过程中,根据日志关键字告警部的应用场景,从Logstash部分对日志做分流(具体方案可以看上面图的报警部分),自研grok_export对日志进行过滤分析...
...可视化。PromQL和其他API可视化地展示收集的数据,并通过Alertmanager提供报警能力。 组件内容 Prometheus Server负责从 Exporter 拉取和存储监控数据,并提供一套灵活的查询语言(PromQL) Retrieval: 采样模块 TSDB: 存储模块默认本地存储...
...可视化。PromQL和其他API可视化地展示收集的数据,并通过Alertmanager提供报警能力。 组件内容 Prometheus Server负责从 Exporter 拉取和存储监控数据,并提供一套灵活的查询语言(PromQL) Retrieval: 采样模块 TSDB: 存储模块默认本地存储...
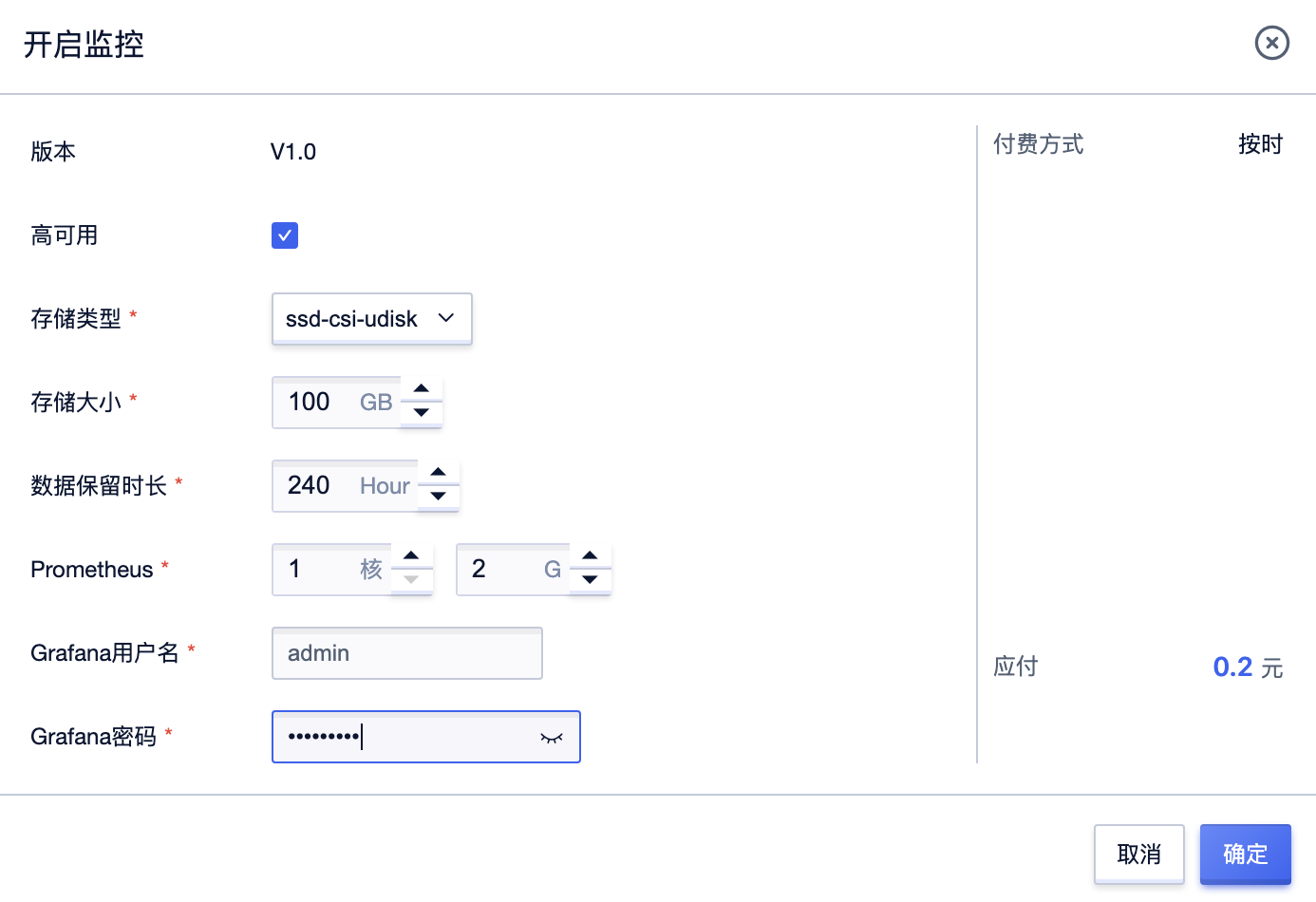
...建议可用资源大于4C8G)至少有3个Node节点的可用资源大于Alertmanager的容器配置。(建议可用资源大于1C2G)由于Prometheus和Alertmanager均需要持久性存储,因此会产生额外的UDisk费用。其中Prometheus为2块100G UDisk,Alertmanager为3块 UDisk。...
...cs格式的信息,ServiceMonitor也可以定义目标的metrics的url。 Alertmanager:Prometheus Operator 不只是提供 Prometheus Server 管理与部署,也包含了 AlertManager,并且一样通过一个 kind: Alertmanager 自定义资源来描述信息,再由 Operator 依据描述内...
...xporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。Alertmanager: 从 Prometheus server 端接收到 alerts 后,会去除重复数据,分组,并路由到对应的接受方式,发出报警。工作原理如上图可见,Prometheus 的主要模块包括:Prometheus ser...
...时间:15天。原有的storage.tsdb.retention配置已经被废弃 --alertmanager.timeout=10s 把报警发送给alertmanager的超时限制 10s --query.timeout=2m 查询超时时间限制默认为2min,超过自动被kill掉。可以结合grafana的限时配置如60s --query.max-concurrency...
...时间:15天。原有的storage.tsdb.retention配置已经被废弃 --alertmanager.timeout=10s 把报警发送给alertmanager的超时限制 10s --query.timeout=2m 查询超时时间限制默认为2min,超过自动被kill掉。可以结合grafana的限时配置如60s --query.max-concurrency...
ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得...
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,...
图示为GPU性能排行榜,我们可以看到所有GPU的原始相关性能图表。同时根据训练、推理能力由高到低做了...



















