

...,内置所有环境,即拉即用。第一步:登录「优云智算」算力共享平台并进入「镜像社区」,新用户免费体验10小时4090地址:https://www.compshare.cn/?ytag=seo 第二步:选择「vLLM-DeepSeek-R1-Distill」镜像,点击「使用该镜像创建实例」镜...
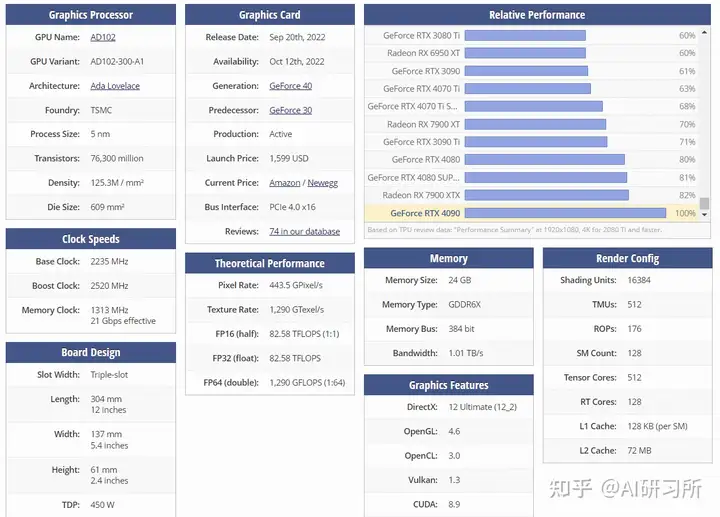

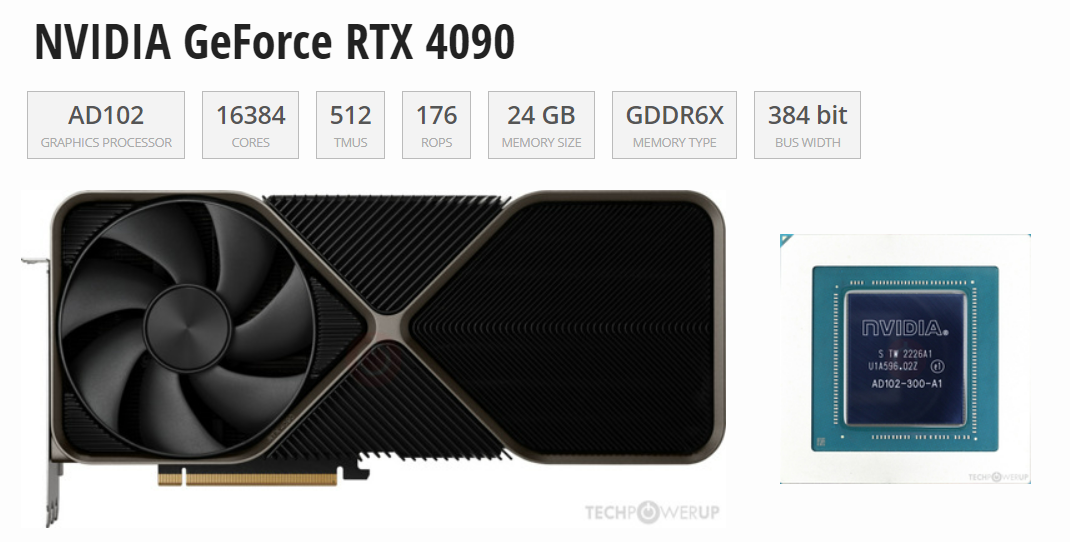
...ng: 0.034em; text-align: justify; font-size: 16px;>RTX 4090在FP16算力上达到了330 TFlops,在FP32算力上达到了83 FPlops,这些数值表明该显卡在处理复杂的算法和大规模数据集时具有极高的效率。RTX 4090在FP32模式下的算力虽然低于FP16,但仍...

...关于价格以下是市面上一家算力共享平台的4090以及4090D云服务器的价格,其中我们可以看到,在内存更小,总存储小地多且性能低10%的情况下,4090D的价格竟然是比性能更强且规格更大的4090贵出不少...
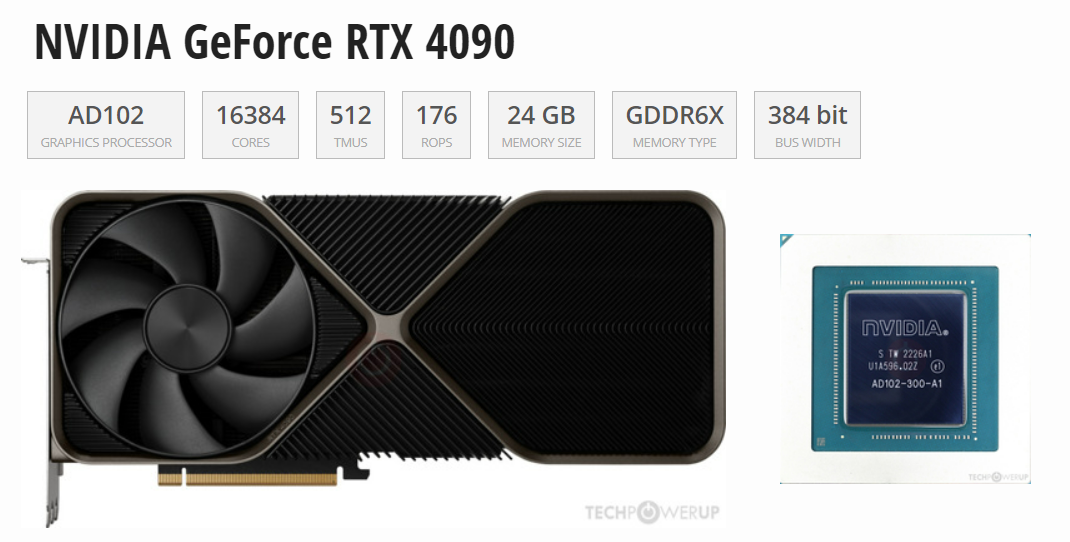
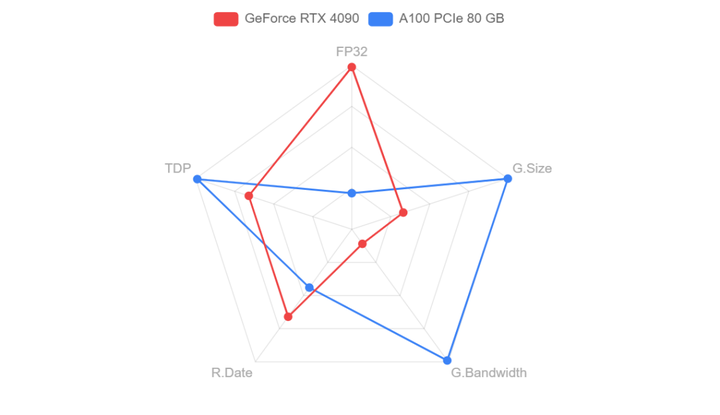
...但在和A100的PK中,4090与A100除了在显存和通信上有差异,算力差异与显存相比并不大,而4090是A100价格的1/10,因此如果用在模型推理场景下,4090性价比完胜!(尾部附参数源文件)
...前代产品,尽管其性能稍逊一筹,但其312 Tflops的Tensor FP16算力和156 Tflops的Tensor FP32算力仍然十分强劲。与H100相同的80 GB显存和900 GB/s通信带宽使得它在很多应用场景中依旧具有很高的性价比。

Compshare是一个专注于提供高性价比算力资源的平台,它为AI训练、深度学习、科研计算等场景提供强大的支持。平台的核心优势在于其高效的GPU算力资源,用户可以根据自己的需求,灵活选择不同的GPU配置,实现一键部署和即算...


...度学习模型进行推理和交互。第一步:登录「优云智算」算力共享平台并进入「镜像社区」地址:https://www.compshare.cn/?ytag=seo第二步:选择「DeepSeek-R1-32B」镜像,点击「使用该镜像创建实例」镜像地址:https://www.compshare.cn/images-det...
... rgb(255, 255, 255);>第一步:登录「优云智算」算力共享平台并进入「镜像社区」地址:https://www.compshare.cn/?ytag=seo
...云服务器一体机解决方案:性能表现:包括GPU型号覆盖、算力效率、分布式训练支持等。可靠性:服务稳定性、容灾能力、SLA承诺。生态整合:与AI框架的兼容性、多模态大模型支持、开发者工具链。性价比:单位算力成本、弹...
...70B 模型的参数是 140 GB,不管 A100/H100 还是 4090 都是单卡放不下的。那么 2 张 H100 够吗?看起来 160 GB 是够了,但是剩下的 20 GB 如果用来放 KV Cache,要么把 batch size 压缩一半,要么把 token 最大长度压缩一半,听起来...
.../www.ucloud.cn/site/active/gpu.html?ytag=seocompshare算力共享平台,高性价比4090显卡,配备独立IP,支持按时、按天、按月灵活计费。适合AI推理、微调用户场景使用。https://www.compshare.cn/?ytag=seo&...
ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得...
一、活动亮点:全球31个节点覆盖 + 线路升级,跨境业务福音!爆款云主机0.5折起:香港、海外多节点...
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,...








