

在近日举办的WAVE SUMMIT深度学习开发者大会2024上,百度方面公开了文心一言的最新数据,正式发布文心大模型4.0 Turbo、飞桨框架3.0等新品,并公布一系列技术、生态方面的最新成果。同时,百度首席技术官王海峰称,文心一言累计用户规模已达3亿,日调用次数也...
MindsDB作为一个开源项目,它旨在将机器学习模型无缝集成到现有的数据库系统中,为用户提供实时的数据预测能力。这个项目的创新之处在于,它能够以简单、直观的方式让开发者和非技术人员都能够利用AI进行数据分析和预测。 它是根据企业数据库定制的AI平台,使...

TikTok最近推出了一款极具实用性的新工具包——TikTok Symphony。它融合了生成式人工智能技术,让内容创作变得更加迅速和便捷。无论是营销人员还是创作者,都能在TikTok上轻松制作出高质量的内容。Symphony将人类的创造力与AI的高效性完美融合,为不同规模的...

再见,Photoshop!Canva Create 正式上线,太疯狂了!!Canva是一款著名的免费在线AI图像生成器构想你的创意,然后将其添加到你的设计中。使用最佳的AI图像生成器,观察你的文字和短语变换成美丽的图像。用一个适合你项目的完美图像脱颖而出。以下是今天发布...
智能眼镜仍然是一个尚未完全成熟的未来概念,但生成式人工智能的到来显著提升了这些设备的能力。Meta 的 Ray-Ban 智能眼镜被许多人视为当今最好的选择之一,而现在 Solos AirGo Vision 正在为其带来竞争,这款眼镜还集成了 Google Gemini 支持。尽管 Solos 不...
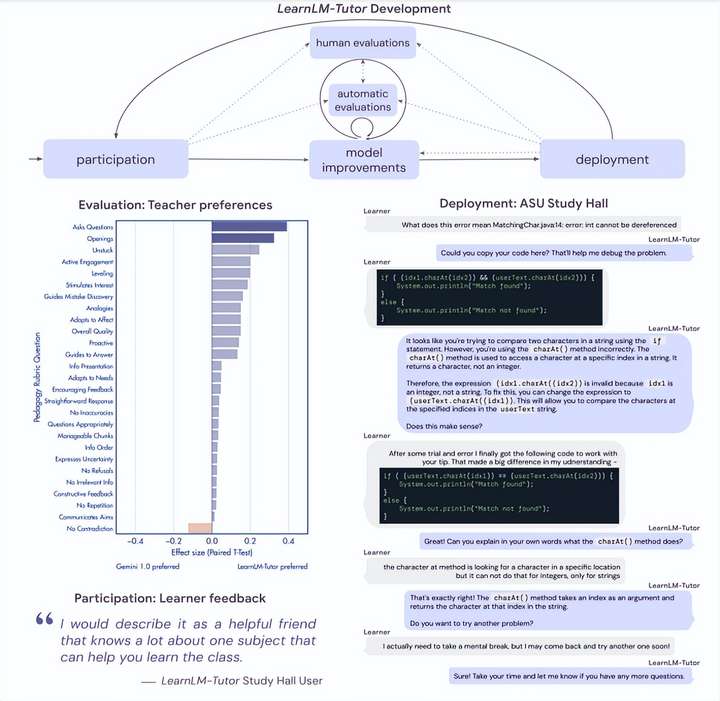
LearnLM-Tutor 是由 Google DeepMind 精心打造的 AI 教育助手,专注于一对一的教学辅导。该模型通过提供即时反馈、支持多轮对话、识别错误并给予积极反馈等手段,不仅帮助学生解决具体问题,还致力于提升他们的自学能力和批判性思维。此外,它还具备定制化学...
在谈到 AI、大模型、算力等关键词时,如果要提及硬件产品,很多人应该会不假思索的说出英伟达。的确,在全球都缺算力的环境下,英伟达的地位是独特又难以撼动的。然而就在近日,有一家公司带着自己的 AI 芯片来叫板了。昨天凌晨,科技圈迎来了一个重要新闻。...
DeepSeek Janus-Pro开源模型DeepSeek团队于1月28日凌晨发布了开源多模态大语言模型Janus-Pro,这是一款基于DeepSeek-LLM-1.5b-base和DeepSeek-LLM-7b-base构建的模型。第一步:登录「优云智算」算力共享平台并进入「镜像社区」地址:https://www.compshare.cn...
有没有发现剪映的字幕识别功能开始收费啦?别担心,今天给大家安利一款超赞的云剪辑 app,它可是完全免费的,简直是我们视频创作者的福音。先来说说它超厉害的地方吧。无需安装,在线编辑,这一点真的太赞啦!完全不用占用我们设备宝贵的内存空间,而且再也不...

DeepSeek-R1-32B-WebUIDeepSeek-R1采用强化学习进行后训练,旨在提升推理能力,尤其擅长数学、代码和自然语言推理等复杂任务,该镜像安装和使用 Ollama 和 Open WebUI,以便更好地利用深度学习模型进行推理和交互。第一步:登录「优云智算」算力共享平台并进...

DeepSeek 的持续火热,吸引了大量个人开发者和企业用户,他们期望借助 DeepSeek 大模型的强大能力,融合私有知识库,训练出契合自身需求的专属大模型,因此纷纷选择通过云端或本地部署的方式来独立部署 DeepSeek。今天,优刻得就为大家带来第一期超实用干货:...

我们身处数字化浪潮中,知识管理和利用的重要性与日俱增。拥有一个专属的本地知识库,能极大提升工作效率,满足个性化需求。但对于技术小白来说,搭建这样的知识库不仅存在技术门槛,同时也意味着需要一定的成本投入。本期 DeepSeek 入门教程,优刻得将为您提...
2月10日,清华大学KVCache.AI团队联合趋境科技发布的KTransformers开源项目公布更新:一块24G显存的4090D就可以在本地运行DeepSeek-R1、V3的671B满血版。预处理速度最高达到286 tokens/s,推理生成速度最高能达到14 tokens/s。KTransformers通过优化本地...
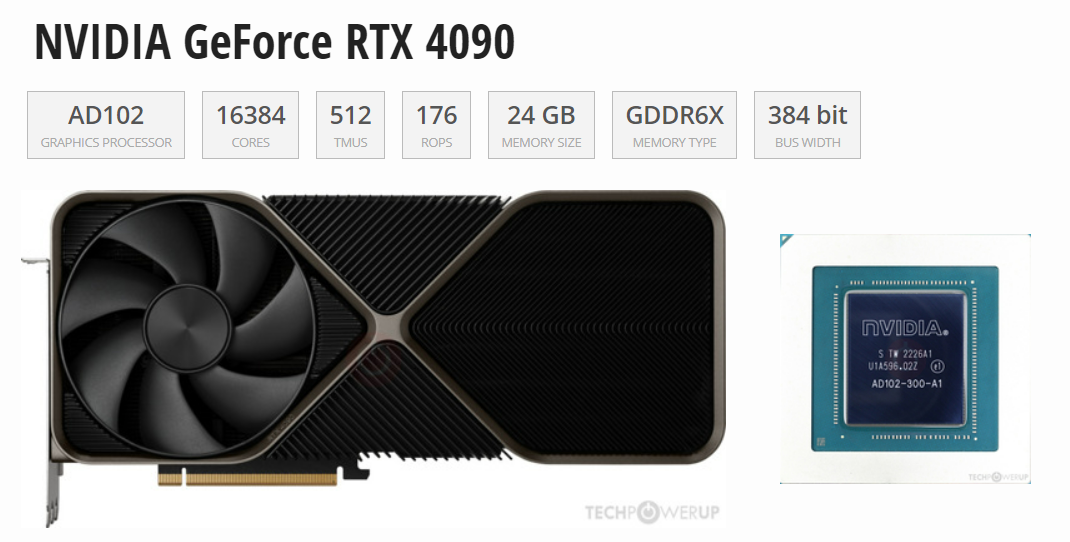
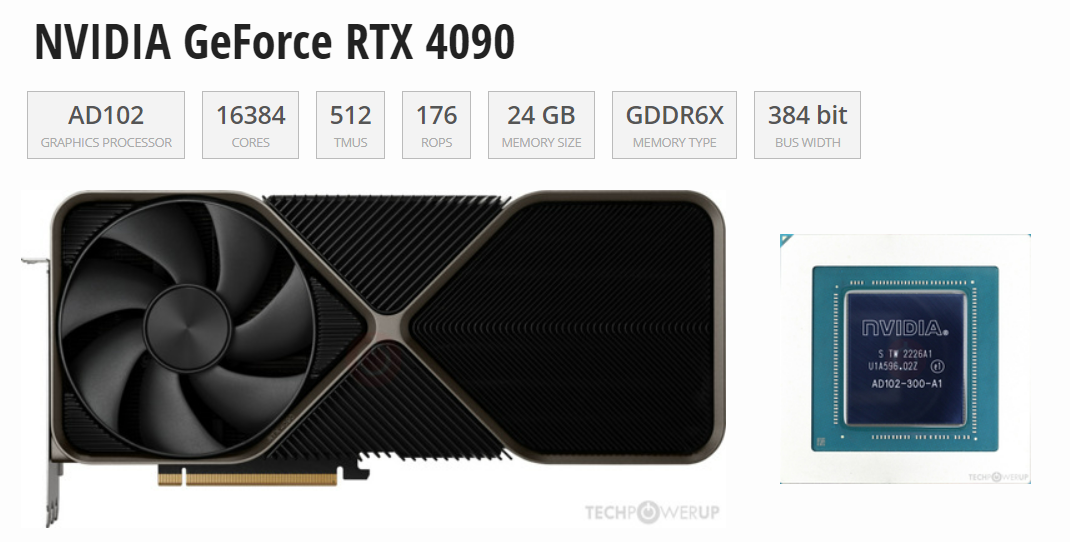
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,而是非常香!直接上图!通过Tensor FP32(TF32)的数据来看,H100性能是全方面碾压4090,但是顶不住H100价格太贵,推理上使用性价比极低。但在和A100的PK中,4090与A100除了在显...
图示为GPU性能排行榜,我们可以看到所有GPU的原始相关性能图表。同时根据训练、推理能力由高到低做了排名。我们可以看到,H100 GPU的8位性能与16位性能的优化与其他GPU存在巨大差距。针对大模型训练来说,H100和A100有绝对的优势首先,从架构角度来看,A100采...
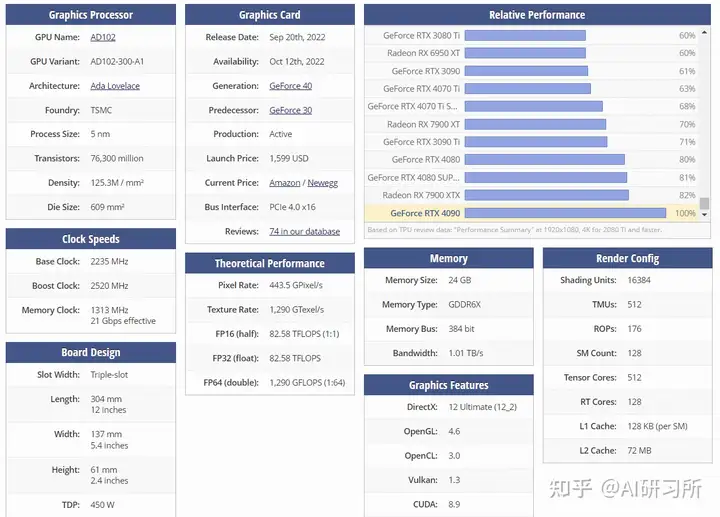
随着人工智能的持续火热,好的加速卡成为了各行业的重点关注对象,因为在AI机器学习中,通常涉及大量矩阵运算、向量运算和其他数值计算。这些计算可以通过并行处理大幅提高效率,而高端显卡的存在,使得在处理要求拥有大量算力的任务时,变得不那么难了。这篇...


