

号称地表最强人形机器人,来了。当地时间周二早晨,获得微软、英伟达、OpenAI投资的硅谷著名智能创业公司 Figure 正式发布了自己的新一代人形机器人Figure 02。基于机载算力和各个组件的全方位升级,AI人形机器人朝着进厂打工又迈进了一大步。据介绍...
GOT-OCR2.0是一款新一代的光学字符识别(OCR)技术,标志着人工智能在文本识别领域的重大进步。作为一款开源模型,GOT-OCR2.0不仅支持传统的文本和文档识别,还能够处理乐谱、图表以及复杂的数学公式,为用户提供了更加全面和高效的解决方案。产品功能及特点...
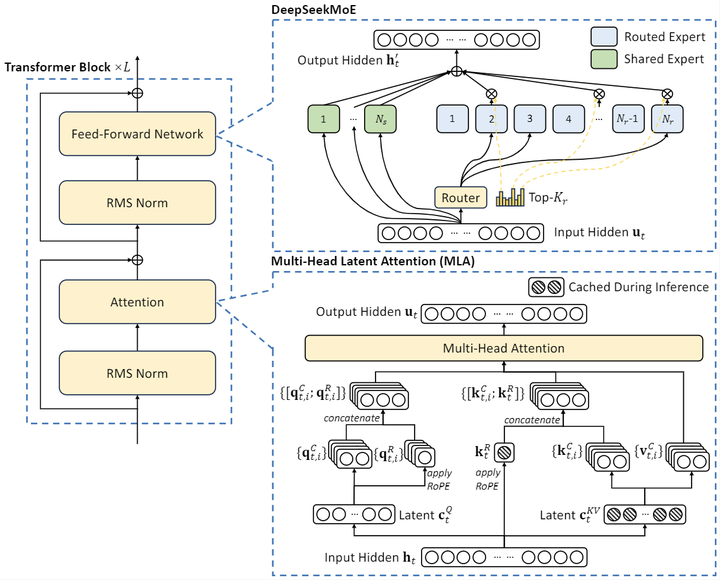
项目简介DeepSeek-V2,一个专家混合(MoE)语言模型,其特点是经济高效的训练和推理。它包含 2360 亿个总参数,其中每个token激活了21亿个参数。与 DeepSeek67B相比,DeepSeek-V2 实现了更强的性能,同时节省了 42.5%的训练成本,将 KV 缓存减少了 93.3%,并将...

昨天,2024年大选的结果揭晓了,这场被认为是过去60年来最为胶着的总统选举,终于画上了句号。川普再次成为了白宫的主人。对于广大跨境电商卖家来说,川普的胜任可谓是一颗重磅炸弹,他的经济政策可能会对跨境电商行业产生较深影响。为大家猜想一下可能出现的...

Llama3-8B-Chinese-Chat 是基于 Meta-Llama-3-8B-Instruct 模型通过 ORPO进行微调的中文聊天模型。与原始的 Meta-Llama-3-8B-Instruct 模型相比,此模型显著减少了中文问题英文回答"和混合中英文回答的问题。此外,相较于原模型,新模型在回答中大量减少了...

Llama3 中文聊天项目综合资源库,该文档集合了与Lama3 模型相关的各种中文资料,包括微调版本、有趣的权重、训练、推理、评测和部署的教程视频与文档。1. 多版本支持与创新:该仓库提供了多个版本的Lama3 模型,包括基于不同技术和偏好的微调版本,如直接中文...
DeepSeek Janus-Pro开源模型DeepSeek团队于1月28日凌晨发布了开源多模态大语言模型Janus-Pro,这是一款基于DeepSeek-LLM-1.5b-base和DeepSeek-LLM-7b-base构建的模型。第一步:登录「优云智算」算力共享平台并进入「镜像社区」地址:https://www.compshare.cn...
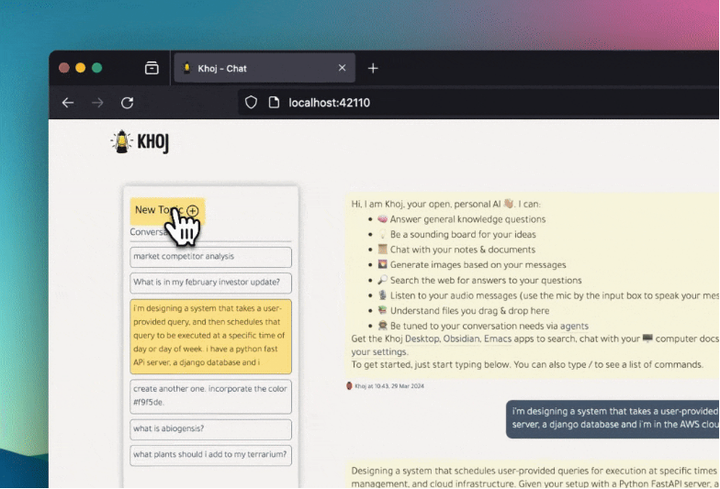
项目简介Khoj是一个开源的、个人化的AI助手,旨在充当你的第二大脑。它能够帮助你回答任何问题,不论这些问题是在线上的还是在你自己的笔记中。Khoi 支持使用在线AI模型(例如 GPT-4)或私有、本地的语言模型(例如 Llama3)。你可以选择自托管 Khoj,也可以使用...
v0是一个专为网页开发设计的智能助手,它通过对话形式提供服务。你可以与v0进行互动,无论是代码调试、解答编程问题还是生成代码片段,v0都能在前端开发领域提供专业的帮助。它精通TypeScript、React、Next.js、Vercel等前端技术,能够为你提供深入的技术指导...
随着大型模型技术的持续发展,视频生成技术正逐步走向成熟。以Sora、Gen-3等闭源视频生成模型为代表的技术,正在重新定义行业的未来格局。而近几个月,国产的AI视频生成模型也是层出不穷,像是快手可灵、字节即梦、智谱清影、Vidu、PixVerse V2 等。就在近日,...

DeepSeek 的持续火热,吸引了大量个人开发者和企业用户,他们期望借助 DeepSeek 大模型的强大能力,融合私有知识库,训练出契合自身需求的专属大模型,因此纷纷选择通过云端或本地部署的方式来独立部署 DeepSeek。今天,优刻得就为大家带来第一期超实用干货:...
前几个月OpenAI大名鼎鼎的Sora 一经发布,似乎象征着视频领域已经进入了生成式 AI 时代。不过直到今天,我们仍然没有用上OpenAI 的官方视频生成工具,等不及的人们已经开始寻找其他的方法。其中不乏一些国内的厂商如快手的可灵等等。而在近日,一款全新的开源...
简介近年来,人工智能(AI)技术的进步极大地改变了人类与机器的互动方式,特别是在语音处理领域。阿里巴巴通义实验室最近开源了一个名为FunAudioLLM的语音大模型项目,旨在促进人类与大型语言模型(LLMs)之间的自然语音交互。FunAudioLLM包含两个核心模型:...
2月10日,清华大学KVCache.AI团队联合趋境科技发布的KTransformers开源项目公布更新:一块24G显存的4090D就可以在本地运行DeepSeek-R1、V3的671B满血版。预处理速度最高达到286 tokens/s,推理生成速度最高能达到14 tokens/s。KTransformers通过优化本地...

NVIDIA和MIT的研究人员推出了一种新的视觉语言模型(VLM)预训练框架,名为VILA。这个框架旨在通过有效的嵌入对齐和动态神经网络架构,改进语言模型的视觉和文本的学习能力。VILA通过在大规模数据集如Coy0-700m上进行预训练,采用基于LLaVA模型的不同预训练策略...
AI视频生成赛道风起云涌,国内外新颖的文生、图生视频产品层出不穷。在各大厂商的内卷之下,当下的视频生成模型各方面已经接近以假乱真的效果。例如,OpenAI 的 Sora 和国内的 Vidu、可灵等模型,通过利用 Diffusion Transformer 的扩展特性,不仅能...
在视频中插入手绘动画!传统上这是一项非常困难的任务,但 VideoDoodles 让它成为可能。VideoDoodles是Adobe公司联合多所大学推出的AI视频编辑框架。支持用户在视频中轻松插入手绘动画,实现与视频内容的无缝融合。通过预处理视频帧,系统提供平面画布,用户...
近期,快手平台又又又成为了焦点。就在OpenAI 当家花旦 Sora 的公测还遥遥无期时,快手就率先祭出了对标的当家产品可灵。得益于其逼真、高清和与Sora不相上下的视觉表现,它迅速赢得了全球网民的喜爱。据快手,可灵申请用户已经近70 万,已超30 万用户使用趁...
近日,当下炙手可热的快手宣布开源旗下明星产品可灵中一项重要技术项目LivePortrait。,该框架能够准确、实时地将驱动视频的表情、姿态迁移到静态或动态人像视频上,生成极具表现力的视频结果。如下动图所示:LivePortrait的主要功能包括从单一图像生成生动动...
小模型,成为本周的AI爆点。与动辄上千亿参数的大模型相比,小模型的优势是显而易见的:它们不仅计算成本更低,训练和部署也更为便捷,可以满足计算资源受限、数据安全级别较高的各类场景。因此,在大笔投入大模型训练之余,像 OpenAI、谷歌等科技巨头也在积极...
项目介绍Code2prompt 是一个命令行工具,能将你的代码库转化为单一的大型语言模型(LLM)提示,结合源码树结构,模板定制,以及令牌计数。它旨在简化与高级上下文窗口模型如GPT或Claude的交互,助你在重写代码、查找bug、编写文档和实现新功能等方面提升效率...
继前几日推出完开源大模型Llama 3.1后,就在刚刚,Meta在 SIGGRAPH 上重磅宣布 Segment Anything Model 2 (SAM 2) 来了。在其前身的基础上,SAM 2 的诞生代表了领域内的一次重大进步 —— 为静态图像和动态视频内容提供实时、可提示的对象分割,将图像和视频...
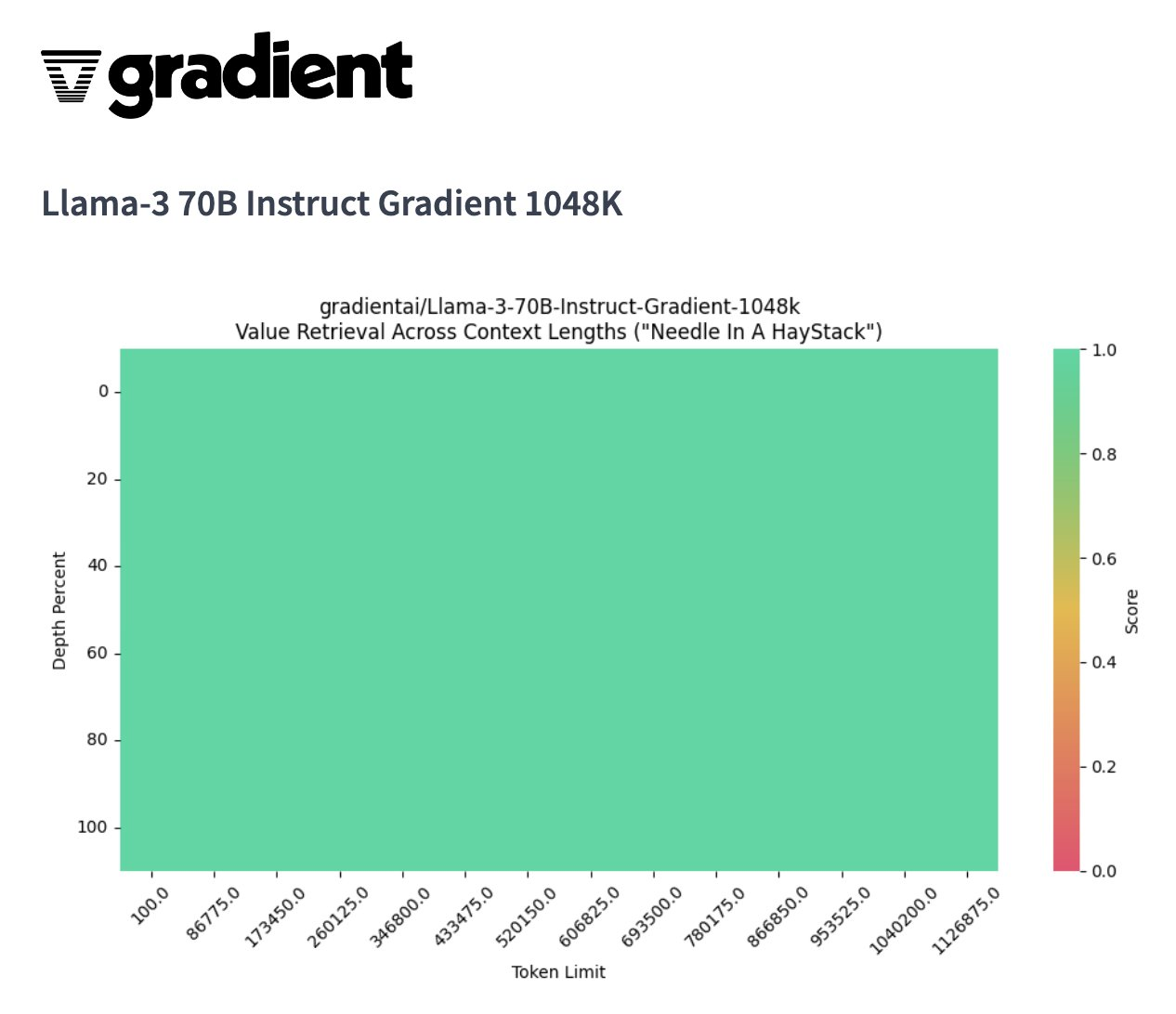
Gradient Al最近将Llama-3 8B和7B模型通过渐进式训练方法不断将Llama-3模型的上下文长度从8k-路扩展到262k、524k今天Gradient Al成功宣布成功地将Llama-3 系列模型的上下文长度扩展到超过1 M...并且1M上下文窗口 70B 模型在 NIAH(大海捞针)上取得了完美分数。...
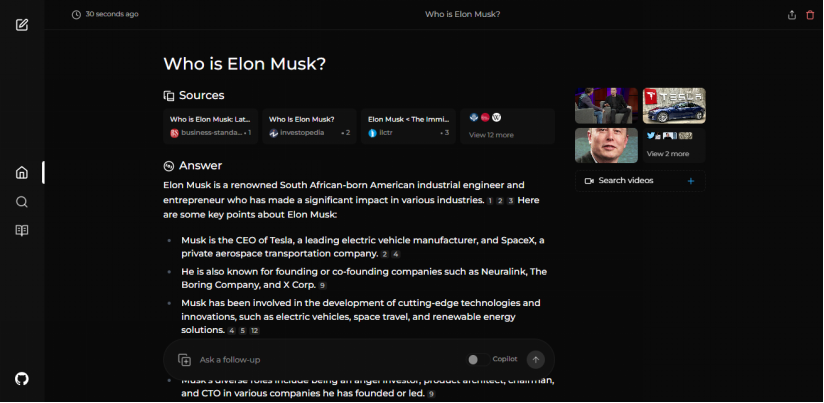
Perplexica是一个开源的人工智能搜索工具,也可以说是一款人工智能搜索引擎,它深入互联网以找到答案。受Perplexity AI启发,它是一个开源选择,不仅可以搜索网络,还能理解您的问题。它使用先进的机器学习算法,如相似性搜索和嵌入式技术,以精细化结果,并...

ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得...
一、活动亮点:全球31个节点覆盖 + 线路升级,跨境业务福音!爆款云主机0.5折起:香港、海外多节点...
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,...



 白马啸西风
白马啸西风