

智能眼镜仍然是一个尚未完全成熟的未来概念,但生成式人工智能的到来显著提升了这些设备的能力。Meta 的 Ray-Ban 智能眼镜被许多人视为当今最好的选择之一,而现在 Solos AirGo Vision 正在为其带来竞争,这款眼镜还集成了 Google Gemini 支持。尽管 Solos 不...
在谈到 AI、大模型、算力等关键词时,如果要提及硬件产品,很多人应该会不假思索的说出英伟达。的确,在全球都缺算力的环境下,英伟达的地位是独特又难以撼动的。然而就在近日,有一家公司带着自己的 AI 芯片来叫板了。昨天凌晨,科技圈迎来了一个重要新闻。...
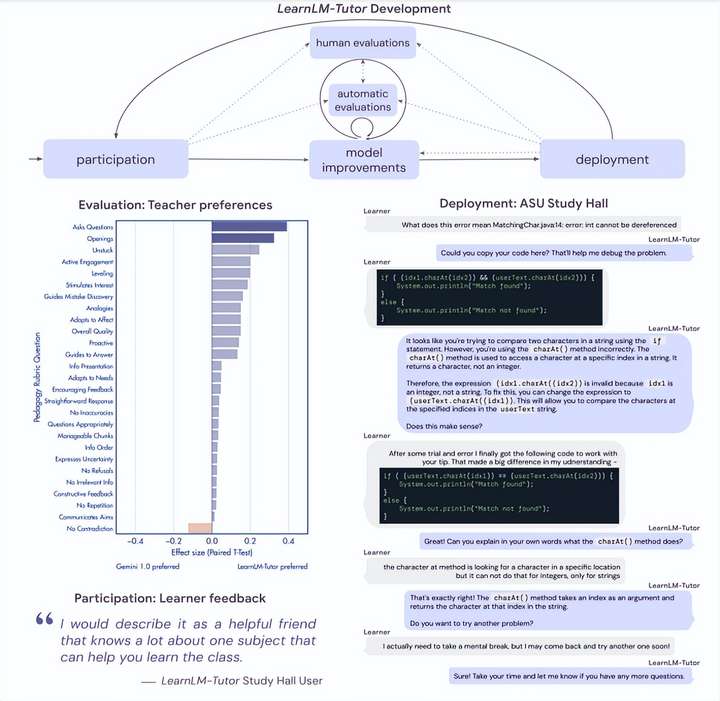
LearnLM-Tutor 是由 Google DeepMind 精心打造的 AI 教育助手,专注于一对一的教学辅导。该模型通过提供即时反馈、支持多轮对话、识别错误并给予积极反馈等手段,不仅帮助学生解决具体问题,还致力于提升他们的自学能力和批判性思维。此外,它还具备定制化学...
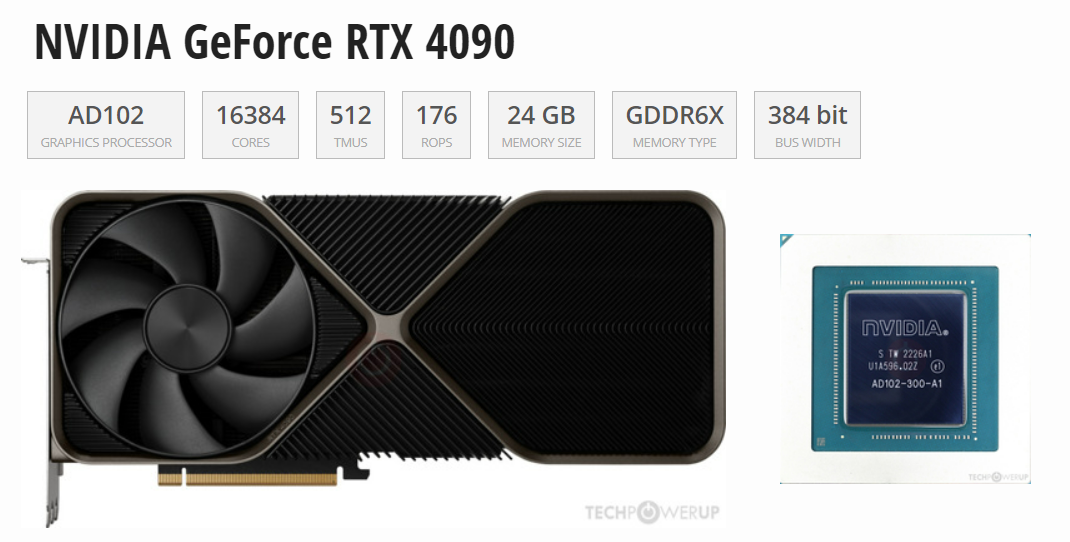
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,而是非常香!直接上图!通过Tensor FP32(TF32)的数据来看,H100性能是全方面碾压4090,但是顶不住H100价格太贵,推理上使用性价比极低。但在和A100的PK中,4090与A100除了在显...
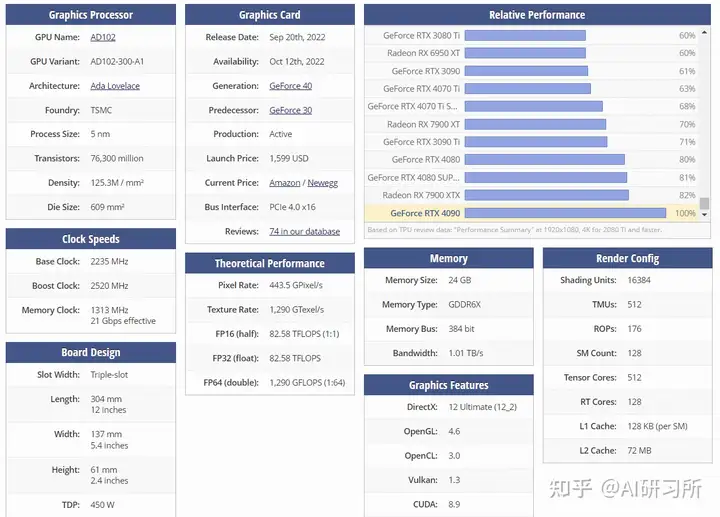
图示为GPU性能排行榜,我们可以看到所有GPU的原始相关性能图表。同时根据训练、推理能力由高到低做了排名。我们可以看到,H100 GPU的8位性能与16位性能的优化与其他GPU存在巨大差距。针对大模型训练来说,H100和A100有绝对的优势首先,从架构角度来看,A100采...
随着人工智能的持续火热,好的加速卡成为了各行业的重点关注对象,因为在AI机器学习中,通常涉及大量矩阵运算、向量运算和其他数值计算。这些计算可以通过并行处理大幅提高效率,而高端显卡的存在,使得在处理要求拥有大量算力的任务时,变得不那么难了。这篇...

ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得...
一、活动亮点:全球31个节点覆盖 + 线路升级,跨境业务福音!爆款云主机0.5折起:香港、海外多节点...
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,...

 社区管理员
社区管理员 白马啸西风
白马啸西风