

2023年12月28日 英伟达宣布正式发布GeForce RTX 4090D,对比于一年前上市的4090芯片,两者的区别与差异在哪?而在当前比较火热的大模型推理、AI绘画场景方面 两者各自的表现又如何呢?规格与参数信息对比现在先来看看GeForce RTX 4090D到底与之前的GeForce RT...

在人工智能领域,自然语言处理技术一直备受关注。就在昨日,今年备受关注的国内AI公司北京智谱AI发布了第四代 GLM 系列开源模型:GLM-4-9B。这是一个集成了先进自然语言处理技术的创新平台,它凭借清华大学KEG实验室提出的GLM模型结构,为智能体功能的发展带来...

TikTok最近推出了一款极具实用性的新工具包——TikTok Symphony。它融合了生成式人工智能技术,让内容创作变得更加迅速和便捷。无论是营销人员还是创作者,都能在TikTok上轻松制作出高质量的内容。Symphony将人类的创造力与AI的高效性完美融合,为不同规模的...
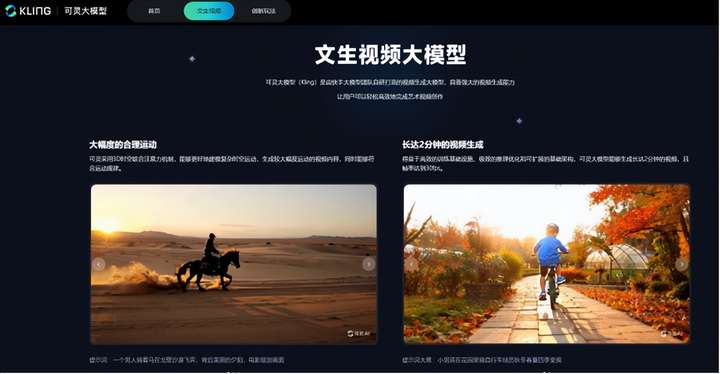
自从OpenAI公布了Sora后,震爆了全世界,但由于其技术的不成熟和应用的局限性,未能大规模推广,只有零零散散的几个公布出来的一些视频。昨日,快手成立13周年,可灵(Kling)大模型发布,体验后不由得感叹,炸裂,太震撼了,快手可灵,除了那个没发布的Sora...

一直在生成式AI战争中默默无闻的苹果终于憋不住了!北京时间6月11日凌晨1点,2024苹果WWDC全球开发者大会在苹果总部 Apple Park开幕。Day 1的发布会在介绍完各个操作系统的更新后,一半的时间都留给了本次WWDC的重头戏——苹果AI(Apple Intelligence)。Appl...
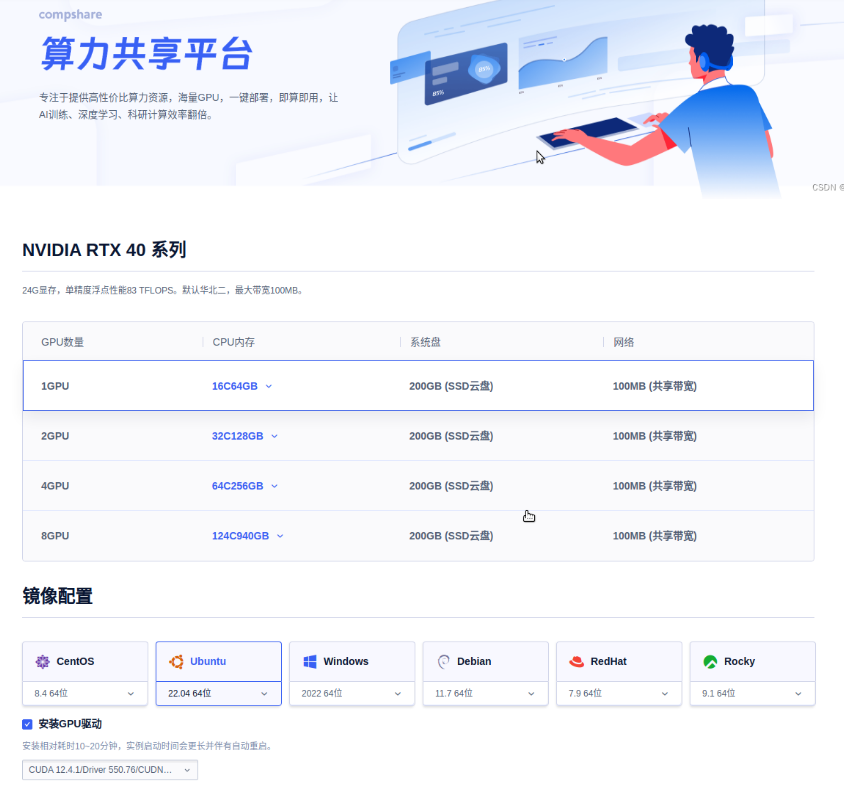
【compshare】推荐一个GPU按小时租的平台,使用实体机部署,可以方便快速的部署xinf推理框架并提供web展示,部署qwen大模型,特别方便UCloud(优刻得)是中国知名的中立云计算服务商,科创板上市(股票代码:688158),中国云计算第一股,专注于提供可靠的企业级...
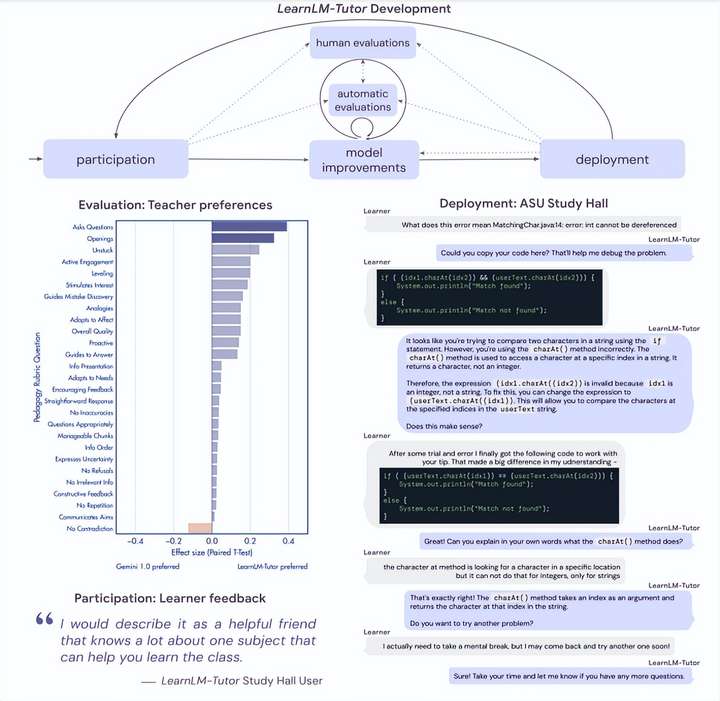
LearnLM-Tutor 是由 Google DeepMind 精心打造的 AI 教育助手,专注于一对一的教学辅导。该模型通过提供即时反馈、支持多轮对话、识别错误并给予积极反馈等手段,不仅帮助学生解决具体问题,还致力于提升他们的自学能力和批判性思维。此外,它还具备定制化学...

再见,Photoshop!Canva Create 正式上线,太疯狂了!!Canva是一款著名的免费在线AI图像生成器构想你的创意,然后将其添加到你的设计中。使用最佳的AI图像生成器,观察你的文字和短语变换成美丽的图像。用一个适合你项目的完美图像脱颖而出。以下是今天发布...
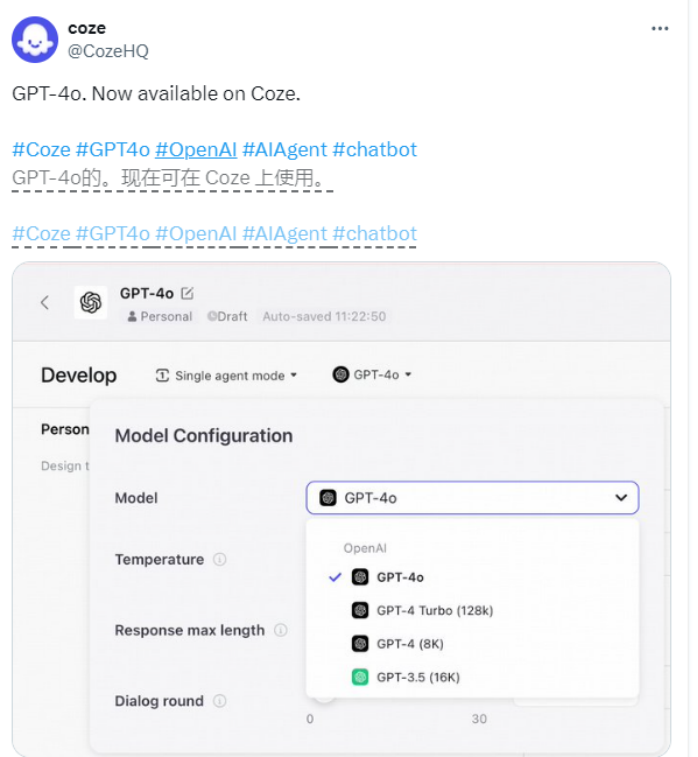
Coze 官方宣布,他们已经成功集成了 OpenAI 推出的最新AI 助手 GPT-4o,为用户带来了更智能、更强大的聊天体验。GPT-4o 是 OpenAI 的力作,它的加入将为 Coze 用户提供更便捷、更高效的沟通和交流方式。这里演示创建一个Google Web Search和DALLE 3插件的的聊...
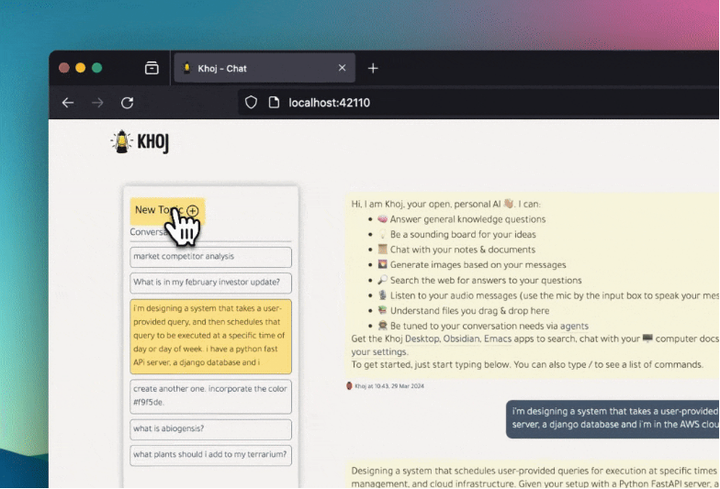
项目简介Khoj是一个开源的、个人化的AI助手,旨在充当你的第二大脑。它能够帮助你回答任何问题,不论这些问题是在线上的还是在你自己的笔记中。Khoi 支持使用在线AI模型(例如 GPT-4)或私有、本地的语言模型(例如 Llama3)。你可以选择自托管 Khoj,也可以使用...

据 Perplexity AI 表示,他们为旗下搜索引擎推出名为 Pages 的全新 AI功能,可根据搜索结果生成一份内容详尽的报告。Pages 可以帮助用户将搜索结果根据不同的受众类型生成内容细节度不同的报告或者指南。它还可以根据某个副标题来增加内容。Perplexity 还可以...
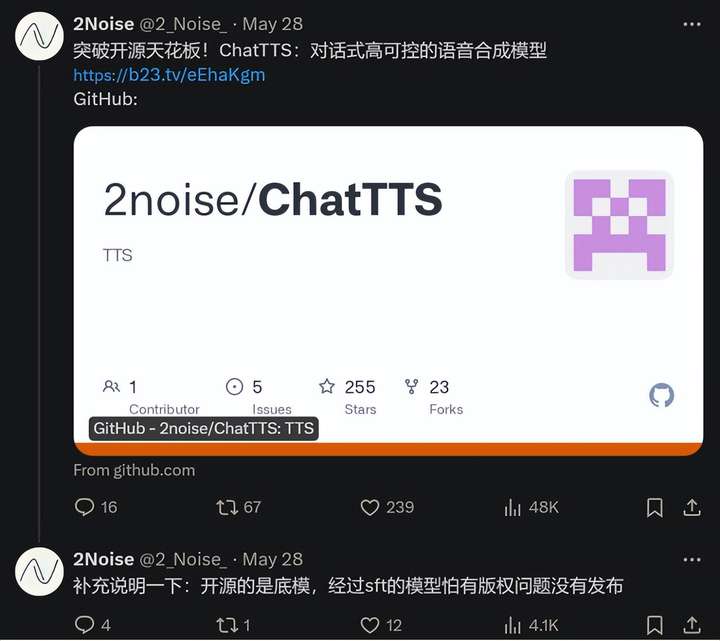
过去我们让AI说话,它给出的总是不咸不淡的机器合成声音,毫无波澜的死板音调让人听得昏昏欲睡。但由于chatTTS的到来,一切都将会变得不一样。作为一款强大的对话式文本转语音模型,它完美解决了用户对于生动对话的需求。如此功能不可小觑,可以称得上在业界...

Compshare是一个专注于提供高性价比算力资源的平台,它为AI训练、深度学习、科研计算等场景提供强大的支持。平台的核心优势在于其高效的GPU算力资源,用户可以根据自己的需求,灵活选择不同的GPU配置,实现一键部署和即算即用,从而显著提升工作效率。100% GP...
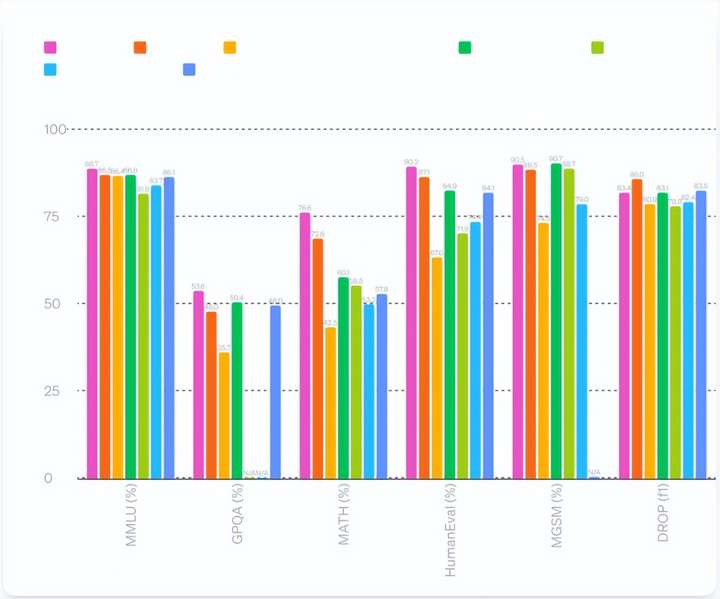
本文梳理了OpenAI团队最新的GPT-4.o(o代表omni 全方位)模型发布内容,以OpenAI团队发布会口吻整理。我们很高兴地宣布,推出了全新的旗舰模型 GPT-4o,能够在音频、视觉和文本之间实时进行推理。GPT-4o(o代表omni 全方位)能够实时处理音频...

项目简介AniTalker是一个开源项目,它利用静态照片和音频文件来创造动态的面部说话视频。AniTalker采用了一种通用的运动表示方法。这种创新的表示方法有效地捕捉了广泛的面部动态,包括微妙的表情和头部动作。AniTalker通过两种自监督学习策略增强了运动描述...

Veo是什么Veo是由Google DeepMind开发的一款视频生成模型,用户可以通过文本、图像或视频提示来指导其生成所需的视频内容,能够生成时长超过一分钟1080P分辨率的高质量视频。Veo拥有对自然语言的深入理解能够准确捕捉和执行各种电影制作术语和效果,如延时摄...

5月20日,微软在其特别活动上,向世界介绍了一种新类别的WindowsPC,一款专为AI设计的Copilot+ PC。Copilot+ PC引入了全新的系统架构,将 CPU、GPU和高性能神经处理单元(NPU)结合在一起,并与 Azure 云中的大语言模型(LLM)和小语言模型(SLM)协同工作,带来前...
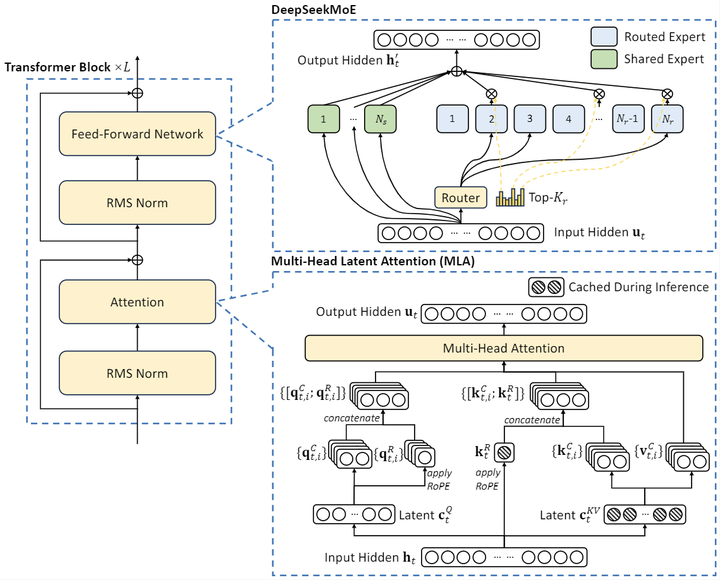
项目简介DeepSeek-V2,一个专家混合(MoE)语言模型,其特点是经济高效的训练和推理。它包含 2360 亿个总参数,其中每个token激活了21亿个参数。与 DeepSeek67B相比,DeepSeek-V2 实现了更强的性能,同时节省了 42.5%的训练成本,将 KV 缓存减少了 93.3%,并将...

Llama3 中文聊天项目综合资源库,该文档集合了与Lama3 模型相关的各种中文资料,包括微调版本、有趣的权重、训练、推理、评测和部署的教程视频与文档。1. 多版本支持与创新:该仓库提供了多个版本的Lama3 模型,包括基于不同技术和偏好的微调版本,如直接中文...
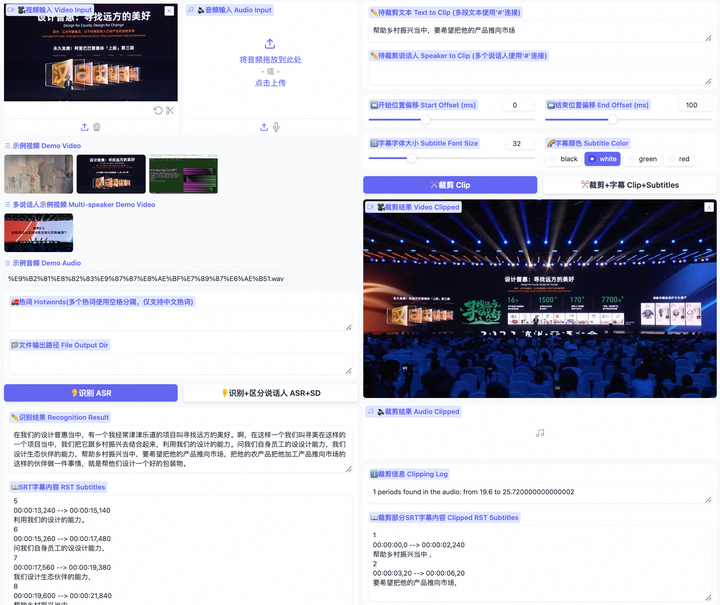
项目简介Funclip 是阿里巴巴通义实验室开源的一款视频剪辑工具,专门用于精准、便捷的视频切片。它能够自动识别视频中的中文语音并允许用户根据语音内容来裁剪视频。该工具使用了阿里巴巴语音识别模型FunASR Paraformer-Large确保了剪辑的精准性。你可以根据...

ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得廉价算力,进行AI视频生成等模型开发和应用呢?Compshare是隶属于UCloud云计算的GPU算力平台,专注提供高性价比的NVIDIA RTX 40 系列资源,满足 AI应用、模型推理/微...
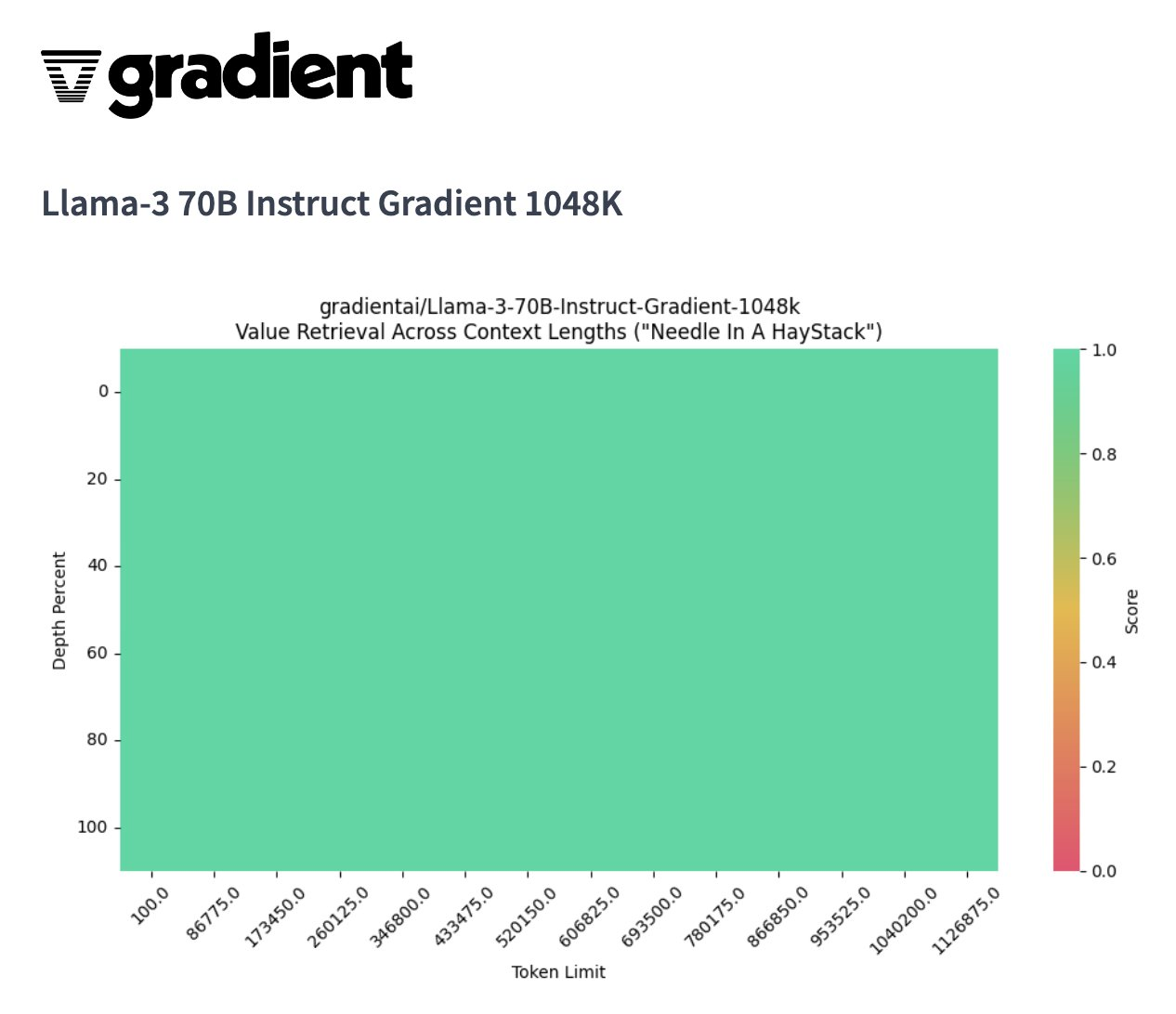
Gradient Al最近将Llama-3 8B和7B模型通过渐进式训练方法不断将Llama-3模型的上下文长度从8k-路扩展到262k、524k今天Gradient Al成功宣布成功地将Llama-3 系列模型的上下文长度扩展到超过1 M...并且1M上下文窗口 70B 模型在 NIAH(大海捞针)上取得了完美分数。...

NVIDIA和MIT的研究人员推出了一种新的视觉语言模型(VLM)预训练框架,名为VILA。这个框架旨在通过有效的嵌入对齐和动态神经网络架构,改进语言模型的视觉和文本的学习能力。VILA通过在大规模数据集如Coy0-700m上进行预训练,采用基于LLaVA模型的不同预训练策略...
NVIDIA和MIT的研究人员推出了一种新的视觉语言模型(VLM)预训练框架,名为VILA。这个框架旨在通过有效的嵌入对齐和动态神经网络架构,改进语言模型的视觉和文本的学习能力。VILA通过在大规模数据集如Coy0-700m上进行预训练,采用基于LLaVA模型的不同预训练策略...
ollama介绍在本地启动并运行大型语言模型。运行Llama 3、Phi 3、Mistral、Gemma和其他型号。Llama 3Meta Llama 3 是 Meta Inc. 开发的一系列最先进的模型,提供8B和70B参数大小(预训练或指令调整)。Llama 3 指令调整模型针对对话/聊天用例进行了微调和优化...

ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得...
一、活动亮点:全球31个节点覆盖 + 线路升级,跨境业务福音!爆款云主机0.5折起:香港、海外多节点...
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,...

 社区管理员
社区管理员 白马啸西风
白马啸西风