
摘要:一直以来,我的计算器都是的之后偶尔也用。因为我们要使用高精度数来代替浮点数,所以的真正实现,交给了。我们通常使用计算器的函数都是形如这样的形式,所以我们定义函数的正则为表示参数可以有也可以没有,即存在这样的函数。
一直以来,我的计算器都是 Python 的 REPL(Java8 之后偶尔也用 jjs (Nashorn))。但是这些 REPL 的问题在于,在涉及到小数时,它们使用的是浮点数进行运算,于是不可避免的出现了浮点数精度缺失的问题:
这个问题,忍得太久,今天又遇到了 —— 所以才会有这样一个想法:自己做一个命令行下的计算器,使用高精度数来代替浮点数进行运算,从而解决掉浮点数精度缺失的问题。
要做一个计算器,首先需要能对一个输入的表达式进行解析,获得这个表达式中包含的所有标识(Token):比如 数,运算符,括号 等,当然最好还能够自定义函数,比如 log,pow,sin 等。(在编译原理中,这个过程叫 词法分析)
所以,我们先来定义表示这些 Token 的类。首先定义 数、运算符、括号、函数 这些 Token 的接口,就命名为 Token:
public interface Token {
public TokenType getType();
public String text();
public boolean isNumber();
public boolean isOperator();
public boolean isBracket();
public boolean isFunction();
}
getType() 方法用来返回一个 TokenType 类型,TokenType 是一个枚举,它包括了以下四个种类:
public enum TokenType {
/**
* 数
*/
NUMBER,
/**
* 运算符
*/
OPERATOR,
/**
* 括号
*/
BRACKET,
/**
* 函数
*/
FUNCTION
}
为了避免 Token 的每个实现类都需要实现 Token 的每一个方法,我们先定义一个 AbstractToken 类,对每个 isXXX 方法都进行实现 —— 通过 getType 方法来判断是否是该 Token 对应的 TokenType。然后让 Token 的真正实现类去覆写 getType 方法,并返回其对应的 TokenType。比如对于 数,那么 getType 返回 TokenType.NUMBER,那么在该类上调用 isNumber 方法,便会返回 true,而其他 isXXX 方法都会返回 false。
public abstract class AbstractToken implements Token {
@Override
public boolean isNumber() {
return getType() == TokenType.NUMBER;
}
@Override
public boolean isOperator() {
return getType() == TokenType.OPERATOR;
}
@Override
public boolean isBracket() {
return getType() == TokenType.BRACKET;
}
@Override
public boolean isFunction() {
return getType() == TokenType.FUNCTION;
}
}
然后按照每种 Token 的需求挨个实现 Token 接口。因为 Java 中已经存在了一个 Number 类,而且位于 java.lang 包下,所以为了避免混淆,我将 数 类的名称定义为 Num。
public class Num extends AbstractToken implements Token {
private final BigDecimal value;
public Num(BigDecimal value) {
this.value = value;
}
public Num(String value) {
this.value = new BigDecimal(value);
}
public BigDecimal value() {
return value;
}
@Override
public TokenType getType() {
return TokenType.NUMBER;
}
@Override
public String text() {
return String.valueOf(value);
}
}
因为我们要使用高精度数来代替浮点数,所以 Num 的真正实现,交给了 BigDecimal。
运算符 类:
public class Operator extends AbstractToken implements Token {
private final char value;
public Operator(char value) {
if (value == "+" || value == "-" || value == "*" || value == "/") {
this.value = value;
} else {
throw new RuntimeException(String.format("未知的运算符:%c", value));
}
}
/**
* 获得运算符的优先级
*
* @return 运算符的优先级
*/
public int property() {
switch (value) {
case "*":
case "/":
return 1;
default:
return 0;
}
}
/**
* 该运算符的优先级是否大于所给的运算符的优先级
*
* @param other 所给的运算符
* @return 如果该运算符的优先级是否大于所给的运算符的优先级,返回 true,否则返回 false
*/
public boolean isHigherThan(Operator other) {
return this.property() > other.property();
}
@Override
public TokenType getType() {
return TokenType.OPERATOR;
}
@Override
public String text() {
return String.valueOf(value);
}
}
运算符 应该具有优先级,所以我们定义了 isHigherThan(Operator other) 方法来判断当前运算符对象(this) 的优先级是否大于给定运算符对象(other)。
括号 类:
public class Bracket extends AbstractToken implements Token {
public static final char CHAR_LEFT_BRACKET = "(";
public static final char CHAR_RIGHT_BRACKET = ")";
private final char value;
public Bracket(char value) {
if (value == CHAR_LEFT_BRACKET || value == CHAR_RIGHT_BRACKET) {
this.value = value;
} else {
throw new RuntimeException("未知的括号字符:" + value);
}
}
public boolean isLeft() {
return value == CHAR_LEFT_BRACKET;
}
public boolean isRight() {
return value == CHAR_RIGHT_BRACKET;
}
@Override
public TokenType getType() {
return TokenType.BRACKET;
}
@Override
public String text() {
return String.valueOf(value);
}
}
括号 类定义了 isLeft 和 isRight 方法,分别用来判断该括号是左括号还是右括号。
而函数类的定义比上面这些更加复杂一些,我们稍后再给出。
Token 的类都定义完毕之后,我们便可以开始实现表达式的解析了 —— 即将一个表达式转换为多个 Token。此时,我们需要定义能够匹配各种 Token 的正则表达式。
我们先来看 数 对应的正则。数 包括整数和小数,整数的正则:d+,d 表示匹配数字,+ 表示至少需要一位数字;小数的正则:d*.d+,d* 表示小数点前面可以有 0 个或者或多个数字,即 12.3 和 .3 都表示一个小数,而 .3 在一般的编程语言中都默认为 0.3。所以匹配数字的正则为 d*.d+|d+(请大家思考下为什么要将小数的正则放到前面)。
然后,操作符 对应的正则。我们的操作符包括了 +、-、*、/,所以对应的正则为 +|-|*|/ ( + 和 * 需要转义)。
括号的正则:(|) —— 括号也需要转义。
最后是 函数 的正则。我们通常使用计算器的函数都是形如 function_name(param1, param2) 这样的形式,所以我们定义函数的正则为 [A-Za-z]+(.*) —— .* 表示参数可以有也可以没有,即存在 function_name() 这样的函数。
所以给出匹配 Token 的正则表达式为:(d*.d+|d+)|(+|-|*|/)|((|))|[A-Za-z]+(.*) —— 为了解析时将 Token 进行区分,我们将每种 Token 的正则都用括号包括,这样的话每种 Token 在正则做提取时就会作为不同的 group,从而在提取时每种 Token 可以被区分。
因为输入表达式的时候, Token 之间难免会存在空格,所以我们需要加入对空格的处理 —— s* 表示匹配一个或者多个空格 —— 加入空格处理后的正则表达式变为:s*((d*.d+|d+)|(+|-|*|/)|((|))|[A-Za-z]+(.*))s*,即 s*(Token 的正则)s*。
此时我们可以给出 Token 中 函数 类的定义,与简写的 Num 对应,将函数类别的 Token 命名为 Func:
public class Func extends AbstractToken implements Token {
private static final Num[] PARAMS_NONE = new Num[0];
private final String name; // 名字
private final Num[] params; // 参数
public Func(String content) {
int indexOfLeftBracket = content.indexOf("(");
int indexOfRightBracket = content.lastIndexOf(")");
name = content.substring(0, indexOfLeftBracket);
String paramsContent = content.substring(
indexOfLeftBracket + 1, indexOfRightBracket);
// 提取出各个参数
String[] paramStrs = paramsContent.split(",");
if (paramStrs.length == 1 && paramStrs[0].isEmpty()) { // 没有参数
params = PARAMS_NONE;
} else { // 有参数
params = new Num[paramStrs.length];
for (int i = 0; i < params.length; i++) {
String paramStr = paramStrs[i].trim();
// 如果需要参数也能是表达式,修改这个地方
// 先计算出表达式的值(Num),然后将其作为参数
params[i] = new Num(paramStr);
}
}
}
/**
* 获得函数的结果
*
* @return 函数的结果
*/
public Num getResult() {
Function function = FunctionFactory.getFunction(name);
if (function != null) {
return function.apply(params);
}
throw new UnknownFunctionException(name);
}
}
可以看到 Func 类中定义了 getResult 方法 —— 用来获得函数的结果。该方法首先调用 FunctionFactory 的 getFunction 方法,通过函数名获得一个具体的 Function,然后 Function 的 apply 方法可以根据参数求得函数的值。具体代码就是我将 Function 定义为接口:
public interface Function {
public Num apply(Num[] params);
}
然后通过 FunctionFactory 的 getFunction 方法返回不同的 Function 的实现:
public final class FunctionFactory {
public static Function getFunction(String name) {
Objects.requireNonNull(name);
name = name.toLowerCase();
switch (name) {
case "pi":
return new PIFunction();
case "log":
return new LogFunction();
case "pow":
return new PowFunction();
}
return null;
}
}
这样一来,每次添加一个 函数,只需要写一个对应的 Function 接口的实现,然后将其名称加入到FunctionFactory 中就行 —— 使用的是 简单工厂模式。
正则定义完毕之后,便可以使用该正则来解析表达式,我们定义一个表达式类 Expression:
public class Expression {
private static final String REG_EXPR = "s*((d*.d+|d+)|(+|-|*|/)|((|))|([A-Za-z]+(.*)))s*";
private static final Pattern PATTERN = Pattern.compile(REG_EXPR);
private final List tokens; // 该表达式中的所有 Token
public Expression(List tokens) {
this.tokens = tokens;
}
public Expression(String expr) {
this.tokens = parseTokens(expr);
}
...
}
(因为在 Java 中, 在字符串中需要用 表示,所以 REG_EXPR 代表的正则都使用了 来表示 )
现在,我们需要一个方法,这个方法可以将字符串形式的表达式,解析为多个 Token,我们定义这个方法为 parseTokens:
private ListparseTokens(String expr) { List ts = new ArrayList<>(); Matcher matcher = PATTERN.matcher(expr); int start = 0, end = expr.length(); while (start < end) { // 设定正则的查找范围在 [start, end),不包括 end matcher.region(start, end); // lookingAt() 方法会从 start 位置开始匹配下一个满足正则的子串 // 我也不知道当年 Java 的开发人员为什么会取 lookingAt 这么鬼畜的名字 if (matcher.lookingAt()) { // 如果找到了一个匹配正则的子串 Token token = getToken(matcher); ts.add(token); start = matcher.end(); // end() 方法会返回上一次匹配的子串的末尾的位置 } else { // 没有找到匹配正则的子串,说明表达式包含了非正则中定义的文本 String errorExpr = expr.substring(start); throw new RuntimeException("错误的表达式:" + errorExpr); } } return ts; } private Token getToken(Matcher matcher) { // matcher.group(1) 匹配最外层的括号(matcher.group(0) 是匹配整个正则) String m = matcher.group(1); if (m != null) { if (matcher.group(2) != null) { // 数 return new Num(matcher.group(2)); } else if (matcher.group(3) != null) { // 运算符 char operatorValue = matcher.group(3).charAt(0); return new Operator(operatorValue); } else if (matcher.group(4) != null) { // 括号 char bracketValue = matcher.group(4).charAt(0); return new Bracket(bracketValue); } else { // 函数 Function function = new Function(matcher.group(5)); Num num = function.getResult(); return num; } } throw new RuntimeException("Expression.getToken: Unbelievable"); // 正则无误的情况下不会发生 }
parseTokens 方法的过程就是使用 Matcher 类扫描表达式(输入的字符串),每次提取出一个 Token,并加入到集合中,直到扫描完毕。getToken 方法中,对于函数,我们先求出函数的结果(Num),然后便可以直接将其作为一个 Token。
我们顺便覆写下 Expression 的 toString 方法,然后对 Expression 写几个示例测试一下。为了方便展示此处直接使用 main 方法,不使用 JUnit 这样的工具:
@Override
public String toString() {
StringBuilder expr = new StringBuilder();
for (Token token : tokens) {
expr.append(token.text()).append(" ");
}
expr.deleteCharAt(expr.length() - 1);
return expr.toString();
}
main 函数:
public static void main(String[] args) throws Exception {
Expression expr = new Expression("1+2*3");
System.out.println(expr);
expr = new Expression("(1+2) * 3");
System.out.println(expr);
expr = new Expression("0.65- 0.56");
System.out.println(expr);
expr = new Expression("6 # 8");
}
运行结果:
可见我们已经能够成功的解析表达式,并将其转化为多个 Token —— 下一篇 文章将讲解如何计算表达式的值(完整的源码在 GitHub)。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/70274.html
摘要:而对于前缀表达式和后缀表达式的计算,则十分的简单。由上一篇文章可知,我们目前的类所表示的,就是中缀表达式,所以我们需要提供算法,将中缀表达式转换为前缀表达式或者后缀表达式,从而方便我们计算表达式的值。 上一篇 文章讲了如何通过正则来将输入的表达式解析为多个 Token,而这篇文章的核心在于如何对 表达式求值。我们输入的表达式,即我们通常见到的表达式,都是中缀表达式 —— 中缀的含义是,...
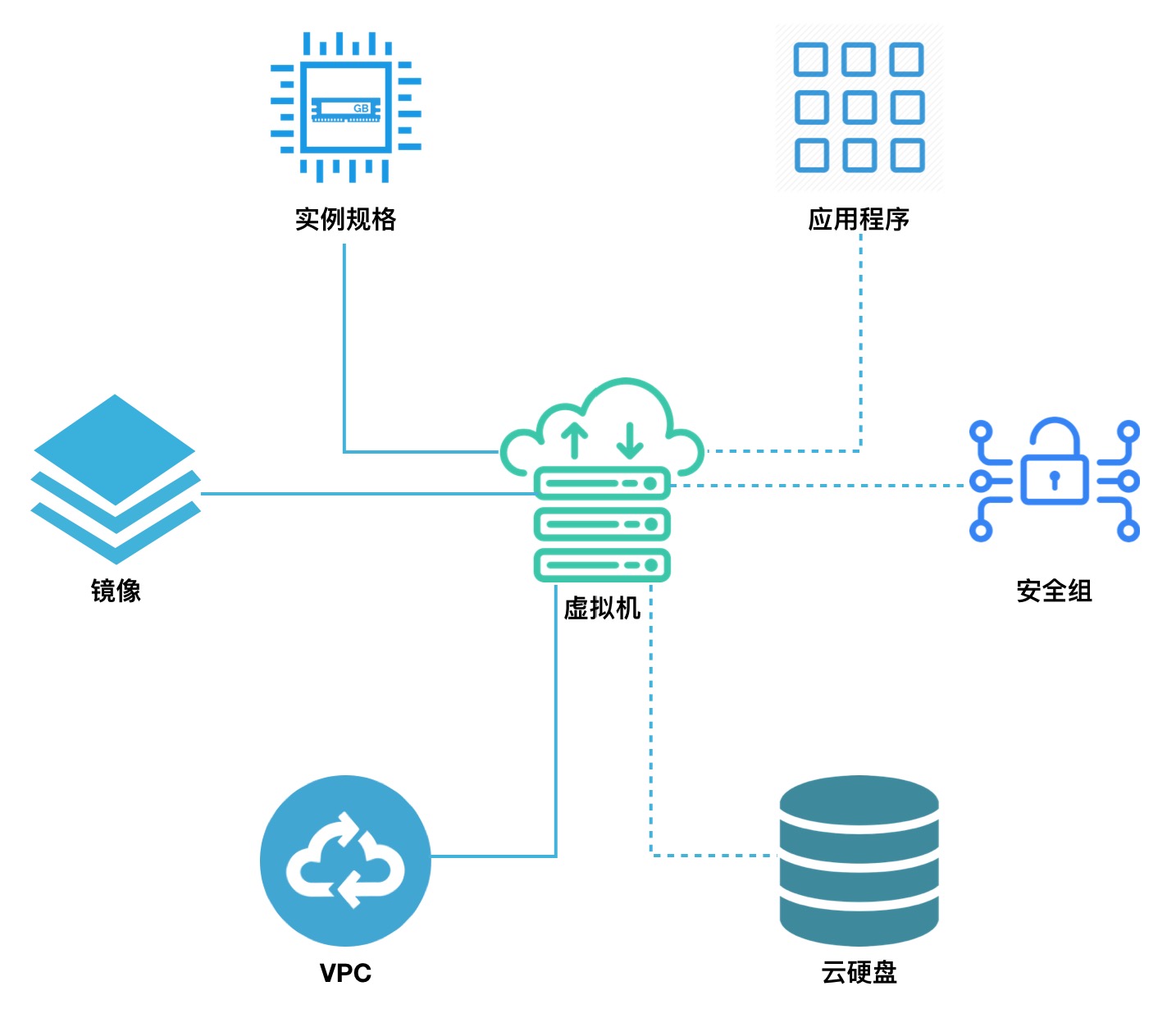
摘要:虚拟网卡与虚拟机的生命周期一致,无法进行分离,虚拟机被销毁时,虚拟网卡即被销毁。每块虚拟网卡支持绑定一个安全组,提供网卡级别安全控制。平台默认提供块虚拟网卡,若业务有块以上网卡需求可通过绑定弹性网卡,为虚拟机提供多网络服务。虚拟机是 UCloudStack 云平台的核心服务,提供可随时扩展的计算能力服务,包括 CPU 、内存、操作系统等最基础的计算组件,并与网络、磁盘等服务结合提供完整的计算...
摘要:的官方网址为,其使用手册网址为本次分享将实现的功能为利用爬取某个搜索词语暂仅限英文的百度百科的介绍部分,具体的功能介绍可以参考博客爬虫自制简单的搜索引擎。 Jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。Jsoup的官方网址为: https:...
摘要:坑一慎用方法在类中,有一个方法是,返回的是一个数组,该数组包含了所包含的方法。坑二慎用线程优先级做并发处理线程中有属性,表示线程的优先级,默认值为,取值区间为。显然,运行时环境是因操作系统而异的。 本文为作者原创,转载请注明出处。 我们都知道Java是跨平台的,一次编译,到处运行,本质上依赖于不同操作系统下有不同的JVM。到处运行是做到了,但运行结果呢?一样的程序,在不同的JVM上跑的...
摘要:为了解决人们因工作出差旅游等短期时间内家中宠物无人照顾的问题,我们基于物联网开发板机智云平台和各类传感器模块研究设计了一套针对短期内宠物无人照顾的智能宠物屋系统。 正式介绍作品前先说明一下,我是湖南文理学院计算机与电气工程学院的一名大三学生,我叫陈海涛。作品全部内容均为个人创意、个人设计并手...

阅读 2109·2021-11-24 09:39
阅读 862·2021-09-30 09:48
阅读 1064·2021-09-22 15:29
阅读 2482·2019-08-30 14:17
阅读 1934·2019-08-30 13:50
阅读 1418·2019-08-30 13:47
阅读 1039·2019-08-30 13:19
阅读 3464·2019-08-29 16:43






