
摘要:代码如下值默认为而在新版中,方法被废除根据的官方文档中的说法中文翻译后索引时权值被废除,请将索引时打分因素添加入域中,然后在查询时,使用功能性打分查询语句,进行关联查询。
前言
学习的资料是 lucene 4.10 版本,比较沉旧,查阅最新的 lucene 版本 6.6 的官方文档,整理出以下几个使用中的不同。
从浅入深依次为 (注:不是根据版本先后)
IndexWriterConfig 的构造方法
Directory 的生成方法 FSDirectory.open()
legacyXXField 与legacyNumericRangeQuery 的废弃
BooleanQuery() 方法的改变
setBoost()方法的废除
中文分词器的改进
下面,就让我详细的整理出不同。
1.IndexWriterConfig以下是 IndexWriterConfig 4.10 的源码部分
public IndexWriterConfig(Version matchVersion, Analyzer analyzer) {
super(analyzer, matchVersion);
}
//这里的version 一般要写为
Version 类中
public static final Version LATEST;
而 IndexWriterConfig 6.6 中
//无参构造方法
public IndexWriterConfig() {
this(new StandardAnalyzer());
}
//有参构造方法
public IndexWriterConfig(Analyzer analyzer) {
super(analyzer);
this.writer = new SetOnce();
}
可以看出,在 6.6 版本中 version 不再是必要的,并且,存在无参构造方法,可以直接使用默认的 StandardAnalyzer 分词器。
2.Directory正常创建 Directory 类的方法如下
Directory di = FSdirectory.open();
以下是 IndexWriterConfig 4.10 的源码部分
public static FSDirectory open(File path) throws IOException {
return open(path, (LockFactory)null);
}
这里可以看出 open 方法 用的参数类型 为File
而 IndexWriterConfig 6.6 中
public static FSDirectory open(Path path) throws IOException {
return open(path, FSLockFactory.getDefault());
}
open 方法使用了 Path 类,这个类是 NIO 中的类,可以提高查询的效率。
由 File 转化为 Path 的 方法
--->
File file = new File (absolutePath); Path path = file.toPath()3.legacyXXField 与legacyNumericRangeQuery 1. 分析
根据 官方的 Migration Guide 中的说法
PointValues replaces NumericField (LUCENE-6917)
PointValues provides faster indexing and searching, a smaller index size, and less heap used at search time. See org.apache.lucene.index.PointValues for an introduction.
Legacy numeric encodings from previous versions of Lucene are deprecated as LegacyIntField, LegacyFloatField, LegacyLongField, and LegacyDoubleField, and can be searched with LegacyNumericRangeQuery.
以及开发者的测试
DimensionalValues seems to be better across the board (indexing time, indexing size, search-speed, search-time heap required) than NumericField, at least in my testing so far.
I think for 6.0 we should move IntField, LongField, FloatField, DoubleField and NumericRangeQuery to backward-codecs, and rename with Legacy prefix?
2.结论:3.代码对比PointValues 取代了NumericField
因为PointValues 更快,更小,更便于资源的利用。所以,所有的 legacy**都被取代了。
代码的话,lucene 的官方文档给了一个简单的例子
// add year 1970 to document
document.add(new IntPoint("year", 1970));
// index document
writer.addDocument(document);
...
// issue range query of 1960-1980
Query query = IntPoint.newRangeQuery("year", 1960, 1980);
TopDocs docs = searcher.search(query, ...);
另外我自己写了一个 已经@Deprecated的方法 与上面 进行对比
// add year 1970 to document
document.add(new IntField("year", 1970));
// index document
writer.addDocument(document);
...
// issue range query of 1960-1980
Query query = new NumericRangeQuery("year", 1960, 1980,false,false);
TopDocs docs = searcher.search(query, ...);
还要注意的是:
如果要存储,必须创建同名的StoredField类
如果要排序使用,必须同时创建同名的StoredField类与NumericDocValuesField类
例:
doc.add(new NumericDocValuesField("price",price));
doc.add(new IntPoint("price",price));
doc.add(new StoredField("price",price));
4.BooleanQuery() 的构造方法改变
1.分析
根据 官方的 Migration Guide 中的说法
PhraseQuery, MultiPhraseQuery, and BooleanQuery made immutable (LUCENE-6531 LUCENE-7064 LUCENE-6570)
也就是说, BooleanQuery这个类 一旦建立就不能再改变了。
从源码中我们可以更好的看出改变
lucene 4.10 的源码里 BooleanQuery 的类 主要方法如下
/* 构造器*/
public BooleanQuery() {
this.disableCoord = false;
}
public BooleanQuery(boolean disableCoord) {
this.disableCoord = disableCoord;
}
/*主要方法*/
public void add(BooleanClause clause) {
if(this.clauses.size() >= maxClauseCount) {
throw new BooleanQuery.TooManyClauses();
} else {
this.clauses.add(clause);
}
}
lucene 6.6 的源码里, BooleanQuery 的主要方法如下:
private BooleanQuery(boolean disableCoord, int minimumNumberShouldMatch, BooleanClause[] clauses)
可以看出 , BooleanQuery 的构造器的范围是 private 的,只能在类的内部调用。
并且最大的改变是多出了静态内部类 Builder
以下是 Builder 的部分源码
public static class Builder {
private boolean disableCoord;
private int minimumNumberShouldMatch;
private final List clauses = new ArrayList();
/* 无参构造器 */
// 相当于 BooleanQuery 的 构造器
public Builder() {
}
//相当于 BooleanQuery 的 add 方法
public BooleanQuery.Builder add(Query query, Occur occur) {
return this.add(new BooleanClause(query, occur));
}
//返回值是 BooleanQuery, 构造一个BooleanQuery 类。
public BooleanQuery build() {
return new BooleanQuery(this.disableCoord, this.minimumNumberShouldMatch, (BooleanClause[])this.clauses.toArray(new BooleanClause[0]), null);
}
}
2.结论
通过用静态内部类实例化自身的方法,加强了类自身的稳定性与安全性。避免可能发生的小意外,而导致代码出现问题的可能性
3.代码对比下面给出代码,可以更好的看出差别
//原先的 使用方法
BooleanQuery bq = new BooleanQuery();
bq.add(q1, Occur.SHOULD);
bq.add(q2, Occur.SHOULD); bq.add(q3, Occur.MUST);
//现在的 使用方法
BooleanQuery bq = new BooleanQuery.Builder()
.add(q1, Occur.SHOULD)
.add(q2, Occur.SHOULD)
.add(q3, Occur.SHOULD)
.build();
5. setBoost()方法的废除
在 lucene 4.10 包中, setBoost方法被用于 相关度 的排序中。改变创建索引时的 Boost -- 权值。根据一系列计算方法 (旧版采用的 空间向量模型算法),最终得出其打分。
代码如下 :
Field fi1 = new Field("id" , 1, STORE.YES);
// Boost 值默认为 1.0f
fi1.setBoost(100f)
Document do = new Document();
do.add(fi1);
而在新版 lucene 6.6 中, setBoost 方法被 废除
根据lucene 的官方文档中的说法
org.apache.lucene.document.Field.setBoost(float)
Index-time boosts are deprecated, please index index-time scoring factors into a doc value field and combine them with the score at query time using eg. FunctionScoreQuery.
中文翻译后:
索引时权值被废除,请将索引时打分因素添加入field域中,然后在查询时,使用功能性打分查询语句,进行关联查询。
我在查看了 大部分关联的 api 后,发现了几个与之相关的 类
BoostAttribute
termsEnum
MultiQuery
lucene 的官方文档中对 BoostAttribute 的描述是这样的。
BoostAttribute --- >
Add this Attribute to a TermsEnum returned by MultiTermQuery.getTermsEnum(Terms,AttributeSource) and update the boost on each returned term.
方法描述如下
protected abstract TermsEnum getTermsEnum(Terms terms,AttributeSource atts) //Construct the enumeration to be used, expanding the pattern term. //很明显,这是个抽象方法,必须由子类实现
BoostAttribute 是个接口,其实现类 BoostAttributeImpl 中源码如下
public BoostAttributeImpl() {
}
public void setBoost(float boost) {
this.boost = boost;
}
推测使用如下 --- 以下是伪代码
//设置 Boost 属性 BoostAttribute ba = new BoostAttributeImpl(); ba.setBoost(100f); //设置 Query 的实现类 Query query = new MultiTermqueryChildren(new Terms()); TermEnum te = query.getTermsEnum(Terms,ba);
具体方法还不清楚,希望知道的大神可以给我解答
另外,还有两个便于操作的类:
BoostQuery
MultiFieldQueryParser
1.BoostQuery源码如下:
public BoostQuery(Query query, float boost) {
this.query = (Query)Objects.requireNonNull(query);
this.boost = boost;
}
分析:
相当于一个包装类,将 Query 设置 Boost 值 ,然后包装起来。
再通过复合查询语句,可以突出 Query 的优先级。
使用如下:
//查询 索引域 中的 file_name , file_content Query q1 = new TermQuery(new Term(“file_name” ,”springmvc.txt”); Query q2 = new TermQuery(new Term(“file_content”,”springmvc.txt”); //将 q1 设置 Boost 值 BoostQuery q3 = new BoostQuery(q1,100f); //复合语句查询 BooleanQuery.Builder() builder = new new BooleanQuery.Builder(); builder.add(q3, Occur.MUST) builder.add(q2, Occur.MUST) //由于 file_name 的查询语句经过 BoostQuery 的包装 //因此 file_name 的优先级更高。 BooleanQuery query = builder.build();
2.MultiFieldQueryParser
和原先版本相同 , 就不阐述源码,直接上使用方法
使用如下 :
//设置组合查询域
String[] fields = {"file_name","file_content"};
//设置评分,文件名称中包括关键字的评分高
Map boosts = new HashMap();
boosts.put("file_name", 10.0f);
//创建查询解析器
QueryParser queryParser = new MultiFieldQueryParser(fields, new IKAnalyzer(), boosts);
//查询文件名、文件内容中包括“springmvc.txt”关键字的文档,由于设置了文件名称域的加权值高,所以名称中匹配到关键字的应该排在前边
Query query = queryParser.parse("springmvc.txt");
6. 中文分词器 -- iKAnalyzer 的 lucene 6.6 适配
请看 下篇 文章。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/67497.html
摘要:系列文章系列一快速入门系列二使用及索引文档的基本操作系列三查询及高亮入门简介地址下载地址是一个用于搜索引擎的,方便开发和诊断的可视化工具。使用作为其最低级别的搜索引擎基础。截止,上述代码所用的包皆为最新。 系列文章: Lucene系列(一)快速入门 Lucene系列(二)luke使用及索引文档的基本操作 Lucene系列(三)查询及高亮 luke入门 简介: github地址:http...
摘要:传送门搜索为将入门现在介绍如何与数据库整合。指定域的名称指定域的类型指定使用的分词器。结语因为时间有限,先介绍到这里。等下次有时间,将与的整合,以及一起进行总结。我的个人博客谢谢。 前言 上一篇已经介绍了 solr 的基本操作。传送门: 搜索为将 -- solr 入门现在介绍如何 与数据库 整合。 solr managed-scheme 文档 这个文档位于 solrhomenew_co...
摘要:将之更改为如下形式解释一下,这里的根目录是你自身的目录。分析文件,发现一段配置但是,自己太菜,分析不出原因。 前言 1、私信请在SegmentFault 传送点 https://segmentfault.com/a/1190000010959342,有问必答2、转发请注明出处 http://3dot141.cn/blogs/29869.html,也给小可爱一点出名的机会嘛 一、版本介绍...
摘要:系列文章系列一快速入门系列二使用及索引文档的基本操作系列三查询及高亮是什么在维基百科的定义是一套用于全文检索和搜索的开放源代码程序库,由软件基金会支持和提供。全面准确和快速是衡量全文检索系统的关键指标。结果列表有相关度排序。 系列文章: Lucene系列(一)快速入门 Lucene系列(二)luke使用及索引文档的基本操作 Lucene系列(三)查询及高亮 Lucene是什么? Luc...
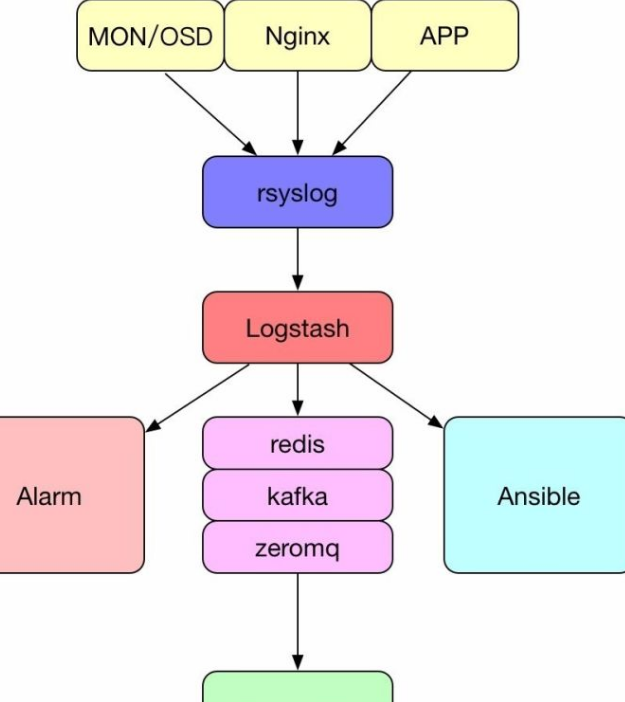
CDH Logstash是Cloudera Hadoop的一部分,是一个开源数据处理管道,可用于收集、解析、转换和传输各种数据。它具有许多内置的插件,可用于访问各种数据源(例如文件、数据库、消息队列等),并将数据转换为指定格式后发送到其他地方(例如数据库、搜索引擎、分析平台等)。 Logstash的工作流程包括三个主要部分:输入、过滤和输出。输入插件用于收集数据,过滤插件用于解析和转换数据,...

阅读 3444·2021-09-22 15:17
阅读 2805·2021-09-02 15:15
阅读 1825·2019-08-30 15:54
阅读 2025·2019-08-30 14:02
阅读 2556·2019-08-29 16:58
阅读 3013·2019-08-29 16:08
阅读 1371·2019-08-26 12:24
阅读 1681·2019-08-26 10:41






