
摘要:人群计数有什么用让我们用一个例子来理解人群计数的有用性。基于的方法我们不用看图像的补丁,而是使用可靠的卷积神经网络构建一个端到端的回归方法。这将整个图像作为输入,并直接生成人群计数。
人脸识别或人脸签到往往是1:1,或1:N的图像识别技术,但如何数人数,少量只要能识别人脸当然就可以数人数了。

但当我们面临大规模拥挤的人群,我们可能不需要识别人脸,只是人群计数,是否可以实现呢?
能帮我数数图片中这个活动有多少人参加吗?

太多了?那这个怎么样?

还是不行?没关系!
今天我们将教你创建一个基于深度学习的人群计数模型。
本文是基于卷积神经网络(CNN)的工作方式建立的,在进一步研究之前,您可以参考下面这篇文章来了解这个主题:
https://www.analyticsvidhya.com/blog/2018/12/guide-convolutional-neural-network-cnn/?utm_source=blog&utm_medium=crowd-counting
现在,我们正式开始介绍~
目录
1.什么是人群计数?
2.为什么要数人群?
3.了解不同计算机视觉技术在人群计数中的应用
4.CSRNet的体系结构与训练方法
5.用Python构建自己的人群计数模型
什么是人群计数?
人群计数是一种计算或估计图像中的人数的技术。
还是这张图——

你能告诉我这个图片里大概有多少人吗?最直接的方法是手工算,但这有实际意义吗?当人群这么多的时候,一个一个数几乎是不可能的!
人群科学家们可以通过对图片区域划分,计算图像某些部分的人数,然后外推得出估计值。这种方法是现在较为普遍的方式,但是也存在误差。几十年来,我们不得不依靠粗略的指标来估计这个数字。
“肯定有更好、更准确的方法吧?
没错,有!”
虽然我们还没有算法可以给出确切的数字,但大多数计算机视觉技术可以产生几乎完美的较精确估计。让我们先了解为什么人群计数是重要的,然后再深入研究其背后的算法。
人群计数有什么用?
让我们用一个例子来理解人群计数的有用性。想象一下,中国传媒大学刚刚举办了一个大型的数据科学会议。活动期间举行了许多不同的会议。
你被要求分析和估计每一次参加会议的人数。这将帮助我们了解什么样的会议吸引了最多的人数(以及哪些会议在这方面失败了)。并由此可以针对性塑造明年的会议,所以这是一项重要的任务!

参加会议的人数太多了,如果人工数可能将需要很久!这就是学习人群计数技能的作用所在。只要获得每一次会议中人群的照片,就可以建立了一个计算机视觉模型来完成其余的工作!
还有很多其他情况下,人群计数算法正在改变行业的运作方式:
统计参加体育赛事的人数
估计有多少人参加了就职典礼或游行(可能是政治集会)
对交通繁忙地区的监察
协助人员配置和资源分配
不同计算机视觉技术在人群计数中的应用
概括地说,目前我们可以用四种方法来计算人群中的人数:
1.基于检测的方法
我们可以使用一个移动窗口式检测器来识别图像中的人,并计算出有多少人。用于检测的方法需要训练有素的分类器来提取低层次特征。虽然这些方法在人脸检测方面效果很好,但在拥挤的图像上效果不佳,因为大多数目标对象都不是清晰可见的。
2.回归方法
对于低级别的特征,上述方法使用并不有效,可以使用基于回归的方法。我们首先从图像中裁剪补丁,然后,针对每个补丁,提取低级别的特征。
3.基于密度估计的方法
我们首先为要检测的图片创建一个密度图。然后,该算法学习了提取的特征与目标密度映射之间的线性映射。我们也可以利用随机森林回归来学习非线性映射。
4.基于CNN的方法
我们不用看图像的补丁,而是使用可靠的卷积神经网络(CNN)构建一个端到端的回归方法。这将整个图像作为输入,并直接生成人群计数。CNN在回归或分类任务中非常有效,并且在生成密度图方面也证明了它们的价值。
CSRNet是我们在本文中将实现的一种技术,它部署了一个更深层次的CNN,用于捕获高级别的特性和生成高质量的密度图,而不需要扩展网络复杂性。在讲到编码部分之前,让我们先了解一下CSRNet是什么。
了解CSRNet的体系结构和培训方法
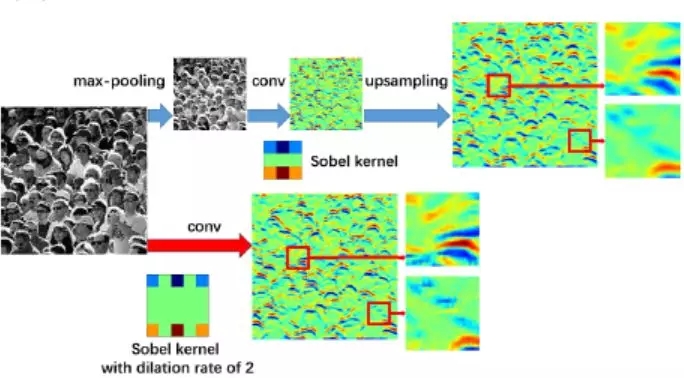
CSRNet以VGG-16为前端,具有很强的迁移学习能力.VGG的输出大小是原始输入大小的⅛。CSRNet还在后端使用膨胀的卷积层。
那么,什么是膨胀的卷积?请参考以下图像:
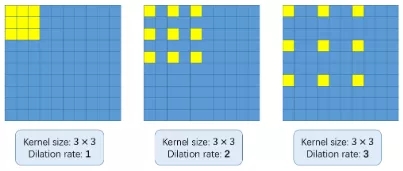
使用膨胀卷积的基本概念是在不增加参数的情况下扩大核。所以,如果膨胀率是1,我们取核并将它转到整个图像上。然而,如果我们将扩展率提高到2,内核就会像上面的图像所示的那样扩展(按照每个图像下面的标签)。它可以替代汇集图层。
基础数学(推荐,选择性了解)
我要花点时间解释一下数学是如何工作的。(请注意,在Python中实现算法并不是必须的,但我强烈建议学习基本思想。)当我们需要调整或修改模型时,这将派上用场。
假设我们有一个输入x(m,n),一个滤波器w(i,j),以及膨胀率r。输出y(m,n)为:
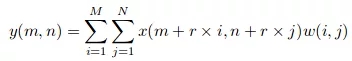
我们可以用(k*k)核推广这个方程,其扩张率为r。内核扩展到:
([K+(k-1)*(r-1)]*[k+(k-1)*(r-1)])
因此,每一幅图像都产生了地面真相。在给定的图像中,每个人的头部都是用高斯核模糊的。所有图像都被裁剪成9个补丁,每个补丁的大小是图像原始大小的1/4。
前4个补丁分为4个四分之一,其他5个补丁随机裁剪。最后,每个补丁的镜像被取为训练集的两倍。
简而言之,这就是CSRNet背后的体系结构细节。接下来,我们将查看它的培训细节,包括所使用的评估指标。
随机梯度下降用于训练CSRNet作为端到端结构。在训练期间,固定学习率设置为1e-6。损失函数被认为是欧几里德距离,以便测量地面之间的差异 真相和估计的密度图。这表示为:
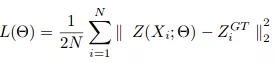
其中N是训练批次的大小。CSRNet中使用的评估标准是mae和mse。,即平均误差和均方误差。这些建议是由以下方面提供的:

在这里,Ci是估计数:
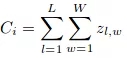
L和W是预测密度图的宽度。
我们的模型将首先预测给定图像的密度图。如果没有人在场,像素值将为0。如果某个像素对应于某个人,则将指定某个预定义的值。因此,计算一个人的总像素值会给出图像中人的数量。
那么现在,是时候建立我们自己的人群计数模型了!
建立自己的人群计数模型
我们将在上海科技数据集上实现CSRNet。这包括1198个加注释的图片,总共有330,165人。您可以从这里下载。
https://www.dropbox.com//s/fipgjqxl7uj8hd5/ShanghaiTech.zip?dl=0
使用下面的代码块克隆CSRNet-py火炬存储库。这保存了用于创建数据集、培训模型和验证结果的全部代码:
git clone https://github.com/leeyeehoo/CSRNet-pytorch.git
请先安装CUDA和PyTorch。这些是我们将在下面使用的代码背后的主干。
现在,将数据集移动到您在上面克隆的存储库并解压它。然后我们需要创建基本事实值.make_dataset.ipynbfile是我们的救星。我们只需要在该笔记本中做一些小改动:
#setting the root to the Shanghai dataset you have downloaded
# change the root path as per your location of datasetroot = "/home/pulkit/CSRNet-pytorch/"
现在,让我们为part_A和part_B中的图像生成基本真值:
生成每幅图像的密度图是一个时间步骤。所以,在代码运行时,去泡一杯咖啡吧。
到目前为止,我们已经在第A部分中为图像生成了地面真值,我们将对Part_B图像进行同样的处理。但在此之前,让我们看看一个示例图像,并绘制它的地面真实热图:
生成每张图像的密度图是一个很长的时间。所以在代码运行时去冲泡一杯咖啡吧,耐心等待一下。
到目前为止,我们已经为part_A中的图像生成了基本真值。 我们将对part_B图像执行相同的操作。但在此之前,让我们看一个示例图像并绘制其地面真实热图:
plt.imshow(Image.open(img_paths[0]))

gt_file = h5py.File(img_paths[0].replace(".jpg",".h5").replace("images","ground-truth"),"r")
groundtruth = np.asarray(gt_file["density"])
plt.imshow(groundtruth,cmap=CM.jet)
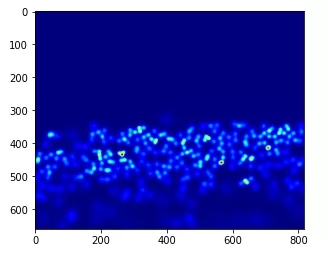
让我们数一下这张图片中有多少人在场:
np.sum(groundtruth)
270.32568
同样,我们将为part_B生成值:
我们将使用克隆目录中可用的.json文件。我们只需要更改JSON文件中图像的位置。为此,打开.json文件并将当前位置替换为图像所在的位置。
请注意,所有这些代码都是用Python 2编写的。如果您使用的是其他任何Python版本,请进行以下更改:
1.在model.py中,将第18行中的xrange更改为range
2.在model.py中更改第19行:list(self.frontend.state_dict()。items())[i] [1] .data [:] = list(mod.state_dict()。items())[i][1]。数据[:]
3.在image.py中,将ground_truth替换为ground-true
现在,打开一个新的终端窗口并键入以下命令:
cd CSRNet-pytorch
python train.py part_A_train.json part_A_val.json 0 0
这个步骤需要一些时间,耐心等一下。你也可以减少train.py文件中的纪元数量,以加快这个过程。你也可以从这里下载预先训练的重量,如果你不想等待的话。
最后,让我们检查一下我们的模型在看不见的数据上的性能。我们将使用val.ipynb文件来验证结果。记住要更改到预先训练过的权重和图像的路径。
#defining the image path
img_paths = []
for path in path_sets:
for img_path in glob.glob(os.path.join(path, "*.jpg")):
img_paths.append(img_path)
model = CSRNet()
#defining the model
model = model.cuda()
#loading the trained weights
checkpoint = torch.load("part_A/0model_best.pth.tar")
model.load_state_dict(checkpoint["state_dict"])
检查测试图像上的MAE(平均误差),以评估我们的模型:
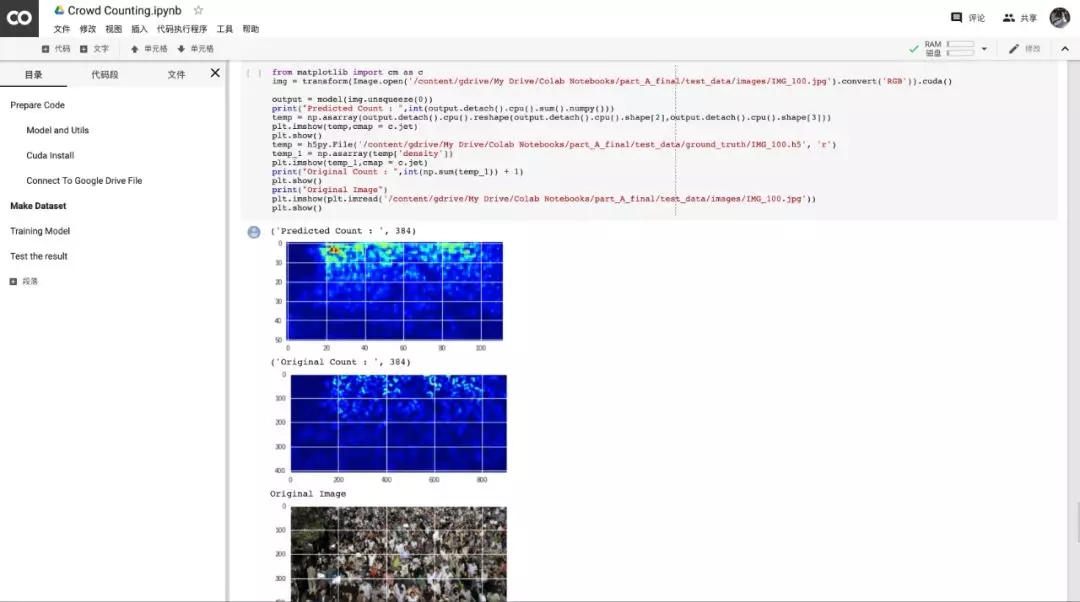
我们得到的MAE值为75.69,相当不错。现在让我们检查一下单个图像上的预测:
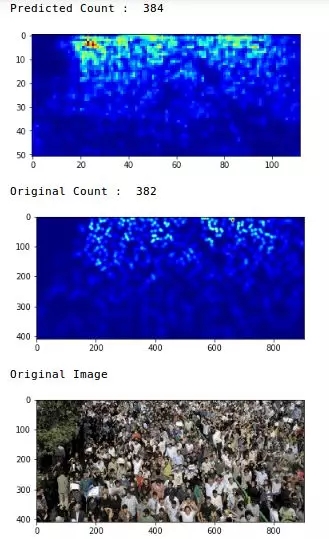
哇,最初的数字是382,我们的模型估计图像中有384人。这几乎是一个完美的演绎!
恭喜你建立了自己的人群计数模型!
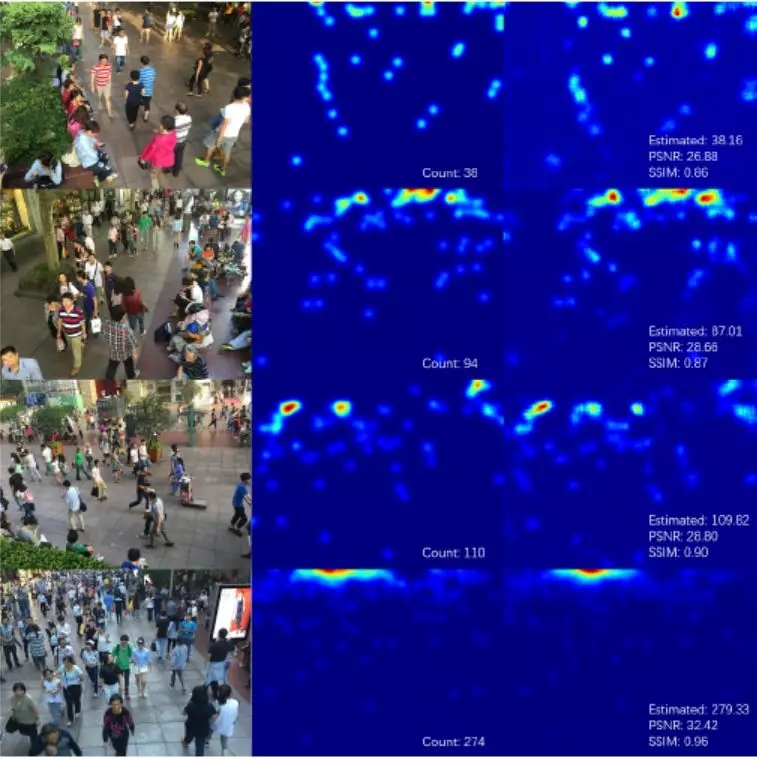
原始论文的评测图和结果



最后
您可以在https://colab.research.google.com上测试跑人群计数。
需要安装:Pytorch和Cuda
附论文下载地址:CSRNet: Dilated Convolutional Neural Networks for Understanding the HighlyCongested
声明:本文版权归原作者所有,文章收集于网络,为传播信息而发,如有侵权,请联系小编及时处理,谢谢!
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4860.html
摘要:适用人群爬虫方向数据分析方向非程序员加薪四开发前后端开发是程序员职业中的热门,目前来讲,人才缺口依然很大。寄语上面就是所有方向的学习路线了,把你感兴趣的方向掌握了之后,你去找工作不是什么问题的。 ...

本设计的时候,应用YOLO目标检测算法、Openpose姿势检测算法、deepsort跟踪算法、MSCNN群体密度估计技术实现了火灾监测、抽烟数据监测、行为表现安全监控、人群密度数据监测、防护口罩率数据监测、人员定位系统数据监测六个基本要素,对Python完成旅游景点安防监控系统感兴趣的小伙伴一起了解一下吧 本设计的时候,应用YOLO目标检测算法、Openpose姿势检测算法、deepsor...
马上就要开始啦这次共组织15个组队学习 涵盖了AI领域从理论知识到动手实践的内容 按照下面给出的最完备学习路线分类 难度系数分为低、中、高三档 可以按照需要参加 - 学习路线 - showImg(https://segmentfault.com/img/remote/1460000019082128); showImg(https://segmentfault.com/img/remote/...
摘要:我们再来看国内一线公司内的一个实验吧数据训练营都在用的方法,详解测试的那些坑如上是不同的引导卡片样式的实验,最终结果样式比样式的提升。设指标数值隐变量列显变量列含方案变量。 作者|蚂蚁金服人工智能部产品经理 范磊 本文首发|微信公众号 友盟数据服务 (ID:umengcom),转载请注明出处 If you are not running experiments,you are prob...
摘要:当经济复苏时,招聘将再次成为关键战场,特别是对年轻求职者来说,不是大量使用云计算的公司将变得不那么有吸引力。 Nutanix副总裁兼销售首席运营官Andrew Brinded表示,云计算为我们所处的时代提供了一种可行的部署模式,其影响必将不断扩大。1991年,著名的科技记者斯图尔特·奥尔索普(Stewart Alsop)做出了一个著名的错误预测。我预测最后一台主机将在1996年3月15日...

阅读 2856·2021-11-22 14:45
阅读 3007·2021-09-10 11:26
阅读 3382·2021-09-07 10:18
阅读 2277·2019-08-30 14:08
阅读 684·2019-08-29 12:22
阅读 1445·2019-08-26 13:48
阅读 2671·2019-08-26 10:24
阅读 1215·2019-08-23 18:35





