
摘要:另外,在损失函数中加入感知正则化则在一定程度上可缓解该问题。替代损失函数修复缺陷的最流行的补丁是。的作者认为传统损失函数并不会使收集的数据分布接近于真实数据分布。原来损失函数中的对数损失并不影响生成数据与决策边界的距离。
尽管 GAN 领域的进步令人印象深刻,但其在应用过程中仍然存在一些困难。本文梳理了 GAN 在应用过程中存在的一些难题,并提出了的解决方法。
使用 GAN 的缺陷
众所周知,GAN 是由 Generator 生成网络和 Discriminator 判别网络组成的。
1. Mode collapse(模型崩溃)
注:Mode collapse 是指 GAN 生成的样本单一,其认为满足某一分布的结果为 true,其他为 False,导致以上结果。
自然数据分布是非常复杂,且是多峰值的(multimodal)。也就是说数据分布有很多的峰值(peak)或众数(mode)。每个 mode 都表示相似数据样本的聚集,但与其他 mode 是不同的。
在 mode collapse 过程中,生成网络 G 会生成属于有限集 mode 的样本。当 G 认为可以在单个 mode 上欺骗判别网络 D 时,G 就会生成该 mode 外的样本。
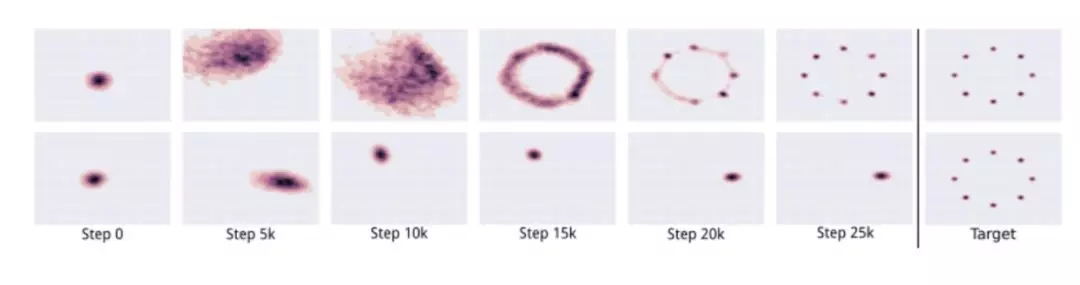
上图表示 GAN 的输出没有 mode collapse. 下图则出现了 mode collapse。
判别网络最后会判别来自该 mode 的样本是假的。最后,生成网络 G 会简单地锁定到另一个 mode。该循环会无限进行,就会限制生成样本的多样性。
2. Convergence(收敛)
GAN 训练过程中遇到的一个问题是什么时候停止训练?因为判别网络 D 损失降级会改善生成网络 G 的损失(反之亦然),因此无法根据损失函数的值来判断收敛,如下图所示:
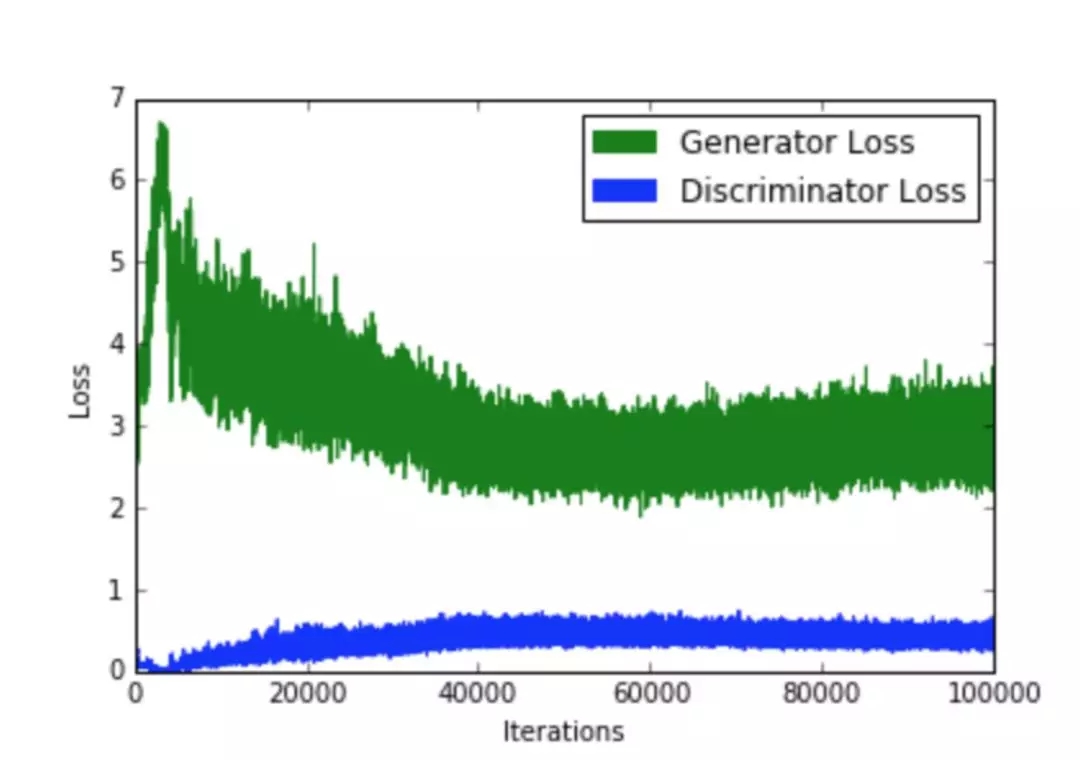
典型的GAN损失函数图。注意该如何从这个图中解释收敛性。
3. Quality(质量)
与前面提到的收敛问题一样,很难量化地判断生成网络 G 什么时候会生成高质量的样本。另外,在损失函数中加入感知正则化则在一定程度上可缓解该问题。
4. Metrics(度量)
GAN 的目标函数解释了生成网络 G 或 判别网络 D 如何根据组件来执行,但它却不表示输出的质量和多样性。因此,需要许多不同的度量指标来进行衡量。
改善性能的技术
下面总结了一些可以使 GAN 更加稳定使用的技术。
1. Alternative Loss Functions (替代损失函数)
修复 GAN 缺陷的最流行的补丁是 Wasserstein GAN (https://arxiv.org/pdf/1701.07875.pdf)。该 GAN 用 Earth Mover distance ( Wasserstein-1 distance 或 EM distance) 来替换传统 GAN 的 Jensen Shannon divergence ( J-S 散度) 。EM 距离的原始形式很难理解,因此使用了双重形式。这需要判别网络是 1-Lipschitz,通过修改判别网络的权重来维护。
使用 Earth Mover distance 的优势在于即使真实的生成数据分布是不相交的,它也是连续的。同时,在生成的图像质量和损失值之间存在一定关系。使用 Earth Mover distance 的劣势在于对于每个生成模型 G 都要执行许多判别网络 D 的更新。而且,研究人员认为权重修改是确保 1-Lipschitz 限制的极端方式。
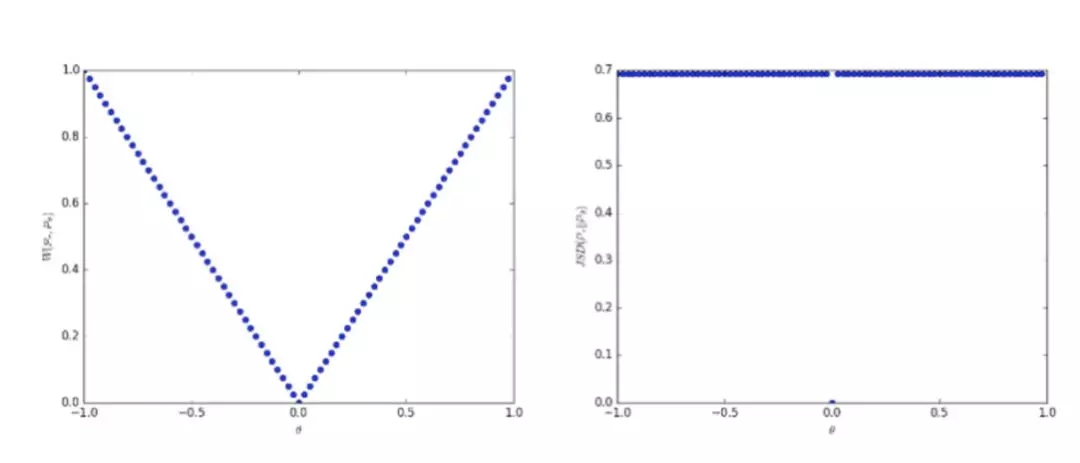
左图中 earth mover distance 是连续的, 即便其分布并不连续, 这不同于优图中的 the Jensen Shannon divergence。
另一个解决方案是使用均方损失( mean squared loss )替代对数损失( log loss )。LSGAN (https://arxiv.org/abs/1611.04076)的作者认为传统 GAN 损失函数并不会使收集的数据分布接近于真实数据分布。
原来 GAN 损失函数中的对数损失并不影响生成数据与决策边界(decision boundary)的距离。另一方面,LSGAN 也会对距离决策边界较远的样本进行惩罚,使生成的数据分布与真实数据分布更加靠近,这是通过将均方损失替换为对数损失来完成的。
2. Two Timescale Update Rule (TTUR)
在 TTUR 方法中,研究人员对判别网络 D 和生成网络 G 使用不同的学习速度。低速更新规则用于生成网络 G ,判别网络 D使用 高速更新规则。使用 TTUR 方法,研究人员可以让生成网络 G 和判别网络 D 以 1:1 的速度更新。 SAGAN (https://arxiv.org/abs/1805.08318) 就使用了 TTUR 方法。
3. Gradient Penalty (梯度惩罚)
论文Improved Training of WGANs(https://arxiv.org/abs/1704.00028)中,作者称权重修改会导致优化问题。权重修改会迫使神经网络学习学习更简单的相似(simpler approximations)达到最优数据分布,导致结果质量不高。同时如果 WGAN 超参数设置不合理,权重修改可能会出现梯度消失或梯度爆炸的问题,论文作者在损失函数中加入了一个简单的梯度惩罚机制以缓解该问题。
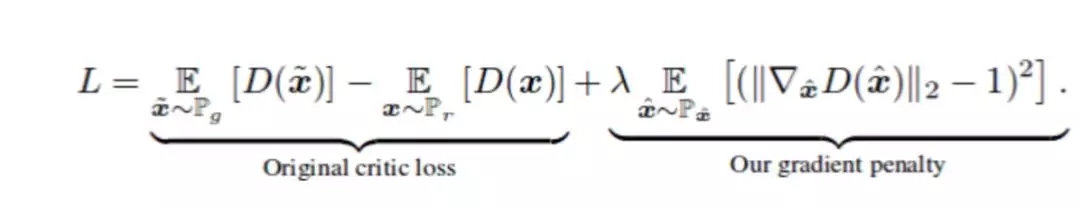
加入 Gradient Penalty 作为正则化器
DRAGAN (https://arxiv.org/abs/1705.07215)的作者称,当 GAN 的博弈达到一个局部平衡态(local equilibrium state),就会出现 mode collapse 的问题。而且判别网络 D 在这种状态下产生的梯度是非常陡(sharp)的。一般来说,使用梯度惩罚机制可以帮助避免这种状态的产生,极大增强 GAN 的稳定性,尽可能减少 mode collapse 问题的产生。
4. Spectral Normalization(谱归一化)
Spectral normalization 是用在判别网络 D 来增强训练过程的权重正态化技术 (weight normalization technique),可以确保判别网络 D 是 K-Lipschitz 连续的。 SAGAN (https://arxiv.org/abs/1805.08318)这样的实现也在判别网络 D 上使用了谱正则化。而且该方法在计算上要比梯度惩罚方法更加高效。
5. Unrolling and Packing (展开和打包)
文章 Mode collapse in GANs(http://aiden.nibali.org/blog/2017-01-18-mode-collapse-gans/)中提到一种预防 mode hopping 的方法就是在更新参数时进行预期对抗(anticipate counterplay)。展开的 GAN ( Unrolled GANs )可以使用生成网络 G 欺骗判别网络 D,然后判别网络 D 就有机会进行响应。
另一种预防 mode collapse 的方式就是把多个属于同一类的样本进行打包,然后传递给判别网络 D 。PacGAN (https://arxiv.org/abs/1712.04086)就融入了该方法,并证明可以减少 mode collapse 的发生。
6. 多个 GAN
一个 GAN 可能不足以有效地处理任务,因此研究人员提出使用多个连续的 GAN ,每个 GAN 解决任务中的一些简单问题。比如,FashionGAN(https://www.cs.toronto.edu/~urtasun/publications/zhu_etal_iccv17.pdf)就使用 2 个 GAN 来执行图像定位翻译。

FashionGAN 使用两个 GANs 进行图像定位翻译。
因此,可以让 GAN 慢慢地解决更难的问题。比如 Progressive GANs (ProGANs,https://arxiv.org/abs/1710.10196) 就可以生成分辨率极高的高质量图像。
7. Relativistic GANs(相对生成对抗网络)
传统的 GAN 会测量生成数据为真的可能性。Relativistic GANs 则会测量生成数据“逼真”的可能性。研究人员可以使用相对距离测量方法(appropriate distance measure)来测量相对真实性(relative realism),相关论文链接:https://arxiv.org/abs/1807.00734。
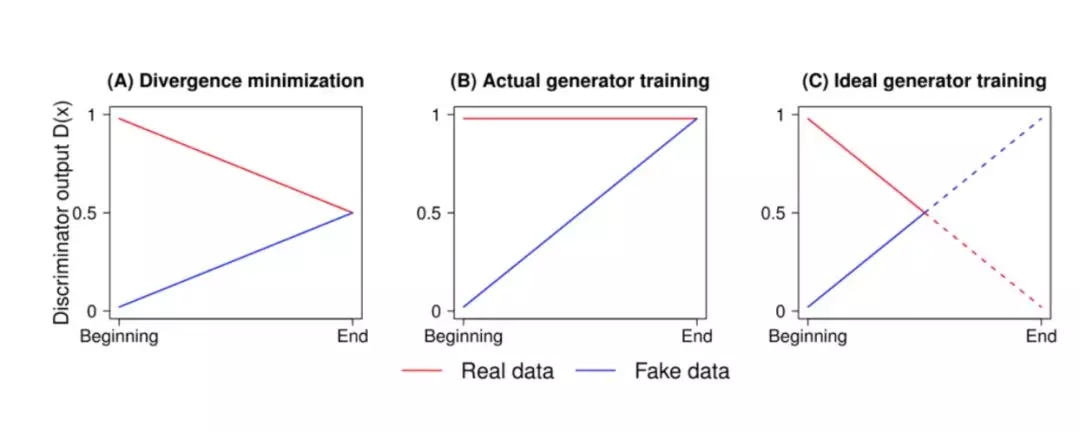
图 A 表示 JS 散度的最优解,图 B 表示使用标准 GAN 损失时判别网络 D 的输出,图 C 表示输出曲线的实际图。
在论文中,作者提到判别网络 D 达到最优状态时,D 的输出应该聚集到 0.5。但传统的 GAN 训练算法会让判别网络 D 对图像输出“真实”(real,1)的可能性,这会限制判别网络 D 达到最优性能。不过这种方法可以很好地解决这个问题,并得到不错的结果。

经过 5000 次迭代后,标准 GAN (左)和相对 GAN (右)的输出。
8. Self Attention Mechanism(自注意力机制)
Self Attention GANs(https://arxiv.org/abs/1805.08318)作者称用于生成图像的卷积会关注本地传播的信息。也就是说,由于限制性接收域这会错过广泛传播关系。
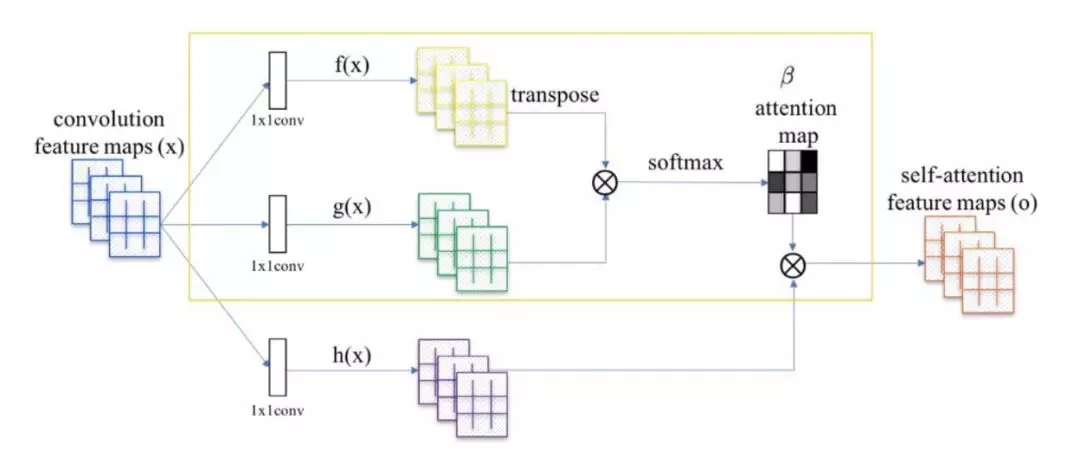
将 attention map (在黄色框中计算)添加到标准卷积操作中。
Self-Attention Generative Adversarial Network 允许图像生成任务中使用注意力驱动的、长距依赖的模型。自注意力机制是对正常卷积操作的补充,全局信息(长距依赖)会用于生成更高质量的图像,而用来忽略注意力机制的神经网络会考虑注意力机制和正常的卷积。(相关论文链接:https://arxiv.org/pdf/1805.08318.pdf)。

使用红点标记的可视化 attention map。
9. 其他技术
其他可以用来改善 GAN 训练过程的技术包括:
特征匹配
Mini Batch Discrimination(小批量判别)
历史平均值
One-sided Label Smoothing(单侧标签平滑)
Virtual Batch Normalization(虚拟批量正态化)
更多GAN技术
https://github.com/soumith/ganhacks。
原文链接:
https://medium.com/beyondminds/advances-in-generative-adversarial-networks-7bad57028032
声明:文章收集于网络,为传播信息而发,如有侵权,请联系小编及时处理,谢谢!
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4846.html
摘要:测度是高维空间中长度面积体积概念的拓广,可以理解为超体积。前作其实已经针对第二点提出了一个解决方案,就是对生成样本和真实样本加噪声,直观上说,使得原本的两个低维流形弥散到整个高维空间,强行让它们产生不可忽略的重叠。 在GAN的相关研究如火如荼甚至可以说是泛滥的今天,一篇新鲜出炉的arXiv论文《Wasserstein GAN》却在Reddit的Machine Learning频道火了,连Go...
摘要:也是相关的,因为它们已经成为实现和使用的主要基准之一。在本文发表之后不久,和中有容易获得的不同实现用于测试你所能想到的任何数据集。在这篇文章中,作者提出了对训练的不同增强方案。在这种情况下,鉴别器仅用于指出哪些是值得匹配的统计信息。 本文不涉及的内容首先,你不会在本文中发现:复杂的技术说明代码(尽管有为那些感兴趣的人留的代码链接)详尽的研究清单(点击这里进行查看 链接:http://suo....
摘要:直接把应用到领域主要是生成序列,有两方面的问题最开始是设计用于生成连续数据,但是自然语言处理中我们要用来生成离散的序列。如图,针对第一个问题,首先是将的输出作为,然后用来训练。 我来答一答自然语言处理方面GAN的应用。直接把GAN应用到NLP领域(主要是生成序列),有两方面的问题:1. GAN最开始是设计用于生成连续数据,但是自然语言处理中我们要用来生成离散tokens的序列。因为生成器(G...
摘要:于是,中将做了拆解,认为中生成模型应该包含的先验分成两种不能再做压缩的和可解释地有隐含意义的一组隐变量,简写为。利用这种更加细致的隐变量建模控制,可以说将的发展又推动了一步。 摘要在过去一两年中,生成式模型 Generative Adversarial Networks(GAN)的新兴为生成式任务带来了不小的进展。尽管 GAN 在被提出时存在训练不稳定等诸多问题,但后来的研究者们分别从模型、...
摘要:下面介绍一些值得注意的部分,有些简单解释原理,具体细节不能面面俱到,请参考专业文章主要来源实战那我们直接从拿到一个问题决定用神经网络说起。当你使用时可以适当减小学习率,跑过神经网络的都知道这个影响还蛮大。 神经网络构建好,训练不出好的效果怎么办?明明说好的拟合任意函数(一般连续)(为什么?可以参考http://neuralnetworksanddeeplearning.com/),说好的足够...

阅读 1335·2021-10-08 10:05
阅读 4158·2021-09-22 15:54
阅读 3127·2021-08-27 16:18
阅读 3127·2019-08-30 15:55
阅读 1469·2019-08-29 12:54
阅读 2772·2019-08-26 11:42
阅读 575·2019-08-26 11:39
阅读 2154·2019-08-26 10:11






