
摘要:更广泛地说,这些结果表明神经网络训练不需要被认为是一种炼丹术,而是可以被量化和系统化。中间的曲线中存在弯曲,渐变噪声标度预测弯曲发生的位置。
由于复杂的任务往往具有更嘈杂的梯度,因此越来越大的batch计算包,可能在将来变得有用,从而消除了AI系统进一步增长的一个潜在限制。
更广泛地说,这些结果表明神经网络训练不需要被认为是一种炼丹术,而是可以被量化和系统化。
在过去的几年里,AI研究人员通过数据并行技术,在加速神经网络训练方面取得了越来越大的成功,数据并行性将大batch数据分散到许多机器上。
研究人员成功地使用了成各种的batch进行图像分类和语言建模,甚至玩Dota 2。
这些大batch数据允许将越来越多的计算量有效地投入到单个模型的训练中,并且是人工智能训练计算快速增长的重要推动者。
但是,batch如果太大,则梯度消失。并且不清楚为什么这些限制对于某些任务影响更大而对其他任务影响较小。
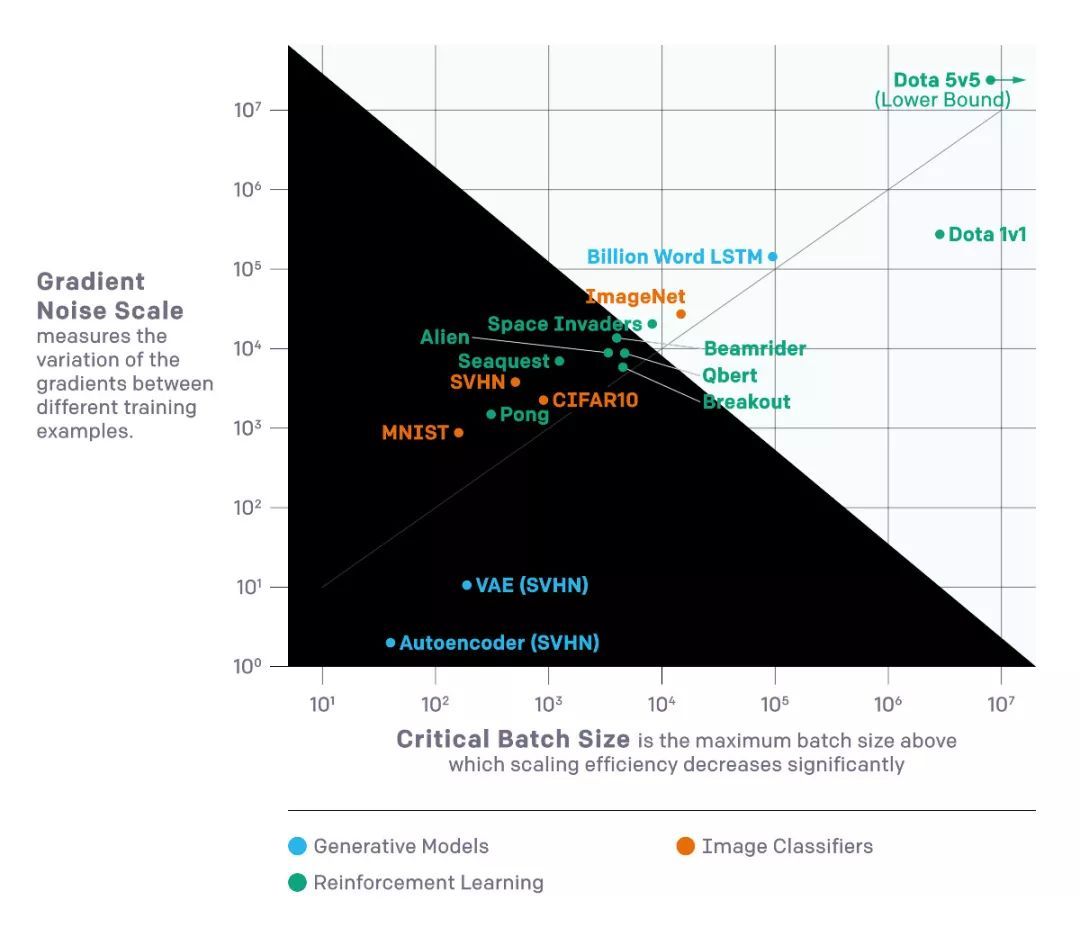
我们已经发现,通过测量梯度噪声标度,一个简单的统计量来量化网络梯度的信噪比,我们可以近似预测较大有效batch大小。
同理,噪声尺度可以测量模型所见的数据变化(在训练的给定阶段)。当噪声规模很小时,快速并行查看大量数据变得多余;反之,我们仍然可以从大batch数据中学到很多东西。
这种类型的统计数据被广泛用于样本量选择,并且已被提议用于深度学习,但尚未被系统地测量或应用于现代训练运行。
我们对上图所示的各种机器学习任务进行了验证,包括图像识别,语言建模,Atari游戏和Dota。
由于大batch通常需要仔细和昂贵的调整或特殊高效的学习率,因此提前知道上限在训练新模型方面提供了显著的实际优势。
我们发现,根据训练的现实时间和我们用于进行训练的总体积计算(与美元成本成比例)之间的权衡,可视化这些实验的结果是有帮助的。
在非常小的batch的情况下,batch加倍可以让我们在不使用额外计算的情况下减少一半的训练。在非常大的batch,更多的并行化不会导致更快的训练。中间的曲线中存在“弯曲”,渐变噪声标度预测弯曲发生的位置。

我们通过设置性能水平(比如在Beam Rider的Atari游戏中得分为1000)来制作这些曲线,并观察在不同batch大小下训练到该性能所需的时间。 结果与绩效目标的许多不同值相对较紧密地匹配了我们模型的预测。
梯度噪声尺度中的模式
我们在梯度噪声量表中观察到了几种模式,这些模式提供了人工智能训练未来可能存在的线索。
首先,在我们的实验中,噪声标度通常在训练过程中增加一个数量级或更多。
直观地,这意味着网络在训练早期学习任务的“更明显”的特征,并在以后学习更复杂的特征。
例如,在图像分类器的情况下,网络可能首先学习识别大多数图像中存在的小尺度特征(例如边缘或纹理),而稍后将这些部分组合成更一般的概念,例如猫和狗。
要查看各种各样的边缘或纹理,网络只需要看到少量图像,因此噪声比例较小;一旦网络更多地了解更大的对象,它就可以一次处理更多的图像,而不会看到重复的数据。
我们看到一些初步迹象表明,在同一数据集上不同模型具有相同的效果。更强大的模型具有更高的梯度噪声标度,但这仅仅是因为它们实现了更低的损耗。
因此,有一些证据表明,训练中增加的噪声比例不仅仅是收敛的假象,而是因为模型变得更好。如果这是真的,那么我们期望未来的更强大的模型具有更高的噪声规模,因此可以更加并行化。
在监督学习的背景下,从MNIST到SVHN到ImageNet都有明显的进展。在强化学习的背景下,从Atari Pong到Dota 1v1到Dota 5v5有明显的进展,较佳batch大小相差10,000倍以上。
因此,随着AI进入新的和更困难的任务,我们希望模型能够容忍更高的batch。
启示
数据并行度显着影响AI功能的进展速度。更快的训练使更强大的模型成为可能,并通过更快的迭代时间加速研究。
在早期研究中,我们观察到用于训练较大ML模型的计算,每3.5个月翻一番。我们注意到这种趋势是由经济能力和算法并行训练的能力共同决定的。
后一因素(算法可并行性)更难以预测,其局限性尚不清楚,但我们目前的结果代表了系统化和量化的一步。
特别是,我们有证据表明,在同一任务中,更困难的任务和更强大的模型将允许比我们迄今为止看到的更激进的数据并行性,这为训练计算的持续快速指数增长提供了关键驱动因素。
参考链接:
https://blog.openai.com/science-of-ai/
声明:文章收集于网络,如有侵权,请联系小编及时处理,谢谢!欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4834.html
摘要:我仍然用了一些时间才从神经科学转向机器学习。当我到了该读博的时候,我很难在的神经科学和的机器学习之间做出选择。 1.你学习机器学习的历程是什么?在学习机器学习时你最喜欢的书是什么?你遇到过什么死胡同吗?我学习机器学习的道路是漫长而曲折的。读高中时,我兴趣广泛,大部分和数学或科学没有太多关系。我用语音字母表编造了我自己的语言,我参加了很多创意写作和文学课程。高中毕业后,我进了大学,尽管我不想去...
摘要:训练深度神经网络需要大量的内存,用户使用这个工具包,可以在计算时间成本仅增加的基础上,在上运行规模大倍的前馈模型。使用导入此功能,与使用方法相同,使用梯度函数来计算参数的损失梯度。随后,在反向传播中重新计算检查点之间的节点。 OpenAI是电动汽车制造商特斯拉创始人 Elon Musk和著名的科技孵化器公司 Y Combinator总裁 Sam Altman于 2016年联合创立的 AI公司...

阅读 2581·2021-09-26 10:18
阅读 3451·2021-09-22 10:02
阅读 3318·2019-08-30 15:44
阅读 3392·2019-08-30 15:44
阅读 1889·2019-08-29 15:25
阅读 2640·2019-08-26 14:04
阅读 2108·2019-08-26 12:15
阅读 2490·2019-08-26 11:43



