
摘要:的两位研究者近日融合了两种非对抗方法的优势,并提出了一种名为的新方法。的缺陷让研究者开始探索用非对抗式方案来训练生成模型,和就是两种这类方法。不幸的是,目前仍然在图像生成方面显著优于这些替代方法。
生成对抗网络(GAN)在图像生成方面已经得到了广泛的应用,目前基本上是 GAN 一家独大,其它如 VAE 和流模型等在应用上都有一些差距。尽管 wasserstein 距离极大地提升了 GAN 的效果,但其仍在理论上存在训练不稳定和模式丢失的问题。Facebook 的两位研究者近日融合了两种非对抗方法的优势,并提出了一种名为 GLANN 的新方法。
这种新方法在图像生成上能与 GAN 相媲美,也许除了 VAE、Glow 和 Pixcel CNN,这种新模型也能加入到无监督生成的大家庭中。当然在即将到来的 2019 年中,我们也希望 GAN 之外的更多生成模型会得到更多的成长,也希望生成模型能有更多的新想法。

生成式图像建模是计算机视觉长期以来的一大研究方向。无条件生成模型的目标是通过给定的有限数量的训练样本学习得到能生成整个图像分布的函数。生成对抗网络(GAN)是一种新的图像生成建模技术,在图像生成任务上有广泛的应用,原因在于:1)能训练有效的无条件图像生成器;2)几乎是一种能用于不同域之间无监督图像转换的方法(但还有 NAM 也能做图像转换);3)是一种有效的感知式图像损失函数(例如 Pix2Pix)。
GAN 有明显的优势,但也有一些关键的缺点:1)GAN 很难训练,具体表现包括训练过程非常不稳定、训练突然崩溃和对超参数极其敏感。2)GAN 有模式丢失(mode-dropping)问题——只能建模目标分布的某些模式而非所有模式。例如如果我们用 GAN 生成 0 到 9 十个数字,那么很可能 GAN 只关注生成「1」这个数字,而很少生成其它 9 个数字。
一般我们可以使用生日悖论(birthday paradox)来衡量模式丢失的程度:生成器成功建模的模式数量可以通过生成固定数量的图像,并统计重复图像的数量来估计。对 GAN 的实验评估发现:学习到的模式数量显著低于训练分布中的数量。
GAN 的缺陷让研究者开始探索用非对抗式方案来训练生成模型,GLO 和 IMLE 就是两种这类方法。Bojanowski et al. 提出的 GLO 是将训练图像嵌入到一个低维空间中,并在该嵌入向量输入到一个联合训练的深度生成器时重建它们。GLO 的优势有:1)无模式丢失地编码整个分布;2)学习得到的隐含空间能与图像的形义属性相对应,即隐含编码之间的欧几里德距离对应于形义方面的含义差异。但 GLO 有一个关键缺点,即没有一种从嵌入空间采样新图像的原则性方法。尽管 GLO 的提出者建议用一个高斯分布来拟合训练图像的隐编码,但这会导致图像合成质量不高。
IMLE 则由 Li and Malik 提出,其训练生成模型的方式是:从一个任意分布采样大量隐含编码,使用一个训练后的生成器将每个编码映射到图像域中并确保对于每张训练图像都存在一张相近的生成图像。IMLE 的采样很简单,而且没有模式丢失问题。类似于其它最近邻方法,具体所用的指标对 IMLE 影响很大,尤其是当训练集大小有限时。回想一下,尽管经典的 Cover-Hart 结果告诉我们最近邻分类器的误差率渐进地处于贝叶斯风险的二分之一范围内,但当我们使用有限大小的示例样本集时,选择更好的指标能让分类器的表现更好。当使用 L2 损失直接在图像像素上训练时,IMLE 合成的图像是模糊不清的。
在本研究中,我们提出了一种名为「生成式隐含最近邻(GLANN:Generative Latent Nearest Neighbors)」的新技术,能够训练出与 GAN 质量相当或更优的生成模型。我们的方法首次使用了 GLO 来嵌入训练图像,从而克服了 IMLE 的指标问题。由 GLO 为隐含空间引入的迷人的线性特性能让欧几里德度量在隐含空间 Z 中具有形义含义。我们训练了一个基于 IMLE 的模型来实现任意噪声分布 E 和 GLO 隐含空间 Z 之间的映射。然后,GLO 生成器可以将生成得到的隐含编码映射到像素空间,由此生成图像。我们的 GLANN 方法集中了 IMLE 和 GLO 的双重优势:易采样、能建模整个分布、训练稳定且能合成锐利的图像。图 1 给出了我们的方法的一种方案。
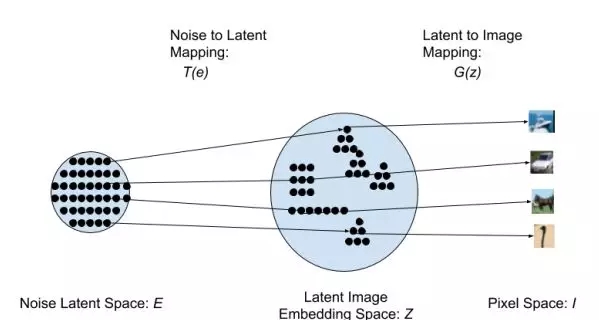
图 1:我们的架构的示意图:采样一个随机噪声向量 e 并将其映射到隐含空间,得到隐含编码 z = T(e)。该隐含编码再由生成器投射到像素空间,得到图像 I = G(z)
我们使用已确立的指标评估了我们的方法,发现其显著优于其它的非对抗式方法,同时其表现也比当前的基于 GAN 的模型更优或表现相当。GLANN 也在高分辨率图像生成和 3D 生成上得到了出色的结果。最后,我们表明 GLANN 训练的模型是最早的能真正执行非对抗式无监督图像转换的模型。
论文:使用生成式隐含最近邻的非对抗式图像合成

论文链接:https://arxiv.org/pdf/1812.08985v1.pdf
生成对抗网络(GAN)近来已经主导了无条件图像生成领域。GAN 方法会训练一个生成器和一个判别器,其中生成器根据随机噪声向量对图像进行回归操作,判别器则会试图分辨生成的图像和训练集中的真实图像。GAN 已经在生成看似真实的图像上取得了出色的表现。GAN 尽管很成功,但也有一些关键性缺陷:训练不稳定和模式丢失。GAN 的缺陷正促使研究者研究替代方法,其中包括变分自编码器(VAE)、隐含嵌入学习方法(比如 GLO)和基于最近邻的隐式较大似然估计(IMLE)。不幸的是,目前 GAN 仍然在图像生成方面显著优于这些替代方法。在本研究中,我们提出了一种名为「生成式隐含最近邻(GLANN)」的全新方法,可不使用对抗训练来训练生成模型。GLANN 结合了 IMLE 和 GLO 两者之长,克服了两种方法各自的主要缺点。结果就是 GLANN 能生成比 IMLE 和 GLO 远远更好的图像。我们的方法没有困扰 GAN 训练的模式崩溃问题,而且要稳定得多。定性结果表明 GLANN 在常用数据集上优于 800 个 GAN 和 VAE 构成的基线水平。研究还表明我们的模型可以有效地用于训练真正的非对抗式无监督图像转换。
方法
我们提出的 GLANN(生成式隐含最近邻)方法克服了 GLO 和 IMLE 两者的缺点。GLANN 由两个阶段构成:1)使用 GLO 将高维的图像空间嵌入到一个「行为良好的」隐含空间;2)使用 IMLE 在一个任意分布(通常是一个多维正态分布)和该低维隐含空间之间执行映射。
实验
为了评估我们提出的方法的表现,我们执行了定量和定性实验来比较我们的方法与已确立的基线水平。

表 1:生成质量(FID/ Frechet Inception Distance)
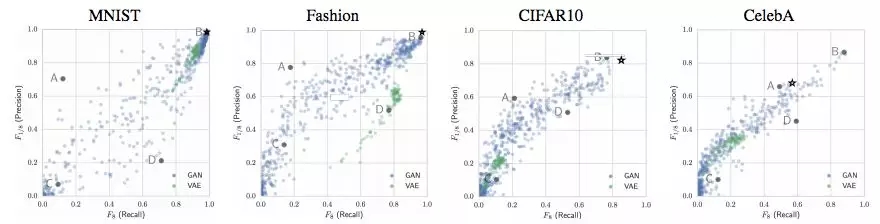
图 2:在 4 个数据集上根据衡量的精度-召回率情况。这些图表来自 [31]。我们用星标在相关图表上标出了我们的模型在每个数据集上的结果。

图 3:IMLE [24]、GLO [5]、GAN [25] 与我们的方法的合成结果比较。第一排:MNIST。第二排:Fashion。第三排:CIFAR10。最后一排:CelebA64。IMLE 下面空缺的部分在 [24] 中没有给出。GAN 的结果来自 [25],对应于根据精度-召回率指标评估的 800 个生成模型中较好的一个。

图 4:在 CelebA-HQ 上以 256×256 的分辨率得到的插值实验结果。最左边和最右边的图像是根据随机噪声随机采样得到的。中间的插值图像很平滑而且视觉质量很高。

图 5:在 CelebA-HQ 上以 1024×1024 的分辨率得到的插值实验结果

图 6:GLANN 生成的 3D 椅子图像示例
讨论
损失函数:在这项研究中,我们用一种感知损失(perceptual loss)代替了标准的对抗损失函数。在实践中我们使用了 ImageNet 训练后的 VGG 特征。Zhang et al. [40] 宣称自监督的感知损失的效果并不比 ImageNet 训练的特征差。因此,我们的方法很可能与自监督感知损失有相似的表现。
更高的分辨率:分辨率从 64×64 到 256×256 或 1024×1024 的增长是通过对损失函数进行简单修改而实现的:感知损失是在原始图像以及该图像的一个双线性下采样版本上同时计算的。提升到更高的分辨率只简单地需要更多下采样层级。研究更复杂精细的感知损失也许还能进一步提升合成质量。
其它模态:我们这项研究关注的重点是图像合成。我们相信我们的方法也可以扩展到很多其它模态,尤其是 3D 和视频。我们的方法流程简单,对超参数稳健,这些优点使其可比 GAN 远远更简单地应用于其它模态。我们在 4.4 节给出了一些说明这一点的证据。未来的一大研究任务寻找可用于 2D 图像之外的其它域的感知损失函数。
声明:文章收集于网络,如有侵权,请联系小编及时处理,谢谢!欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4830.html
摘要:是世界上最重要的研究者之一,他在谷歌大脑的竞争对手,由和创立工作过不长的一段时间,今年月重返,建立了一个探索生成模型的新研究团队。机器学习系统可以在这些假的而非真实的医疗记录进行训练。今年月在推特上表示是的,我在月底离开,并回到谷歌大脑。 理查德·费曼去世后,他教室的黑板上留下这样一句话:我不能创造的东西,我就不理解。(What I cannot create, I do not under...
摘要:文本谷歌神经机器翻译去年,谷歌宣布上线的新模型,并详细介绍了所使用的网络架构循环神经网络。目前唇读的准确度已经超过了人类。在该技术的发展过程中,谷歌还给出了新的,它包含了大量的复杂案例。谷歌收集该数据集的目的是教神经网络画画。 1. 文本1.1 谷歌神经机器翻译去年,谷歌宣布上线 Google Translate 的新模型,并详细介绍了所使用的网络架构——循环神经网络(RNN)。关键结果:与...
摘要:自年提出生成对抗网络的概念后,生成对抗网络变成为了学术界的一个火热的研究热点,更是称之为过去十年间机器学习领域最让人激动的点子。 自2014年Ian Goodfellow提出生成对抗网络(GAN)的概念后,生成对抗网络变成为了学术界的一个火热的研究热点,Yann LeCun更是称之为过去十年间机器学习领域最让人激动的点子。生成对抗网络的简单介绍如下,训练一个生成器(Generator,简称G...
摘要:我仍然用了一些时间才从神经科学转向机器学习。当我到了该读博的时候,我很难在的神经科学和的机器学习之间做出选择。 1.你学习机器学习的历程是什么?在学习机器学习时你最喜欢的书是什么?你遇到过什么死胡同吗?我学习机器学习的道路是漫长而曲折的。读高中时,我兴趣广泛,大部分和数学或科学没有太多关系。我用语音字母表编造了我自己的语言,我参加了很多创意写作和文学课程。高中毕业后,我进了大学,尽管我不想去...
摘要:引用格式王坤峰,苟超,段艳杰,林懿伦,郑心湖,王飞跃生成对抗网络的研究与展望自动化学报,论文作者王坤峰,苟超,段艳杰,林懿伦,郑心湖,王飞跃摘要生成式对抗网络目前已经成为人工智能学界一个热门的研究方向。本文概括了的研究进展并进行展望。 3月27日的新智元 2017 年技术峰会上,王飞跃教授作为特邀嘉宾将参加本次峰会的 Panel 环节,就如何看待中国 AI学术界论文数量多,但大师级人物少的现...

阅读 2865·2021-11-18 10:02
阅读 1848·2021-09-30 10:00
阅读 5531·2021-09-22 15:27
阅读 1306·2019-08-30 15:54
阅读 3814·2019-08-29 11:13
阅读 3035·2019-08-29 11:05
阅读 3406·2019-08-29 11:01
阅读 649·2019-08-26 13:52






