
摘要:近日,英伟达发表了一篇大规模语言建模的论文,他们使用块在小时内使得可以收敛,值得注意的是,他们使用的数据集包含的文本,这在以前通常需要花费数周的时间进行训练。表示训练出现发散。
近日,英伟达发表了一篇大规模语言建模的论文,他们使用 128 块 GPU 在 4 小时内使得 mLSTM 可以收敛,值得注意的是,他们使用的 Amazon Reviews 数据集包含 40GB 的文本,这在以前通常需要花费数周的时间进行训练。这样的大规模语言模型能作为一种预训练模型迁移大量的语言知识,也就是说如果将其应用到机器翻译、机器阅读理解和情感分析等 NLP 任务,数据需求量和计算量都能得到大幅度的降低。
近年来,深度学习已经成功应用到多种问题中。迁移学习在计算机视觉问题上的成功运用使得许多应用成为可能:VGG[6] 和 ResNets [7] 等大型 CNN 在 ImageNet 等大型图像数据集上进行预训练 [8,9] 然后在计算机视觉任务中作为骨干网络架构。这些模型可以为新任务提取有用的特征,而无需在执行每个任务时都从头开始训练 [2], [10]–[12]。
最近的研究已经从无监督语言建模中得出了很有潜力的结果,随后人们将迁移学习应用到自然语言任务 [3], [13]。然而,与卷积图像模型不同,神经语言模型还没有从大规模和迁移学习中受益。神经语言模型往往通过在大型语料库上使用词嵌入预训练来实现大规模迁移学习 [14]– [16]。仅迁移词嵌入会限制迁移的范围,因为词嵌入不会捕获文本中的序列信息。英伟达的研究者想要迁移的是具备处理文本序列能力的整个 NLP 模型。
然而,由于在大型数据集上训练大型语言模型非常耗时,因此上述情况下的迁移学习非常困难。最近发表的几篇论文试图发挥分布式深度学习及可用高性能计算(HPC)资源的内存和计算能力的优势,通过利用分布式数据并行并在训练期间增加有效批尺寸来解决训练耗时的问题 [1],[17]– [20]。这一研究往往聚焦于计算机视觉,很少涉及自然语言任务,更不用说基于 RNN 的语言模型了。由于基于 RNN 的语言模型具有序列性,这些模型在数值上很难训练,且并行性差。有证据表明,用于语言建模、语音识别和神经机器翻译的 RNN 在大型数据集上训练时,准确率还有提升的空间 [21]。相应的,高效训练大型 RNN 模型的技术将在许多神经语言任务中带来准确率的提升。
研究人员专注于在亚马逊评论数据集上训练一个单层 4096 神经元乘法 LSTM(multiplicative LSTM,mLSTM)字符级语言模型,这个数据集是目前开源的较大自然语言处理数据集之一,他们将该模型迁移到 Binary Stanford Sentiment Treebank (SST) 和 IMDB 电影评论数据集的情感分类的下游任务中。然后用混合精度 FP16/FP32 算术运算来训练循环模型,它在单个 V100 上的训练速度比 FP32 快了 4.2 倍。
接着研究人员通过 128GPU 的分布式数据并行,使用 32k 的批大小训练了混合精度模型。这比起使用单个 GPU,训练的数据量增加了 109 倍。然而,由于批大小变大,需要额外的 epoch 来将模型训练至相同准确率,最终总训练时长为 4 小时。
此外,他们还训练了一个有 8192 个神经元的 mLSTM,它在亚马逊评论语言模型中的表现超越了当前最优模型,取得了每字符位数(BPC)为 1.038,SST 分类准确率为 93.8% 的性能。
研究人员分析了分布式数据并行是如何随着模型增大而扩展的。在使用分布式数据并行训练 RNN 时,他们观察到一些训练时批量过大会出现的常见问题。他们研究数据集大小、批大小和学习率方案之间的关系,以探索如何有效地利用大批量来训练更为常见的大型自然语言处理(NLP)数据集。
在这篇论文中,作者们表示这项工作为商业应用以及深度学习研究提供了大规模无监督 NLP 训练的基础。作者在 GitHub 项目中展示了实现无监督情感分析的实验,其中大规模语言模型可以作为情感分析的预训练模型。
项目地址:https://github.com/NVIDIA/sentiment-discovery
论文:Large Scale Language Modeling: Converging on 40GB of Text in Four Hours

论文地址:https://arxiv.org/pdf/1808.01371v1.pdf
摘要:近期有许多研究关注如何在大型数据集上快速训练卷积神经网络,然后将这些模型学习到的知识迁移到多种任务上。跟随 [Radford 2017] 研究的方向,在这项研究中,我们展示了循环神经网络在自然语言任务上相似的可扩展性和迁移能力。通过使用混合精度算术运算,我们在 128 块英伟达 Tesla V100 GPU 使用 32k 的批大小进行分布式训练,因此可以在 40GB 的亚马逊评论(Amazon Reviews)数据集上针对无监督文本重建任务训练一个字符级 4096 维乘法 LSTM(multiplicative LSTM, mLSTM),并在 4 个小时完成 3 个 epoch 的训练。这个运行时相比于之前在相同数据集、相同大小和配置上花费一个月训练一个 epoch 的工作很有优势。大批量 RNN 模型的收敛一般非常有挑战性。近期的研究提出将学习率作为批大小的函数进行缩放,但我们发现在这个问题中仅将学习率作为批大小的函数缩放会导致更差的收敛行为或立刻发散。我们提供了一个学习率方案,允许我们的模型能在 32k 的批大小下收敛。由于我们的模型可以在数小时内在亚马逊数据集上收敛,并且尽管我们的计算需求是 128 块 Tesla V100 GPU,这个硬件规模很大,但在商业上是可行的,这项工作打开了在大多数商业应用以及深度学习研究中实现大规模无监督 NLP 训练的大门。一个模型可以一夜之间就在大多数公开或私人文本数据集训练好。
3. 大批量训练
鉴于亚马逊语料库的规模,预训练大型当前最优神经语言模型是一个非常耗时的过程。在单个 GPU 上运行这么大的工作负载不切实际,因为当前最优模型一般会比较大,且每个 GPU 能够承担的训练批量大小有限。为了保证有效的训练和迁移大型语言模型,我们使用多 GPU 并行化训练。我们专注于多 GPU 数据并行化,这意味着我们在训练过程中将批次分割并分配给多个 GPU。我们没有使用模型并行化(这种方法把神经网络分割成多个处理器),因为该方法灵活性较差,且对软件限制较多,不过它仍然是进一步并行化的有趣选择。
我们使用同步数据并行化,其中大批量数据被均匀分布给所有参与其中的工作进程,工作进程处理前向和反向传播、相互通信产生的梯度,以及在获取新的数据批量之前更新模型。鉴于模型大小和通信延迟,数据并行化通过可用 GPU 的数量与批量大小的线性扩展来实现近似线性加速。
为保证任意语言模型的大批量预训练,明确分析使用基于 RNN 的语言模型进行大批量预训练的效果非常重要。循环神经网络的连续性使得训练过程很难优化,因为 RNN 计算过程中存在鞍点、局部极小值和数值不稳定性 [35]–[37]。这些复杂性使得使用 RNN 进行大批量训练的分析非常有必要。
为了保证 RNN 语言模型的大批量训练,我们探索了线性缩放规则和 Hoffer 等人 [40] 提出的平方根缩放规则 的影响。
4. 混合精度训练
FP16 不仅能减少通信成本,还对直接加速处理器上的训练起到关键作用,如支持较高吞吐量混合精度运算的 V100。V100 的单精度浮点运算性能可达 15.6 TFlops,而混合精度运算(FP16 存储和相乘,FP32 累加)的浮点运算性能达到 125 TFlops。
5. 实验
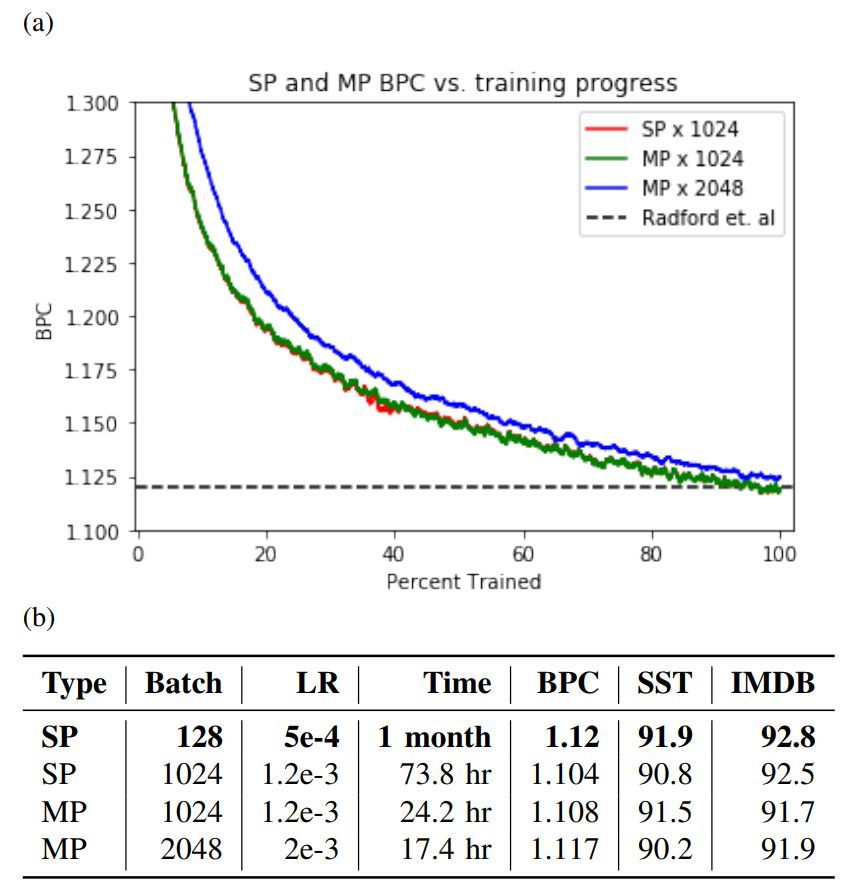
图 2:a 为混合精度(MP)和单精度(SP)的训练曲线,b 为单精度和混合精度的测试集评估对比,其中评估指标为亚马逊 BPC 和 Radford 等人实现的二元情感分类准确率基线集。

图 3: a) 亚马逊评论数据集一次 epoch 的训练时间与 GPU 数量具有线性关系。b) 有(无)无限带宽的分布式数据并行训练的平均每个迭代次数和相对加速度。
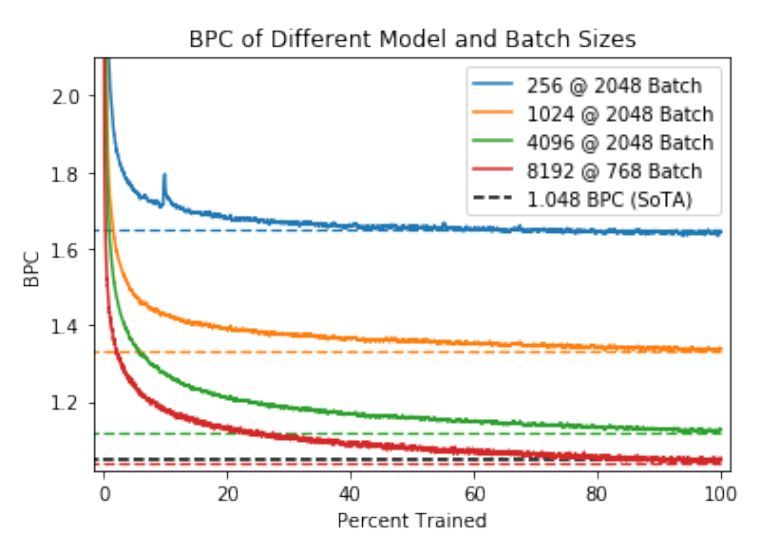
图 4:在特定维度和批大小的亚马逊评论数据集上,训练 mLSTM 模型完成一个 epoch 的训练过程。虚线表示经过一个 epoch 的训练后的评估 BPC,以及由 Gray 等人 [34] 得到的当前较佳评估结果(SoTA)。
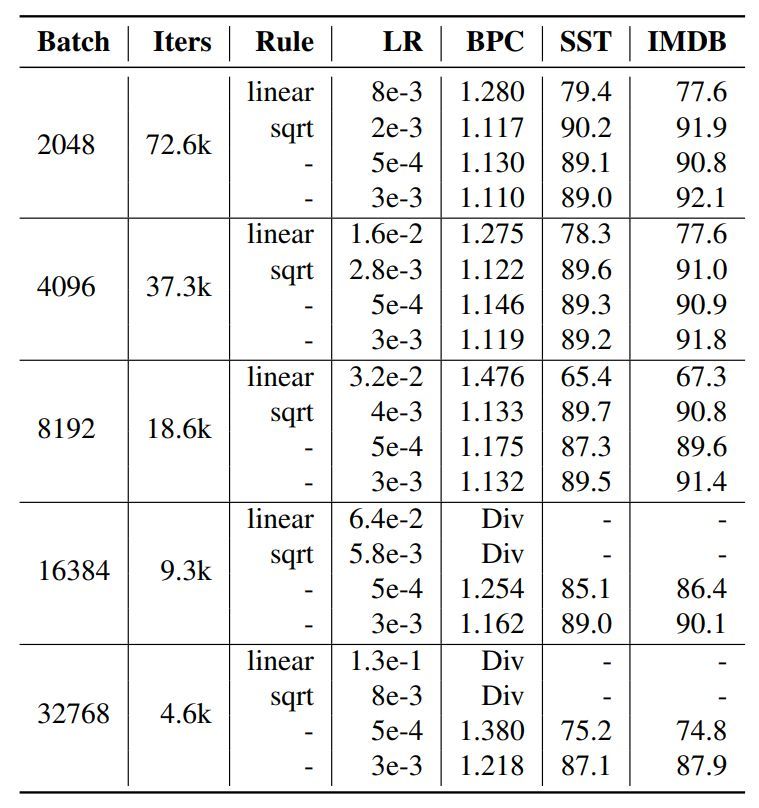
图 5:在多种初始学习率下使用 1 epoch 内衰减到零的学习率方案的评估结果。某些初始学习率按照基于 128 批大小的 5e-4 衰减率的线性或平方根缩放规则进行缩放。Div 表示训练出现发散。
声明:文章收集于网络,如有侵权,请联系小编及时处理,谢谢!
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4803.html
Apache MXNet v0.12来了。今天凌晨,亚马逊宣布了MXNet新版本,在这个版本中,MXNet添加了两个重要新特性:支持英伟达Volta GPU,大幅减少用户训练和推理神经网络模型的时间。在存储和计算效率方面支持稀疏张量(Sparse Tensor),让用户通过稀疏矩阵训练模型。下面,量子位将分别详述这两个新特性。Tesla V100 加速卡内含 Volta GV100 GPU支持英伟...
摘要:深度学习是一个对算力要求很高的领域。这一早期优势与英伟达强大的社区支持相结合,迅速增加了社区的规模。对他们的深度学习软件投入很少,因此不能指望英伟达和之间的软件差距将在未来缩小。 深度学习是一个对算力要求很高的领域。GPU的选择将从根本上决定你的深度学习体验。一个好的GPU可以让你快速获得实践经验,而这些经验是正是建立专业知识的关键。如果没有这种快速的反馈,你会花费过多时间,从错误中吸取教训...
摘要:在经历五年多的落后之后,如今美国终于在超级计算机领域再度超越中国,重夺头名桂冠。这一消息在本周于德国法兰克福举行的年度国际超级计算机大会上正式公布。在经历五年多的落后之后,如今美国终于在超级计算机领域再度超越中国,重夺头名桂冠。这台由IBM公司为田纳西州橡树岭国家实验室建造的Summit超级计算机(如上图所示)在本周一发布的全球超算五百强中位列第一(这份榜单每年发布两轮,列举世界上五百台最为...
摘要:最近,等人对于英伟达的四种在四种不同深度学习框架下的性能进行了评测。本次评测共使用了种用于图像识别的深度学习模型。深度学习框架和不同网络之间的对比我们使用七种不同框架对四种不同进行,包括推理正向和训练正向和反向。一直是深度学习方面最畅销的。 最近,Pedro Gusmão 等人对于英伟达的四种 GPU 在四种不同深度学习框架下的性能进行了评测。本次评测共使用了 7 种用于图像识别的深度学习模...
摘要:年月,腾讯机智机器学习平台团队在数据集上仅用分钟就训练好,创造了训练世界纪录。训练期间采用预定的批量变化方案。如此,我们也不难理解腾讯之后提出的层级的思想了。你可能觉得这对于索尼大法而言不算什么,但考虑到维护成本和占地,这就很不经济了。 随着技术、算力的发展,在 ImageNet 上训练 ResNet-50 的速度被不断刷新。2018 年 7 月,腾讯机智机器学习平台团队在 ImageNet...

阅读 2375·2021-11-19 09:58
阅读 1858·2021-11-15 11:36
阅读 3003·2019-08-30 15:54
阅读 3551·2019-08-29 15:07
阅读 2908·2019-08-26 11:47
阅读 3018·2019-08-26 10:11
阅读 2659·2019-08-23 18:22
阅读 2907·2019-08-23 17:58






