
摘要:工资不涨,英伟达的售价年年涨。近日,宣布推出适用于的,其中包括。对于正在进行的深度学习加速工作而言,这是一座重大的里程碑。而实现则使用了,这是一个适用于深度学习的高度优化例程库。目前已发布安装说明及预构建的映像。
工资不涨,英伟达 GPU 的售价年年涨。因此,多一个竞争对手,总是好事。
近日,Google 宣布推出适用于 ROCm GPU 的 TensorFlow v1.8,其中包括 Radeon Instinct MI25。对于 AMD 正在进行的深度学习加速工作而言,这是一座重大的里程碑。
ROCm 即 Radeon 开放生态系统 (Radeon Open Ecosystem),是我们在 Linux 上进行 GPU 计算的开源软件基础。而 TensorFlow 实现则使用了 MIOpen,这是一个适用于深度学习的高度优化 GPU 例程库。
AMD 提供了一个预构建的 whl 软件包,安装过程很简单,类似于安装 Linux 通用 TensorFlow。目前 Google 已发布安装说明及预构建的 Docker 映像。下面,我们就来手把手地教大家。
如何在 AMD 的 GPU 上运行 TensorFlow?
首先,你需要安装开源 ROCm 堆栈,详细的安装说明可以参考:
https://rocm.github.io/ROCmInstall.html
然后,你需要安装其他相关的 ROCm 软件包:
sudo apt update
sudo apt install rocm-libs miopen-hip cxlactivitylogger
最后,安装 TensorFlow (通过 Google 预先构建的 whl 软件包):
sudo apt install wget python3-pip
wget http://repo.radeon.com/rocm/misc/tensorflow/tensorflow-1.8.0-cp35-cp35m-manylinux1_x86_64.whl
pip3 install ./tensorflow-1.8.0-cp35-cp35m-manylinux1_x86_64.whl
ROCm-docker 安装指南
Rocm-docker 的安装指南:
https://github.com/RadeonOpenCompute/ROCm-docker/blob/master/quick-start.md
启动 TensorFlow v1.8 docker 映像:
alias drun="sudo docker run -it --network=host --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v $HOME/dockerx:/dockerx -v /data/imagenet/tf:/imagenet"
drun rocm/tensorflow:rocm1.8.2-tf1.8-python2
当你使用 ROCm 容器时,以下是一些常用且非常实用的 docker 命令:
一个新的 docker 容器通常不包含元数据存储库命令 apt。因此,在尝试使用 apt 安装新软件之前,请首先确保命令 sudo apt update 的正常运行。
出现如下报错消息,通常意味着当前用户无执行 docker 的权限;你需要使用 sudo 命令或将你的用户添加到 docker 组。
在正在运行的容器中打开另一个终端的命令:
从主机中复制文件到正在运行的 docker 上的命令:
从正在运行的 docker 容器中复制文件到主机上的命令:
在拉取图像时,收到设备上没有剩余空间的消息,请检查 docker 引擎正在使用的存储驱动程序。如果是“设备映射器 (device mapper)”,这意味着“设备映射器”存储驱动程序限制了图像大小限制,此时你可以参考快速入门指南中关于更改存储驱动程序的解决方案,链接如下:
https://github.com/RadeonOpenCompute/ROCm-docker/blob/master/quick-start.md
实践指南
1、图像识别
我们将使用 TensorFlow 的一个教程作为 Inception-v3 图像识别任务:
https://www.tensorflow.org/tutorials/image_recognition
以下是如何运行代码:
cd ~ && git clone https://github.com/tensorflow/models.git
cd ~/models/tutorials/image/imagenet
python3 classify_image.py
之后,你会看到一个带有相关分数的标签列表,上面的脚本是用于对熊猫的图像进行分类,所以你会看到下面的结果:
giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca (score = 0.89103)
indri, indris, Indri indri, Indri brevicaudatus (score = 0.00810)
lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens (score = 0.00258)
custard apple (score = 0.00149)
earthstar (score = 0.00141)
2、语音识别
接下来,让我们试试 TensorFlow 的语音识别教程:
https://www.tensorflow.org/tutorials/audio_recognition
以下是运行代码:
cd ~ && git clone https://github.com/tensorflow/tensorflow.git
cd ~/tensorflow
python3 tensorflow/examples/speech_commands/train.py
在默认设置下运行几个小时后,你将看到准确度越来越高的趋势:
[...]
INFO:tensorflow:Step 18000: Validation accuracy = 88.7% (N=3093)
INFO:tensorflow:Saving to "/tmp/speech_commands_train/conv.ckpt-18000"
INFO:tensorflow:set_size=3081
INFO:tensorflow:Confusion Matrix:
[[254 2 0 0 0 1 0 0 0 0 0 0]
[ 3 195 5 5 11 8 4 5 7 0 4 10]
[ 0 4 239 0 1 1 9 1 0 0 1 0]
[ 0 5 0 220 1 7 2 4 0 1 1 11]
[ 1 1 0 0 258 0 4 0 0 2 4 2]
[ 2 5 0 15 1 211 2 0 2 0 2 13]
[ 1 2 15 0 6 0 240 2 0 0 1 0]
[ 1 13 0 0 3 0 2 237 0 1 2 0]
[ 0 5 1 0 2 1 1 3 231 2 0 0]
[ 0 3 0 0 21 1 3 3 5 225 1 0]
[ 0 0 1 1 8 1 3 0 0 2 232 1]
[ 0 14 0 34 6 5 5 2 0 1 0 184]]
INFO:tensorflow:Final test accuracy = 88.5% (N=3081)
如果你想测试训练好的模型,可以尝试以下方法:
python3 tensorflow/examples/speech_commands/freeze.py
--start_checkpoint=/tmp/speech_commands_train/conv.ckpt-18000
--output_file=/tmp/my_frozen_graph.pb
python3 tensorflow/examples/speech_commands/label_wav.py --graph=/tmp/my_frozen_graph.pb --labels=/tmp/speech_commands_train/conv_labels.txt --wav=/tmp/speech_dataset/left/a5d485dc_nohash_0.wav
你会看到“left”标签的得分较高:
left (score = 0.74686)
right (score = 0.12304)
unknown (score = 0.10759)
3、多 GPU 训练
最后,让我们用多个 GPU 来训练 ResNet-50。我们将使用 TensorBoard 来监控进度,因此我们的工作流程分为两个终端和一个浏览器。首先,我们假设你将 ImageNet 数据集放在“/ data / imagenet”(可更改)下。
1) 第一个终端
cd ~ && git clone https://github.com/tensorflow/benchmarks.git
cd ~/benchmarks
git checkout -b may22 ddb23306fdc60fefe620e6ce633bcd645561cb0d
MODEL=resnet50
NGPUS=4
BATCH_SIZE=64
ITERATIONS=5000000
TRAIN_DIR=trainbenchmarks${MODEL}
rm -rf "${TRAIN_DIR}"
python3 ./scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py
--model=${MODEL} --data_name=imagenet --data_dir=/data/imagenet
--train_dir="${TRAIN_DIR}" --print_training_accuracy=True
--summary_verbosity 2 --save_summaries_steps 10 --save_model_secs=3600
--variable_update=parameter_server --local_parameter_device=cpu
--num_batches=${ITERATIONS} --batch_size=${BATCH_SIZE}
--num_gpus=${NGPUS} 2>&1 | tee /dockerx/tf-imagenet.txt
2) 第二个终端
hostname -I # find your IP address
tensorboard --logdir train_benchmarks_resnet --host
3) 在浏览器里打开 Tensorboard
链接: http://
使用 TensorBoard,你可以看到 loss 越来越小、准确性越来越高的趋势。
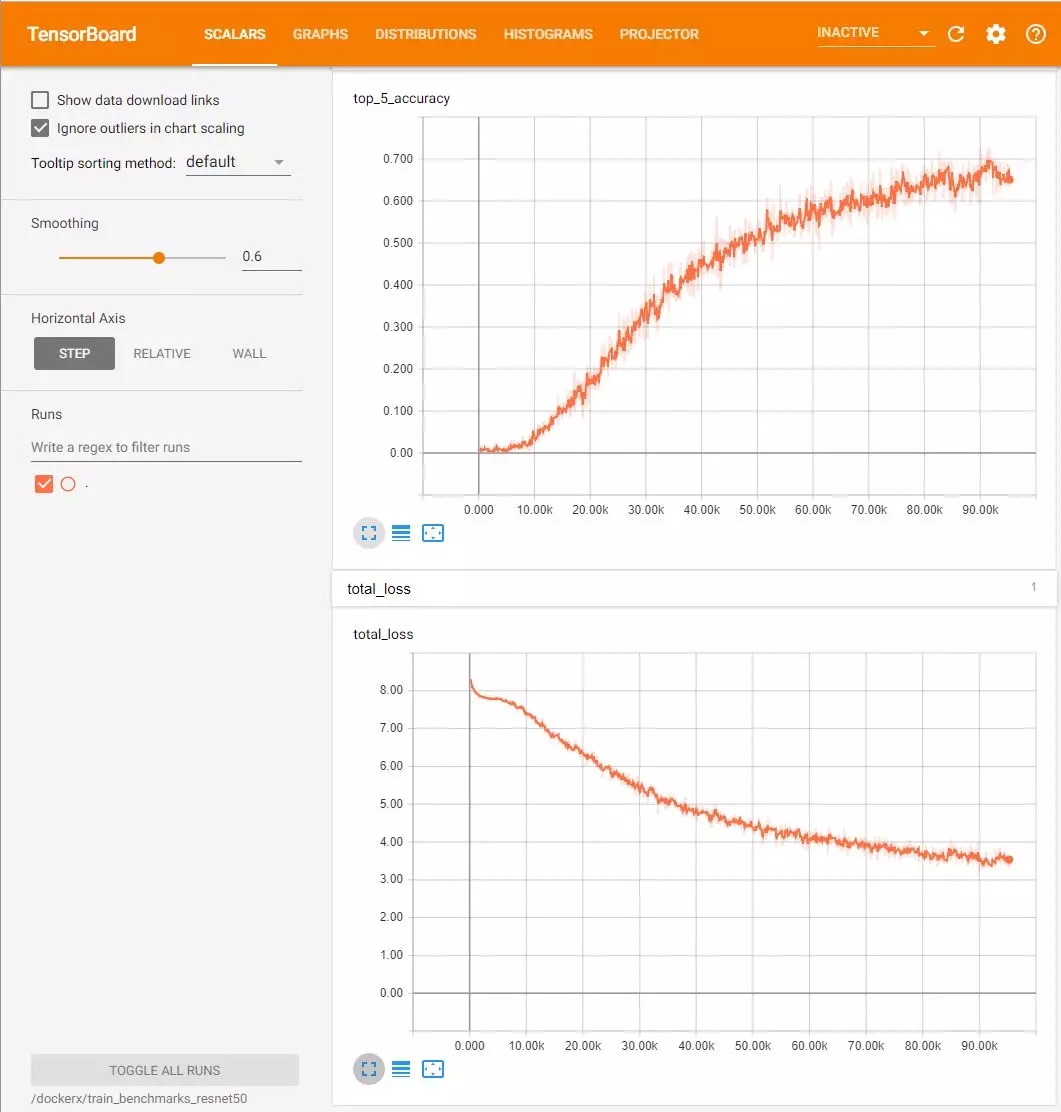
参考链接:
https://medium.com/tensorflow/amd-rocm-gpu-support-for-tensorflow-33c78cc6a6cf
声明:文章收集于网络,如有侵权,请联系小编及时处理,谢谢
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4800.html
摘要:诞生于年月份,年月份正式开源,多次,发布个版本,个组件,共计个单测,测试覆盖率。得益于的稳定,自发布第一个版本起,都没有破坏性的更新,本次发布的版本自然也没有破坏性的更新。因要支持低版本的,暂时并没有提供该功能。 vue-antd-ui是一个站在巨人(antd)肩膀上的UI组件库,有着其它组件库没有的优势,几乎继承了antd所有的功能特点,自带antd各种buff。 vue-antd-...
摘要:一直以来,的面向对象一般都是靠,但毕竟跟其它语言中的还是相差甚远的当然硬要实现也行,就是特麻烦,现在终于从语言层面实现了,鼓掌这实际上就是提供的方法,即把多个合并到一起,这下又多了一个抛弃的理由了 template string template string(模板字符串),至ES6,javascript终于也能直接往字符串里插变量了。这用途嘛,说大不大,说小也不小;虽说不能实现比较复...
摘要:年月下旬生活大爆炸政策原因搜狐视频无法播放下架。年月日,生活大爆炸第八季拿到许可证上线搜狐视频。年月日,生活大爆炸最后一集宣布正式杀青。播出十年的生活大爆炸季终集播出,谢耳朵终于向艾米求婚,网友喜大普奔。 本博客 猫叔的博客,转载请申明出处阅读本文约 4分钟适读人群:电视剧爱好者 《生活大爆炸》(英文:The Big Bang Theory 简称:TBBT),于2007年在哥伦比亚广播...

阅读 1283·2021-11-25 09:43
阅读 1652·2021-11-17 09:33
阅读 3290·2019-08-30 15:44
阅读 3650·2019-08-29 17:16
阅读 729·2019-08-28 18:20
阅读 2003·2019-08-26 13:54
阅读 824·2019-08-26 12:14
阅读 2459·2019-08-26 12:14




