
摘要:研究人员称,其提出的可以无监督地学习并迁移数据单元对之间的依赖关系和图形表征,并在自然语言处理和计算机视觉任务中取得了很好的效果。表自然语言处理任务中的模型简化测试。
近日,由卡耐基梅隆大学、纽约大学和 Facebook 的研究者杨植麟、Junbo Zhao 等人提交的论文将迁移学习向前推进了一步。研究人员称,其提出的 GLoMo 可以无监督地学习并迁移数据单元对之间的依赖关系和图形表征,并在自然语言处理和计算机视觉任务中取得了很好的效果。值得一提的是,该论文作者还包括何恺明、Ruslan Salakhutdinov 和 Yann LeCun 等人。
深度学习的进展很大程度上依赖于诸如卷积网络(CNN)[ 18 ] 和循环网络(RNN)[ 14 ] 之类的架构及注意力机制 [ 1 ]。这些架构虽然具有较高的表征能力,但由于其内置的「先天优势」,它们主要在网格状或顺序结构上运行。因此,CNN 和 RNN 在很大程度上依赖高表达能力来模拟复杂的结构现象,抵消了它们没有明确利用结构和图形表征的事实。
这种范式导致了迁移学习和预处理的标准化规范——在有监督或无监督的大数据集上拟合表达函数,然后将该函数应用到下游任务数据中进行特征提取。值得重视的例子包括预处理的 ImageNet 特征 [ 13 ] 和预处理的单词嵌入 [ 23,28 ]。
相比之下,现实世界中的各种数据显示出比简单的网格状或顺序结构更丰富的关系图结构。最近的其他类似研究也强调了这一点 [3]。例如在语言领域,语言学家使用解析树来表示单词之间的句法依赖性;信息检索系统利用知识图形反映实体关系;共指消解被设计成连接相同实体的不同表达式。因此,不管目标任务如何,这些示例性结构普遍存在于几乎任何自然语言数据中,这意味着跨任务迁移的可能性。这些观察也可以推广到其他领域,如计算机视觉。在 CV 领域里,像素之间关系的建模被证明是有用的 [ 27,49,43 ]。然而,还存在一个障碍,许多通用结构基本上是人为策划的,并且大规模获取成本高昂,而自动诱发的结构大多限于一项任务。
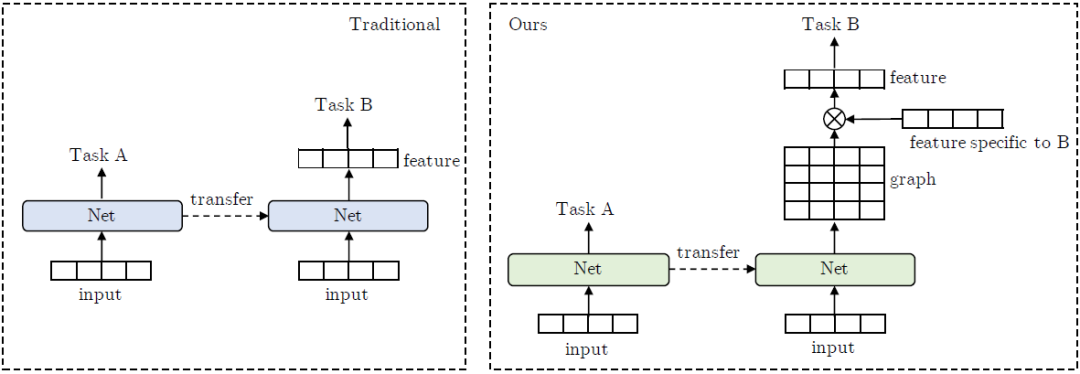
图 1:传统迁移学习与新迁移学习框架的对比。GLoMo 不是迁移特征,而是迁移网络输出的图形。图形与任务特定的特征(例如嵌入或隐藏状态)相乘,以产生结构感知特征。
在本文中,我们试图解决两个挑战: 1)打破基于特征的深度迁移学习的标准化规范;2)以数据驱动的方式学习数据中的通用结构。我们对学习可迁移隐藏关系图感兴趣,其中隐藏图的节点是输入单元,例如句子中的所有单词。隐藏关系图学习的任务是学习一个相似矩阵,其中权重(可能为零)捕获任意一对输入单元之间的依赖关系。
为了实现上述目标,我们提出了一种新的无监督隐藏图学习框架,称之为 GLoMo(Graphs from LOw-level unit MOdeling,低级单位建模图)。具体来说,我们从大规模的未标记数据中训练一个神经网络来输出隐藏图型,并将该网络迁移到提取下游任务的图结构来加强对它的训练。这种方法可以让我们把表示每个单元语义含义的特征和反映单元如何交互的图形分开。理想情况下,图形捕捉数据背后的任务无关结构,从而适用于不同的功能集。图 1 突出了传统的基于特征的迁移学习和新框架之间的差异。
实验结果表明,GLoMo 提高了问答、自然语言推理和情感分析等各种语言任务的性能。我们还证实,学习到的图形是通用的,可以用于未经过图形训练的各种特征集任务,包括 GloVe 嵌入 [28]、ELMo 嵌入 [ 29 ] 和任务特定的 RNN 状态。我们还确定了学习成功通用图的关键因素:解耦图和特征、分层图表征、稀疏性、单位级目标和序列预测。为了证明该框架的通用性,我们应用 GLoMo 来建模像素之间的关系依赖性,结果表明图像分类任务的性能获得改进。

图 2:GLoMo 方法概述。
在无监督学习阶段,特征预测器和图形预测器被一起训练以执行上下文预测。在迁移阶段,图形预测器被冻结并用于提取下游任务的图形。RNN 解码器应用于特征预测器中的所有位置,但是简单起见,我们仅指出了位置「A」处的一个。「Select one」表示图形可以迁移到下游任务模型中的任何层。「FF」指前馈网络。图形预测器输出的图用作「weighted sum」操作中的权重(参见等式 2)。
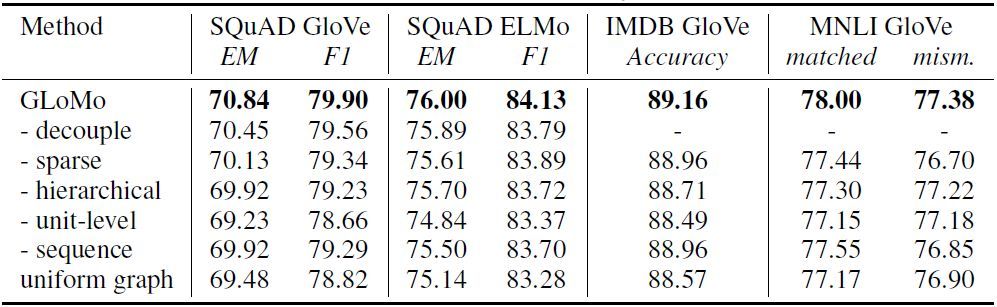
表 2:自然语言处理任务中的模型简化测试。
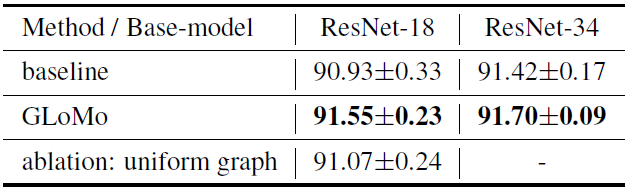
表 3:计算机视觉任务:CIFAR - 10 的分类结果。我们采用一个 42000 / 8000 的训练/验证拆分——一旦根据验证误差选择了较佳模型,我们就直接将其转发到测试集,而不进行任何验证集退回再训练。我们仅使用水平翻转来增加数据。上表中的结果是 5 轮实验的平均结果。
论文:GLoMo: Unsupervisedly Learned Relational Graphs as Transferable Representations

论文链接:https://arxiv.org/abs/1806.05662
摘要:现代深度迁移学习方法主要侧重于从一个任务中学习可迁移到其他任务的通用特征向量,例如语言中的单词嵌入和视觉中的预训练卷积特征。然而,这些方法通常迁移一元特征,却很大程度上忽略了更结构化的图形表征。本论文探索了从大规模未标记数据中学习捕获数据单元对(例如单词或像素)之间依赖关系的通用隐藏关系图,并将这些图传递给下游任务的可能性。我们提出的迁移学习框架提高了各种任务的性能,包括问答、自然语言推理、情感分析和图像分类。我们的测试还表明,学习到的图形是通用的,可以迁移到未经过图形训练的不同嵌入(包括 GloVe 嵌入、ELMo 嵌入和任务特定的 RNN 隐藏单元)或无嵌入单元(如图形像素)。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4796.html
摘要:人工智能的主流算法深度学习的历史,堪称也是深度学习三剑客和共同走过的年艰难而辉煌的不悔人生。之后使用一种称为监督学习的方法来训练感知器,以正确区分不同形状。表示,多层次神经网络的结构并不会使感知器强大到有实用价值。 人工智能的主流算法Deep Learning深度学习的历史,堪称Deep History, 也是深度学习三剑客Geoff Hinton, Yann LeCun 和Yoshua B...
摘要:年的深度学习研讨会,压轴大戏是关于深度学习未来的讨论。他认为,有潜力成为深度学习的下一个重点。认为这样的人工智能恐惧和奇点的讨论是一个巨大的牵引。 2015年ICML的深度学习研讨会,压轴大戏是关于深度学习未来的讨论。基于平衡考虑,组织方分别邀请了来自工业界和学术界的六位专家开展这次圆桌讨论。组织者之一Kyunghyun Cho(Bengio的博士后)在飞机上凭记忆写下本文总结了讨论的内容,...
摘要:最近,这就是街舞第二季开播,又一次燃起了全民热舞的风潮。然而,真要自己跳起来,实际与想象之间,估计差了若干个罗志祥。系统映射结果展示对于系统的结果,研究人员表示还不完美。谷歌在和跳舞的结合上也花了心思。好了,先不说了,我要去跟学跳舞了。 最近,《这!就是街舞》第二季开播,又一次燃起了全民热舞的风潮。 刚开播没多久,这个全程高能的节目,就在豆瓣上就得到了 9.6 的高分。舞者们在比赛中精...
摘要:近年来,深度学习在计算机感知自然语言处理和控制方面取得了重大进展。位列新泽西州的发明家名人堂,并获得年神经网络先锋奖年杰出研究奖年终身成就奖和来自墨西哥的名誉博士学位。 Yann Lecun是卷积网络模型的发明者,该模型被广泛地应用于模式识别应用中,因此他也被称为卷积网络之父,是公认的世界人工智能三巨头之一。 2018年11月08日,他来到加州大学圣巴巴拉分校,为在场师生作了一场关于自监督学...
摘要:图神经网络是近年发展起来的一个很有前景的深度学习方向,也是一种强大的图点云和流形表示学习方法。地址基于的几何深度学习扩展库是一个基于的几何深度学习扩展库,用于不规则结构输入数据,例如图点云和流形。与相比,训练模型的速度快了倍。 过去十年来,深度学习方法(例如卷积神经网络和递归神经网络)在许多领域取得了前所未有的成就,例如计算机视觉和语音识别。研究者主要将深度学习方法应用于欧氏结构数据 (Eu...

阅读 3673·2023-04-25 19:39
阅读 4019·2021-11-18 13:12
阅读 3799·2021-09-22 15:45
阅读 2607·2021-09-22 15:32
阅读 1006·2021-09-04 16:40
阅读 4123·2019-08-30 14:11
阅读 2048·2019-08-30 13:46
阅读 1734·2019-08-29 15:43






