
摘要:近日,谷歌大脑发布了一篇全面梳理的论文,该研究从损失函数对抗架构正则化归一化和度量方法等几大方向整理生成对抗网络的特性与变体。他们首先定义了全景图损失函数归一化和正则化方案,以及最常用架构的集合。
近日,谷歌大脑发布了一篇全面梳理 GAN 的论文,该研究从损失函数、对抗架构、正则化、归一化和度量方法等几大方向整理生成对抗网络的特性与变体。作者们复现了当前较佳的模型并公平地对比与探索 GAN 的整个研究图景,此外研究者在 TensorFlow Hub 和 GitHub 也分别提供了预训练模型与对比结果。
深度生成模型可以应用到学习目标分布的任务上。它们近期在多种应用中发挥作用,展示了在自然图像处理上的巨大潜力。生成对抗网络(GAN)是主要的以无监督方式学习此类模型的方法之一。GAN 框架可以看作是一个两人博弈,其中第一个玩家生成器学习变换某些简单的输入分布(通常是标准的多变量正态分布或均匀分布)到图像空间上的分布,使得第二个玩家判别器无法确定样本术语真实分布或合成分布。双方都试图最小化各自的损失,博弈的最终解是纳什均衡,其中没有任何玩家能单方面地优化损失。GAN 框架一般可以通过最小化模型分布和真实分布之间的统计差异导出。
训练 GAN 需要在生成器和判别器的参数上求解一个极小极大问题。由于生成器和判别器通常被参数化为深度卷积神经网络,这个极小极大问题在实践中非常困难。结果,人们提出了过多的损失函数、正则化方法、归一化方案和神经架构。某些方法基于理论洞察导出,其它的由实践考虑所启发。
在本文中谷歌大脑提供了对这些方法的全面的经验分析,作为研究员和从业者在这个领域的引导。他们首先定义了 GAN 全景图(GAN landscape):损失函数、归一化和正则化方案,以及最常用架构的集合。他们在多个现代大规模数据集上通过超参数优化探索了这个搜索空间,考虑了文献中报告的「好」超参集合,以及由高斯过程回归得到的超参集合。通过分析损失函数的影响,他们总结出非饱和损失 [9] 在各种数据集、架构和超参上足够稳定。接着,研究者分析了不同归一化和正则化方案,以及不同架构的影响。结果表明梯度惩罚 [10] 以及谱归一化 [20] 在高深度架构中都很有用。然后他们证实我们可以同时使用正则化和归一化来改善模型。最后,他们讨论了常见陷阱、复现问题和实践考虑。研究者提供了所有参考实现,包括 GitHub 上的训练和评估代码,并在 TensorFlow Hub 上提供了预训练模型。
Github:http://www.github.com/google/compare_gan
TensorFlow Hub:http://www.tensorflow.org/hub
论文:The GAN Landscape: Losses, Architectures, Regularization, and Normalization

论文地址:https://arxiv.org/abs/1807.04720
摘要:生成对抗网络(GAN)是一类以无监督方式学习目标分布的深度生成模型。虽然它们已成功应用到很多问题上,但训练 GAN 是很困难的并需要大量的超参数调整、神经架构工程和很多的「技巧」。在许多实际应用中的成功伴随着量化度量 GAN 失败模式的缺失,导致提出了过多的损失函数、正则化方法、归一化方案以及神经架构。在这篇论文中我们将从实践的角度清醒地认识当前的 GAN 研究现状。我们复现了当前较佳的模型并公平地探索 GAN 的整个研究图景。我们讨论了常见的陷阱和复现问题,在 GitHub 开源了我们的项目,并在 TensorFlow Hub 上提供了我们的预训练模型。
2 GAN 全景图
在这一章节中,作者主要总结了 GAN 的各种变体与技术,详细内容可参考该论文与各种 GAN 变体的原论文。作者主要从损失函数、判别器的正则化与归一化、生成器与判别器的架构、评估度量与数据集等 5 个方面讨论了各种不同的技术。
其中在损失函数中,作者讨论了原版 GAN 的 JS 距离、WGAN 的 Wasserstein 距离和最小二乘等损失函数。而判别器的正则化主要为梯度范数罚项,例如在 WGAN 中,这种梯度范数惩罚主要体现在对违反 1-Lipschitzness 平滑的软惩罚。此外,模型还能根据数据流形评估梯度范数惩罚,并鼓励判别器在该数据流形上成分段线性。判别器的归一化主要体现在最优化与表征上,即归一化能获得更高效的梯度流与更稳点的优化过程,以及修正各权重矩阵的谱结构而获得更更丰富的层级特征。
研究者主要探讨了两种生成器与判别器架构,包括深度卷积生成对抗网络与残差网络。其中深度卷积生成对抗网络的生成器与判别器分别包含 5 个卷积层,且带有谱归一化的变体称为 SNDCGAN。而 ResNet19 的生成器包含 5 个残差模块,判别器包含 6 个残差模块。
随后的评估度量则主要包含四种,包括 Inception Score (IS)、Frechet Inception Distance (FID) 和 Kernel Inception distance (KID) 等,它们都提供生成样本质量的定量分析。最后研究者考虑了三种数据集,并在上面测试各种 GAN 的生成效果。这些数据集包括 CIFAR10、CELEBA-HQ-128 和 LSUN-BEDROOM。
GAN 的搜索空间可能非常巨大:探索所有包含各种损失函数、正则化和归一化策略以及架构的组合超出了能力范围,因此在这一项研究中,研究者在几个数据集上分析了其中一些重要的组合。
作者在表 1a 中总结了近来在各项研究中展示「比较好」的参数。并且为了提供一个相对公平的对比,我们在表 1b 展示的超参数上执行高斯过程优化。
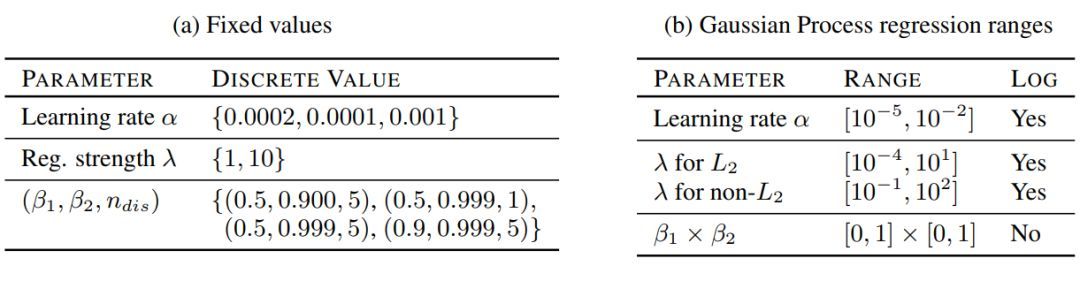
表 1:本研究中使用的超参数范围。固定值的笛卡尔乘积足够复现已有的结果。在 bandit setting[27] 中的高斯过程优化用于从特定范围中选择好的超参数集合。
3 结果和讨论
由于每个数据集都有四个主要成分(损失、架构、正则化、归一化)需要分析,探索完整的全景图是不可行的。因此,研究者选择了一个更加实际的方案:保持某些维度为固定值,并变化其它维度的值。在每个实验中重点关注三个方面:(1)top5% 已训练模型的 FID 分布;(2)对应的样本多样性分数;以及(3)计算开销(即训练的模型数量)和模型质量(FID 度量)之间的权衡。来自固定种子集的每个模型使用不同的随机种子训练 5 次,并报告中位数分数。由高斯过程回归得到的种子方差已经隐含地得到了处理,因此每个模型只需要训练一次。
3.1 损失函数的影响
这里损失函数是非饱和损失(NS),或者最小二乘损失(LS)[19],或者 Wasserstein 损失(WGAN)[2]。研究者使用了 ResNet19 作为生成器和判别器架构,架构细节在表 3a 中。本研究中考虑了最主要的归一化和正则化方法:梯度惩罚 [10] 和谱归一化 [20]。两项研究都使用了表 1a 中的超参数设置,并在 CELEBA-HQ-128 和 LSUN-BEDROOM 数据集上进行实验。
结果如图 2 所示。可以观察到,非饱和损失在两个数据集上都是稳定的。谱归一化在两个数据集上都提高了模型质量。类似地,梯度惩罚可以帮助提高模型质量,但寻找好的正则化权衡比较困难,需要大量的计算开销。使用 GP 惩罚的模型对判别器和生成器更新有改善的比例是 5:1,正如文献 [10] 所提到的。

图 1:非饱和损失在两个数据集上都是稳定的。梯度惩罚和谱归一化改善了模型质量。从计算开销的角度(即需要训练多少个模型已达到特定的 FID),谱归一化和梯度惩罚相比基线方法的表现更好,但前者更加高效。
3.2 正则化与归一化的影响
该研究的目的是对比文献中提到的各种正则化与归一化方法的表现。最终,研究者考虑批归一化(BN)、层归一化(LN)、谱归一化(SN)、梯度惩罚(GP)、Dragan 惩罚(DR)或者 L2 正则化。
这些方法的结果展示在图 2 中。可以观察到向判别器添加批归一化会损害最终表现。其次,梯度惩罚有所帮助,但训练不稳定。
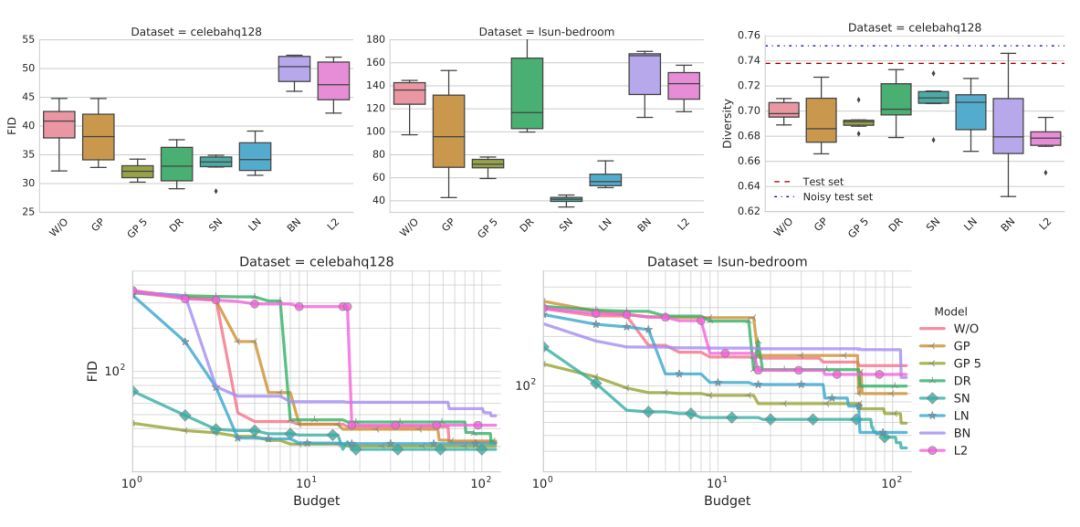
图 2:梯度惩罚和谱归一化表现都很好,也应被视为可行的方法。此外,后者的计算成本更低一些。不幸的是,两者都不能完全解决稳定性问题。
同时使用正则化和归一化的影响:
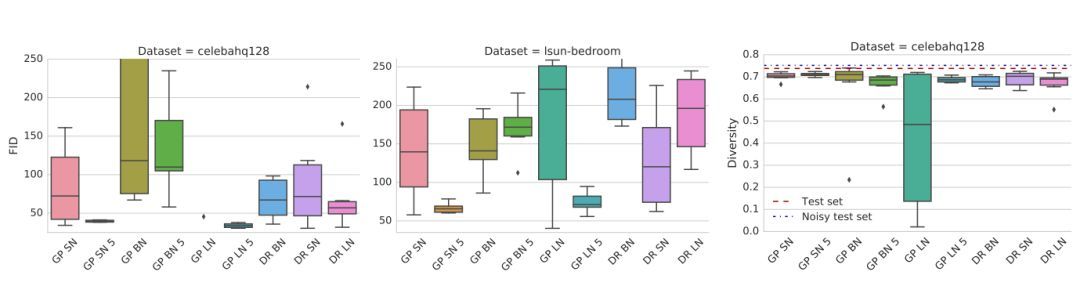
图 3:梯度惩罚配合谱归一化(SN)或者层归一化(LN)方法,能够极大地改进其表现。
3.3 生成器和判别器架构的影响
一个有趣的实际问题是:本研究的发现在不同的模型容量上是否一致。为了验证此问题,研究者选择了 DCGAN 类型的架构。在非饱和 GAN 损失、梯度惩罚和谱归一化下,同样完成了该研究。
结果如下图 4,可以观察到得益于正则化和归一化,两种架构都得到了相当好的结果。在两种架构上,使用谱归一化极大地超越了基线标准。

图 4:判别器和生成器架构对非饱和 GAN 损失的影响。频谱归一化与梯度惩罚都能改进非正则化基线模型的表现。
声明:文章收集于网络,如有侵权,请联系小编及时处理,谢谢!
商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4787.html
摘要:是世界上最重要的研究者之一,他在谷歌大脑的竞争对手,由和创立工作过不长的一段时间,今年月重返,建立了一个探索生成模型的新研究团队。机器学习系统可以在这些假的而非真实的医疗记录进行训练。今年月在推特上表示是的,我在月底离开,并回到谷歌大脑。 理查德·费曼去世后,他教室的黑板上留下这样一句话:我不能创造的东西,我就不理解。(What I cannot create, I do not under...
摘要:我仍然用了一些时间才从神经科学转向机器学习。当我到了该读博的时候,我很难在的神经科学和的机器学习之间做出选择。 1.你学习机器学习的历程是什么?在学习机器学习时你最喜欢的书是什么?你遇到过什么死胡同吗?我学习机器学习的道路是漫长而曲折的。读高中时,我兴趣广泛,大部分和数学或科学没有太多关系。我用语音字母表编造了我自己的语言,我参加了很多创意写作和文学课程。高中毕业后,我进了大学,尽管我不想去...
摘要:二是精度查全率和得分,用来衡量判别式模型的质量。精度查全率和团队还用他们的三角形数据集,测试了样本量为时,大范围搜索超参数来进行计算的精度和查全率。 从2014年诞生至今,生成对抗网络(GAN)热度只增不减,各种各样的变体层出不穷。有位名叫Avinash Hindupur的国际友人建立了一个GAN Zoo,他的动物园里目前已经收集了多达214种有名有姓的GAN。DeepMind研究员们甚至将...
摘要:据报道,生成对抗网络的创造者,前谷歌大脑著名科学家刚刚正式宣布加盟苹果。他将在苹果公司领导一个机器学习特殊项目组。在加盟苹果后会带来哪些新的技术突破或许我们很快就会看到了。 据 CNBC 报道,生成对抗网络(GAN)的创造者,前谷歌大脑著名科学家 Ian Goodfellow 刚刚正式宣布加盟苹果。他将在苹果公司领导一个「机器学习特殊项目组」。虽然苹果此前已经缩小了自动驾驶汽车研究的规模,但...
摘要:生成式对抗网络简称将成为深度学习的下一个热点,它将改变我们认知世界的方式。配图针对三年级学生的对抗式训练属于你的最严厉的批评家五年前,我在哥伦比亚大学举行的一场橄榄球比赛中伤到了自己的头部,导致我右半身腰部以上瘫痪。 本文作者 Nikolai Yakovenko 毕业于哥伦比亚大学,目前是 Google 的工程师,致力于构建人工智能系统,专注于语言处理、文本分类、解析与生成。生成式对抗网络—...

阅读 3117·2021-11-15 18:14
阅读 1772·2021-09-22 10:51
阅读 3280·2021-09-09 09:34
阅读 3504·2021-09-06 15:02
阅读 1012·2021-09-01 11:40
阅读 3185·2019-08-30 13:58
阅读 2523·2019-08-30 11:04
阅读 1081·2019-08-28 18:31






