
摘要:到目前为止我们依然遗留了一个对在单机上使用深度学习框架来说最重要的问题如何利用,也包括利用多个进行训练。中使用对输入数据进行切分,使用合并多个卡上的计算结果。总结如何利用多个卡进行训练对复杂模型或是大规模数据集上的训练任务往往是必然的选择。
到目前为止我们依然遗留了一个对在单机上使用深度学习框架来说最重要 的问题:如何利用 GPU, 也包括利用多个 GPU 进行训练。深度学习模型的训练往往非常耗时,在较大数据集上训练或是训练复杂模型往往会借助于 GPU 强大的并行计算能力。 如何能够让模型运行在单个/多个 GPU 上,充分利用多个 GPU 卡的计算能力,且无需关注框架在多设备、多卡通信实现上的细节是这一篇要解决的问题。
这一篇我们以 RNN 语言模型为例。RNN 语言模型在 第三篇已经介绍过,这一篇我们维持原有的模型结构不变,在以下两处对第三节原有的例子进行改建:
1. 为 PaddleFluid 和 TensorFlow 模型添加上多 GPU 卡运行的支持。
2. 使用 TensorFlow 的 dataset API 为 TensorFlow 的 RNN 语言模型重写数据读取 部分,以提高 I/O 效率。
请注意,这一篇我们主要关于 如何利用多 GPU 卡进行训练,请尽量在有多 块 GPU 卡的机器上运行本节示例。
如何使用代码
本篇文章配套有完整可运行的代码, 请随时从 github [1] 上获取代码。代码包括以下几个文件:
在执行训练任务前,请首先进入 data 文件夹,在终端执行下面的命令进行训练数据下载以及预处理。
sh download.sh
在终端运行以下命令便可以使用默认结构和默认参数运行 PaddleFluid 训练序列标注模型。
python train_fluid_model.py
在终端运行以下命令便可以使用默认结构和默认参数运行 TensorFlow 训练序列标注模型。
python train_tf_model.py
数据并行与模型并行
这一篇我们仅考虑单机多设备情况,暂不考虑网络中的不同计算机。当我们单机上有多种计算设备(包括 CPU,多块不同的 GPU 卡),我们希望能够充分利用这些设备一起完成训练任务,常用的并行方式分为三种:
模型并行( model parallelism ):不同设备(GPU/CPU 等)负责网络模型的不同部分 例如,神经网络模型的不同网络层被分配到不同的设备,或者同一层内部的不同参数被分配到不同设备。
每个设备都只有一部分 模型;不同设备之间会产生通信开销 ;
神经网络的计算本身有一定的计算依赖,如果计算本身存在依赖无法并行进行,不同设备之间可能会产生等待。
数据并行( data parallelism ):不同的设备有同一个模型的多个副本,每个设备分配到不同的数据,然后将所有机器的计算结果按照某种方式合并。
每个计算设备都有一份完整的模型各自计算,指定某个设备作为 controller,将多个设备的计算结果进行合并;
在神经网络中,通常需要合并的是多个设备计算的梯度,梯度合并后再进行 clipping,计算正则,计算更新量,更新参数等步骤;
较大化计算效率的关键是尽可能降低串行避免计算设备的等待。
混合并行(Hybrid parallelism):既有模型并行,又有数据并行。
模型并行往往使用在模型大到单个计算设备已经无法存储整个模型(包括模型本身和计算过程中产生的中间结果)的场景,或是模型在计算上天然就存在多个 没有强计算依赖的部分,那么很自然的可以将这些没有计算依赖的部分放在不同设备上并行地进行计算。
然而,随着计算设备的不断增多,模型并行较难以一种通用的可扩展的方法达到接近线性加速的效果。一方面如何重叠(overlap)计算开销与跨设备通信开销依赖于对系统硬件丰富的知识和经验,另一方面神经网络计算的依赖性 会让模型的拆分随着设备的增加越发困难。
数据并行中每一个设备都维护了完整的模型,与模型并行相比往往会耗费更多的存储空间。但数据并行的优点是:通用性很好,适用于所有可能的神经网络模型结构。同样地,随着设备数目的增加通信代价也会越来越高,一般情况下在 2~8 卡时依然可以做到接近线性加速比。
需要注意的是,随着越来越多设备的加入,数据并行会导致 batch size 增大,一个 epoch 内参数更新次数减少,往往都需要对学习率,学习率 decay 进行再调参,否则可能会引起学习效果的下降。
鉴于在使用中的通用性和有效性,这一篇中我们主要介绍更加通用的数据并行方法。非常笼统的,数据并行遵从一下的流程,其中一个 | 代表一个计算设备:
| 1. 将模型参数拷贝到不同的设备
| 2. 对输入数据均匀切分到不同的计算设备
|||| 3. 多个设备并行进行前向计算
|||| 4. 多个设备形象进行反向计算
| 5. 多个设备计算的梯度在主卡合并
| 6. 计算参数更新量,更新参数
| to 1
PaddleFluid使用多GPU卡进行训练
在 PaddleFluid 中使用多个 GPU 卡以数据并行的方式训练需要引入 parallel_do 原语。顾名思义, parallel_do 会负责数据的切分,在多个设备上并行地执行一段相同的计算,最后合并计算结果。
与 ParallelDo 函数功能相近的函数还有 ParallelExecutor,大家也可以自行尝试一下。ParallelExecutor 的具体使用方式可以参考 API 文档:
http://www.paddlepaddle.org/docs/develop/api/fluid/en/executor.html
图 1 是 parallel_do 的原理示意图:
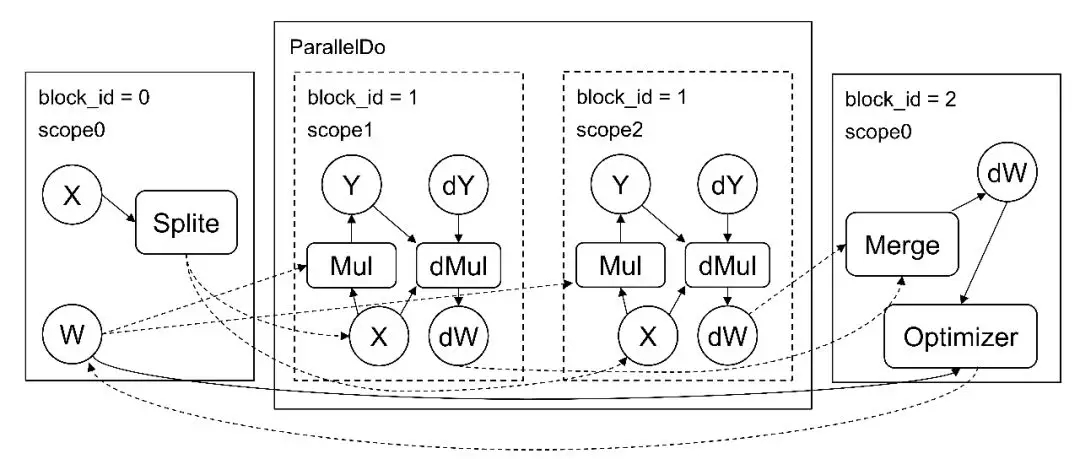
图1. PaddleFluid中的Parallel do
下面我们来看看如何使用 parallel_do 让我们在第三篇中实现的 RNN LM 可在多个 GPU 上训练 ,下面是核心代码片段,完整代码请参考 rnnlm_fluid.py。
places = fluid.layers.get_places()
pd = fluid.layers.ParallelDo(places)
with pd.do():
word_ = pd.read_input(word)
lbl_ = pd.read_input(lbl)
prediction, cost = self.__network(word_, lbl_)
pd.write_output(cost)
pd.write_output(prediction)
cost, prediction = pd()
avg_cost = fluid.layers.mean(x=cost)
调用 places = fluid.layers.get_places() 获取所有可用的计算设备 。可以通过设置 CUDA_VISIBLE_DEVICES 来控制可见 GPU 的数据。
pd = fluid.layers.ParallelDo(places) 指定将在 那些设备上并行地执行。
parallel_do 会构建一段 context,在其中定义要并行执行的计算,调用 pd.read_input 切分输入数据,在 parallel_do 的 context 之外调用 pd() 获取合并后的最终计算结果。
with pd.do():
x_ = pd.read_input(x) # 切分输入数据 x
y_ = pd.read_input(y) # 切分输入数据 y
# 定义网络
cost = network(x_, y_)
pd.write_output(cost)
cost = pd() # 获取合并后的计算结果
TensorFlow中使用多GPU卡进行训练
在 TensorFlow 中,通过调用 with tf.device() 创建一段 device context,在这段 context 中定义所需的计算,那么这 些计算将运行在指定的设备上。
TensorFlow 中实现多卡数据并行有多种方法,常用的包括单机 ParameterServer 模式;Tower 模式 [2],甚至也 可以使用的 nccl [3] all reduce 系列 op 来实现梯度的聚合。这里我们以 Tower 模式为基础,介绍一种简单易用的多 GPU 上的数据并行方式。下面是核心代码片段,完整代码请参考 rnnlm_tensorflow.py。
def make_parallel(fn, num_gpus, **kwargs):
in_splits = {}
for k, v in kwargs.items():
in_splits[k] = tf.split(v, num_gpus)
out_split = []
for i in range(num_gpus):
with tf.device(tf.DeviceSpec(device_type="GPU", device_index=i)):
with tf.variable_scope(
tf.get_variable_scope(), reuse=tf.AUTO_REUSE):
out_i = fn(**{k: v[i] for k, v in in_splits.items()})
out_split.append(out_i)
return tf.reduce_sum(tf.add_n(out_split)) / tf.to_float(
self.batch_size)
make_parallel 的第一个参数是一个函数,也就是我们自己定义的如何创建神经网络模型函数。第二个参数指定 GPU 卡数,数据将被平均地分配给这些 GPU。除此之外的参数将以 keyword argument 的形式传入,是神经网络的输入层 Tensor 。
在定义神经网络模型时,需要创建 varaiable_scope ,同时指定 reuse=tf.AUTO_REUSE ,保证多个 GPU 卡上的可学习参数会是共享的。
make_parallel 中使用 tf.split op 对输入数据 Tensor 进行切分,使用 tf.add_n 合并多个 GPU 卡上的计算结果。
一些情况下同样可以使用 tf.concat 来合并多个卡的结算结果,这里因为使用了 dataset api 为 dynamic rnn feed 数据,在定义计算图时 batch_size 和 max_sequence_length 均不确定,无法使用 tf.concat 。
下面是对 make_parallel 的调用,从中可看到如何使用 make_parallel 方法。
self.cost = self.make_parallel(
self.build_model,
len(get_available_gpus()),
curwd=curwd,
nxtwd=nxtwd,
seq_len=seq_len)
除了调用 make_parallel 之外,还有一处修改需要注意:在定义优化方法时,需要将 colocate_gradients_with_ops 设置为 True,保证前向 Op 和反向 Op 被放置在相同的设备上进行计算。
optimizer.minimize(self.cost, colocate_gradients_with_ops=True)
总结
如何利用多个 GPU 卡进行训练对复杂模型或是大规模数据集上的训练任务往往是必然的选择。鉴于在使用中的有效性和通用性,这一节我们主要介绍了在 PaddleFluid 和 TensorFlow 上通过数据并行使用多个 GPU 卡最简单的方法。
这一篇所有可运行的例子都可以在 04_rnnlm_data_parallelism [4] 找到,更多实现细节请参考具体的代码。值得注意的是,不论是 PaddleFluid 还是 TensorFlow 都还有其他多种利用多计算设备提高训练并行度的方法。请大家随时关注官方的文档。
参考文献
[1]. 本文配套代码
https://github.com/JohnRabbbit/TF2Fluid/tree/master/04_rnnlm_data_parallelism
[2]. Tower模式
https://github.com/tensorflow/models/blob/master/tutorials/image/cifar10/cifar10_multi_gpu_train.py
[3]. nccl
https://www.tensorflow.org/api_docs/python/tf/contrib/nccl
[4]. 04_rnnlm_data_parallelism
https://github.com/JohnRabbbit/TF2Fluid/tree/master/04_rnnlm_data_parallelism
声明:文章收集于网络,如有侵权,请联系小编及时处理,谢谢!
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4785.html

阅读 2659·2023-04-25 17:33
阅读 702·2021-11-23 09:51
阅读 3019·2021-07-30 15:32
阅读 1475·2019-08-29 18:40
阅读 2007·2019-08-28 18:19
阅读 1518·2019-08-26 13:48
阅读 2295·2019-08-23 16:48
阅读 2329·2019-08-23 15:56

