
摘要:首先第一种当然是在年提出的,它奠定了整个卷积神经网络的基础。其中局部感受野表示卷积核只关注图像的局部特征,而权重共享表示一个卷积核在整张图像上都使用相同的权值,最后的子采样即我们常用的池化操作,它可以精炼抽取的特征。
近日,微软亚洲研究院主办了一场关于 CVPR 2018 中国论文分享会,机器之心在分享会中发现了一篇非常有意思的论文,它介绍了一种新型卷积网络架构,并且相比于 DenseNet 能抽取更加精炼的特征。北大杨一博等研究者提出的这种 CliqueNet 不仅有前向的密集型连接,同时还有反向的密集型连接来精炼前面层级的信息。根据杨一博向机器之心介绍的 CliqueNet 以及我们对卷积架构的了解,我们将与各位读者纵览卷积网络的演变。
卷积架构
很多读者其实已经对各种卷积架构非常熟悉了,因此这一部分只简要介绍具有代表性的卷积结构与方法。首先第一种当然是 Yann LeCun 在 1998 年提出的 LeNet-5,它奠定了整个卷积神经网络的基础。正如 LeCun 在 LeNet-5 原论文中所说,卷积网络结合了三种关键性思想来确保模型对图像的平移、缩放和扭曲具有一定程度的不变性,这三种关键思想即局部感受野、权重共享和空间/时间子采样。其中局部感受野表示卷积核只关注图像的局部特征,而权重共享表示一个卷积核在整张图像上都使用相同的权值,最后的子采样即我们常用的池化操作,它可以精炼抽取的特征。
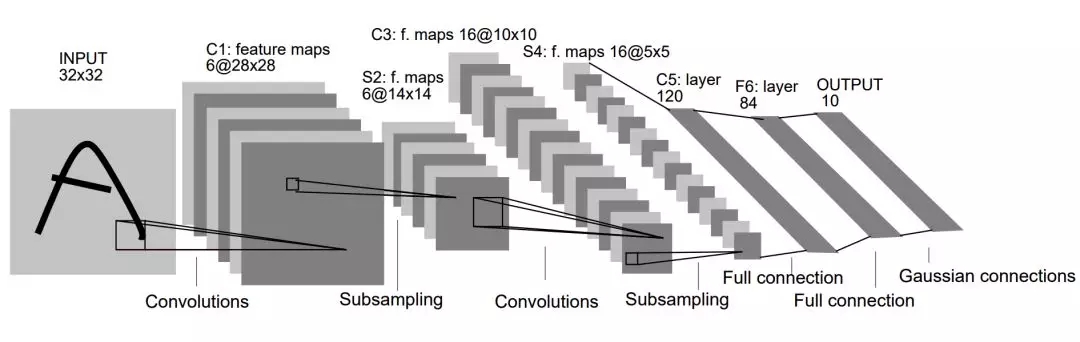
原论文:GradientBased Learning Applied to Document Recognition
上图是 LeNet-5 架构,它叠加了两个卷积层与池化层来抽取图像特征,然后再将抽取的特征传入两个全连接层以组合所有特征并识别图像类别。虽然 LeNet-5 很早就提出来了,且架构和现在很多简单的卷积网络非常相似,但当时可能限于计算资源和数据集等条件并没有得到广泛应用。
第一个得到广泛关注与应用的卷积神经网络是 2012 年提出来的 AlexNet,它相比于 LeNet-5 较大的特点是使用更深的卷积网络和 GPU 进行并行运算。如下所示,AlexNet 有 5 个卷积层和 3 个较大池化层,它可分为上下两个完全相同的分支,这两个分支在第三个卷积层和全连接层上可以相互交换信息。AlexNet 将卷积分为两个分支主要是因为需要在两块老式 GTX580 GPU 上加速训练,且单块 GPU 无法为深度网络提供足够的内存,因此研究者将网络分割为两部分,并馈送到两块 GPU 中。
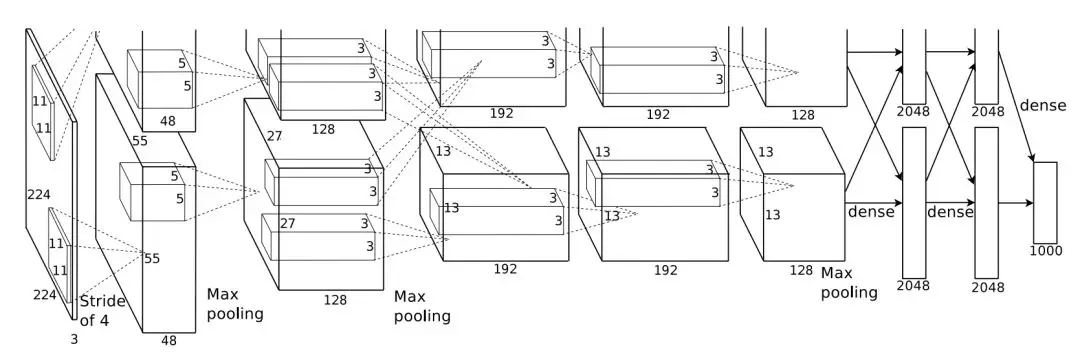
原论文:ImageNet Classification with Deep Convolutional Neural Networks
AlexNet 还应用了非常多的方法来提升模型性能,包括第一次使用 ReLU 非线性激活函数、第一次使用 Dropout 以及大量数据增强而实现网络的正则化。除此之外,AlexNet 还使用了带动量的随机梯度下降、L2 权重衰减以及 CNN 的集成方法,这些方法现在都成为了卷积网络不可缺少的模块。
到了 2014 年,牛津大学提出了另一种深度卷积网络 VGG-Net,它相比于 AlexNet 有更小的卷积核和更深的层级。AlexNet 前面几层用了 11*11 和 5*5 的卷积核以在图像上获取更大的感受野,而 VGG 采用更小的卷积核与更深的网络提升参数效率。一般而言,叠加几个小的卷积核可以获得与大卷积核相同的感受野,而叠加小卷积核使用的参数明显要少于一个大卷积核。此外,叠加小卷积核因为加深了卷积网络,能引入更强的非线性。
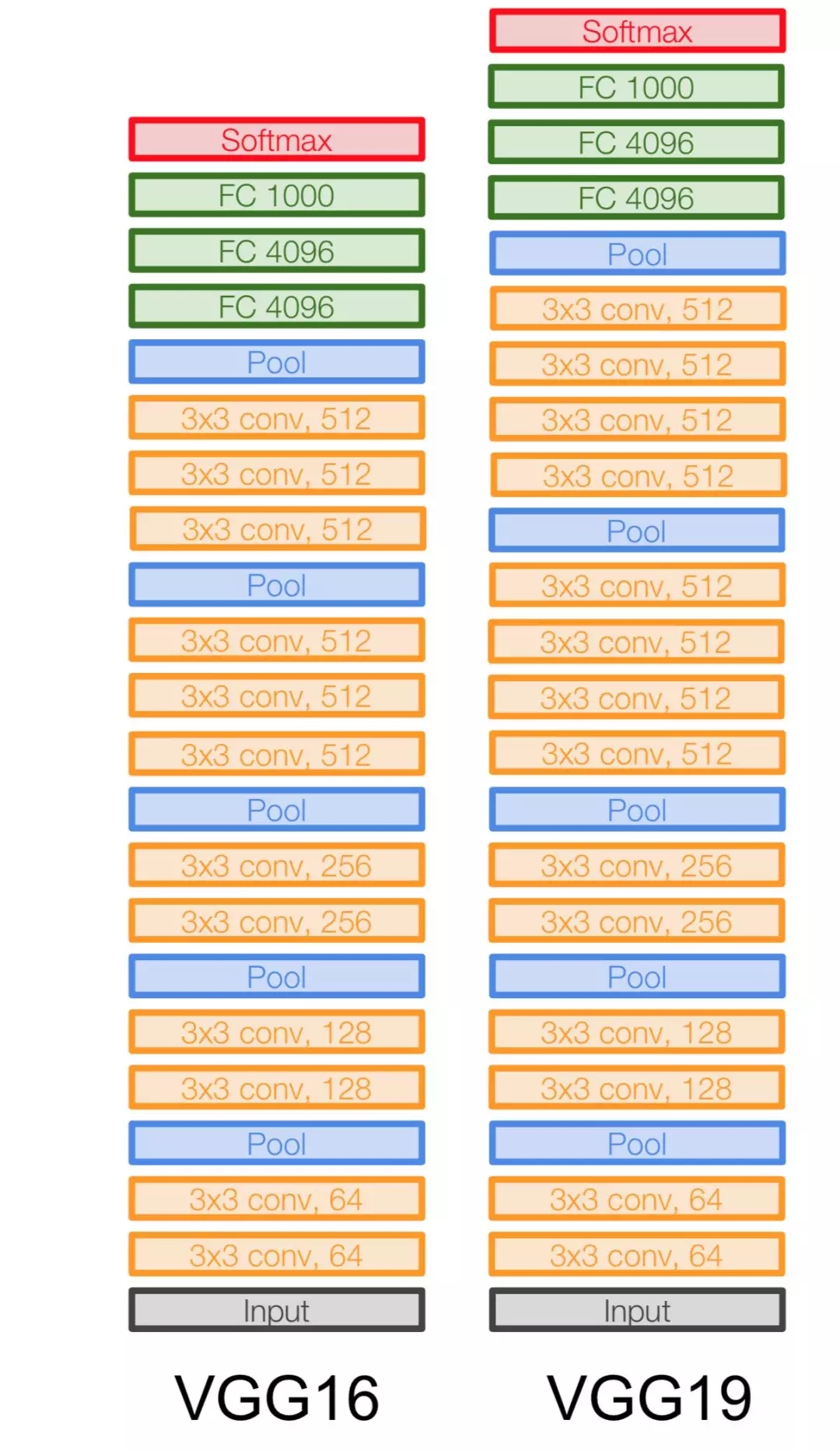
原论文:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
VGG-Net 的泛化性能较好,常用于图像特征的抽取目标检测候选框生成等。VGG 较大的问题就在于参数数量,VGG-19 基本上是参数量最多的卷积网络架构。VGG-Net 的参数主要出现在后面两个全连接层,每一层都有 4096 个神经元,可想而至这之间的参数会有多么庞大。
同样在 2014 年,谷歌提出了 GoogLeNet(或 Inception-v1)。该网络共有 22 层,且包含了非常高效的 Inception 模块,它没有如同 VGG-Net 那样大量使用全连接网络,因此参数量非常小。GoogLeNet 较大的特点就是使用了 Inception 模块,它的目的是设计一种具有优良局部拓扑结构的网络,即对输入图像并行地执行多个卷积运算或池化操作,并将所有输出结果拼接为一个非常深的特征图。因为 1*1、3*3 或 5*5 等不同的卷积运算与池化操作可以获得输入图像的不同信息,并行处理这些运算并结合所有结果将获得更好的图像表征。
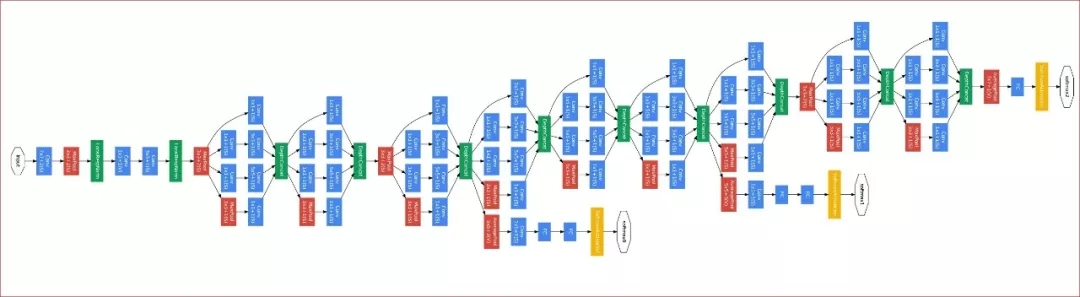
原论文:Going Deeper with Convolutions
一般 Inception 模块的参数虽然少,但很多并行的卷积运算需要很多计算量。直接拼接不同的卷积运算会产生巨量的运算,因此修正的 Inception 模块每一个卷积分支都会先执行一个 1*1 的卷积将通道数大大减少,这也相当于对输入数据进行降维而简化运算。此外,GoogLeNet 中间多出来的两个分类网络主要是为了向前面的卷积与 Inception 模块提供额外的梯度进行训练。因为随着网络的加深,梯度无法高效地由后向前传,网络参数也就得不到更新。这样的分支则能减轻深度网络的梯度传播问题,但这种修补并不优美,也不能解决更深网络的学习问题。
最后,何恺明等人于 2015 年提出来的深度残差网络骤然将网络深度由十几二十层提升到上百层。ResNet 较大的特点即解决了反向传播过程中的梯度消失问题,因此它可以训练非常深的网络而不用像 GoogLeNet 那样在中间添加分类网络以提供额外的梯度。根据 ResNet 原论文,设计的出发点即更深的网络相对于较浅的网络不能产生更高的训练误差,因此研究者引入了残差连接以实现这样的能力。

原论文:Deep Residual Learning for Image Recognition
如上黑色曲线,ResNet 引入了残差连接。在每一个残差模块上,残差连接会将该模块的输入与输出直接相加。因此在反向传播中,根据残差连接传递的梯度就可以不经过残差模块内部的多个卷积层,因而能为前一层保留足够的梯度信息。此外,每一个残差模块还可以如同 Inception 模块那样添加 1×1 卷积而形成瓶颈层。这样的瓶颈结构对输入先执行降维再进行卷积运算,运算完后对卷积结果升维以恢复与输入相同的维度,这样在低维特征上进行计算能节省很多计算量。
DenseNet
ResNet 虽然非常高效,但如此深的网络并不是每一层都是有效的。最近一些研究表明 ResNet 中的很多层级实际上对整体的贡献非常小,即使我们在训练中随机丢弃一些层级也不会有很大的影响。这种卷积层和特征图的冗余将降低模型的参数效率,并加大计算力的需求。为此,Gao Huang 等研究者提出了 DenseNet,该论文获得了 CVPR 2017 的较佳论文。
DenseNet 的目标是提升网络层级间信息流与梯度流的效率,并提高参数效率。它也如同 ResNet 那样连接前层特征图与后层特征图,但 DenseNet 并不会像 ResNet 那样对两个特征图求和,而是直接将特征图按深度相互拼接在一起。DenseNet 较大的特点即每一层的输出都会作为后面所有层的输入,这样最后一层将拼接前面所有层级的输出特征图。这种结构确保了每一层能从损失函数直接访问到梯度,因此可以训练非常深的网络。
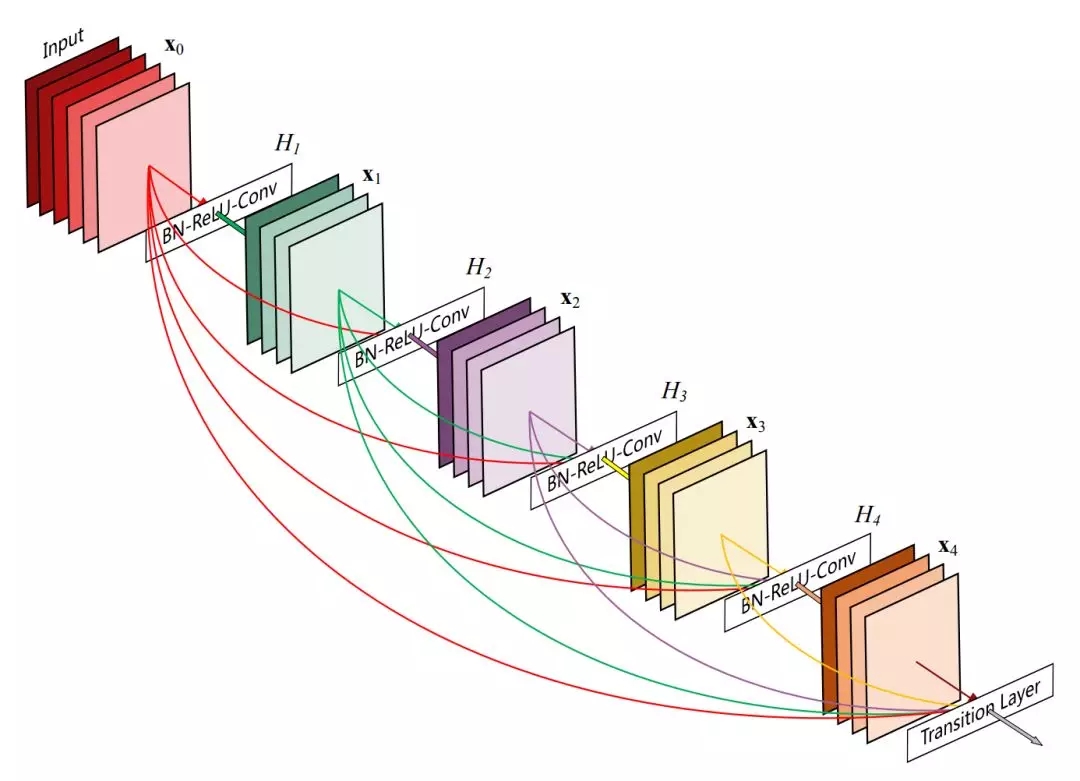
原论文:Densely Connected Convolutional Networks
如上所示为 Dense Block 的结构,特征图 X_2 在输入 X_0 与 X_1 的条件下执行卷积运算得出,同时 X_2 会作为计算 X_3 和 X_4 的输入。一般对于 L 层的 DenseNet,第 l 层有 l 个输入特征图和 L-l 个输出特征图,因此它一共拥有 L(L+1)/2 个连接。这种密集连接型的网络也就形象地称为 DenseNet 了。
此外,Gao Huang 等研究者在原论文表示 DenseNet 所需要的参数更少,因为它相对于传统卷积网络不需要重新学习冗余的特征图。具体来说,DenseNet 的每一层都有非常浅的特征图或非常少的卷积核,例如 12、24、32 等,因此能节省很多网络参数。
又因为每一层输出的特征图都比较浅,所以每一层都能将前面所有层级的特征图拼接为一个较深的特征图而作为输入,这样每一层也就复用了前面的特征图。特征图的复用能产生更紧凑的模型,且拼接由不同层产生的特征图能提升输入的方差和效率。
形式化来说,若给定一张图像 x_0 馈送到 L 层的 DenseNet 中,且 H_l() 表示第 l 层包含卷积、池化、BN 和激活函数等的非线性变换,那么第 l 层的输出可以表示为 X_l。对于 DenseNet 的密集型连接,第 l 层的输出特征图可以表示为:
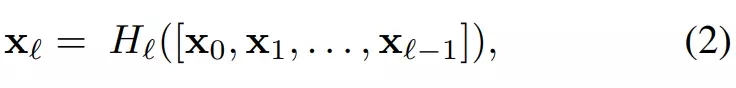
其中 [x_0, x_1, . . . , x_{−1}] 表示从 0 到 l-1 层产生的特征图,为了简化计算,它们会按深度拼接为单个张量。在原论文的实现中,H_l() 为包含了三个模块的复合函数,即先执行批量归一化和 ReLU 激活函数,再执行 1 个 3×3 的卷积。
上述方程若想将特征图按深度拼接,那么所有特征图的尺寸就需要相等。一般常用的方法是控制卷积核的移动步幅或添加池化运算,DenseNet 将网络分为不同的 Dense Block,并在 Dense Block 之间调整特征图的大小。

如上所示,密集连接块之间的转换层会通过卷积改变特征图深度,通过池化层改变特征图尺寸。在原论文的实现中,转换层先后使用了批量归一化、1×1 的逐点卷积和 2×2 的平均池化。
此外,若 Dense Block 中的 H_l 输出 k 张特征图,那么第 l 层的输入特征图就有 k_0 + k × (l - 1) 张,其中 k_0 为输入图像的通道数。由于输入特征图的深度或张数取决于 k,DenseNet 每一个卷积都有比较浅的特征图,即 k 值很小。在 ImageNet 中,DenseNet 的 k 值设为了 32。
不过尽管 k 值比较小,但在后面层级的卷积运算中,输入的特征图深度还是非常深的。因此与 ResNet 的残差模块和 GoogLeNet 的 Inception 模块一样,DenseNet 同样在 3×3 卷积运算前加入了 1×1 逐点卷积作为瓶颈层来减少输入特征图的深度。因此我们可以将 H_l 由原版的 BN-ReLU-Conv(3×3) 修正为:BN-ReLU-Conv(1× 1)-BN-ReLU-Conv(3×3)。除了加入瓶颈层,DenseBlock 间的转换层也可以通过 1×1 卷积减低特征图的维度。
以下表格是 DenseNet 在 ImageNet 数据集上所采用的架构,其中每个卷积层的卷积核数 k=32,「conv」层对应于原版 H_l 或添加了瓶颈层的 H_l。
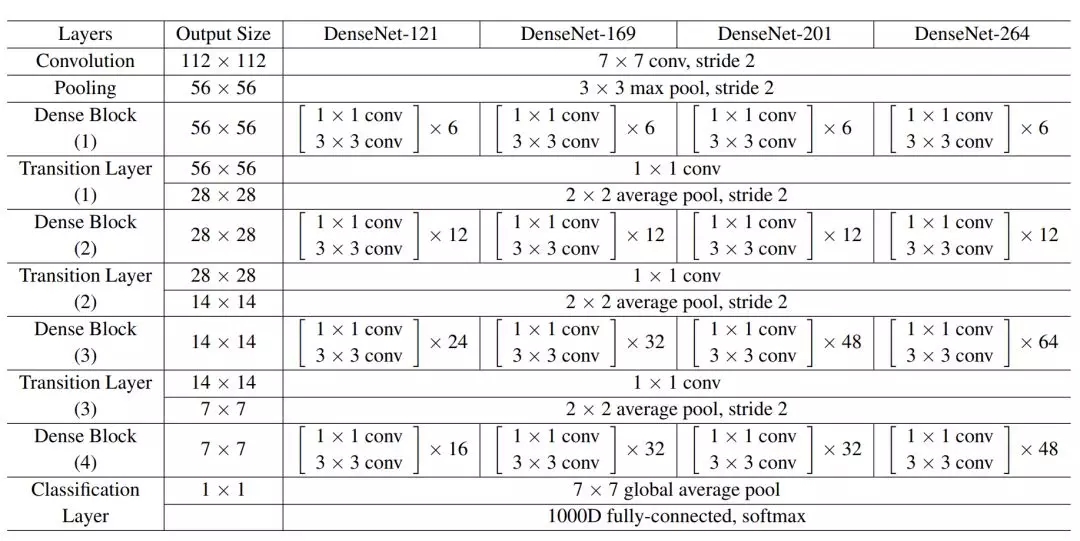
在实践中,很多研究者都表示 DenseNet 的参数虽然少,但显存占用非常恐怖。这主要是因为大量的特征图拼接操作和 BN 运算结果都会占用新的显存,不过现在已经有研究者修改代码而降低显存占用。此外,DenseNet 的计算量也非常大,很难做到实时语义分割等任务。
CliqueNet
DenseNet 通过复用不同层级的特征图,减少了不同层间的相互依赖性,且最终的预测会利用所有层的信息而提升模型鲁棒性。但是 Yunpeng Chen 等研究者在论文 Dual Path Networks 中表示随着网络深度的增加,DenseNet 中的密集型连接路径会线性地增加,因此参数会急剧地增加。这就导致了在不特定优化实现代码的情况下需要消耗大量的 GPU 显存。而在北大杨一博等研究者提出来的 CliqueNet 中,每个 Clique Block 只有固定通道数的特征图会馈送到下一个 Clique Block,这样就大大增加了参数效率。
CliqueNet 较大的特点是其不仅有前传的部分,同时还能根据后面层级的输出对前面层级的特征图做优化。这种网络架构受到了循环结构与注意力机制的启发,即卷积输出的特征图可重复使用,经过精炼的特征图将注意更重要的信息。在同一个 Clique 模块内,任意两层间都有前向和反向连接,这也就提升了深度网络中的信息流。
论文:Convolutional Neural Networks with Alternately Updated Clique
论文地址:https://arxiv.org/abs/1802.10419
实现地址:https://github.com/iboing/CliqueNet
CliqueNet 的每一个模块可分为多个阶段,但更高的阶段需要更大的计算成本,因此该论文只讨论两个阶段。第一个阶段如同 DenseNet 那样传播,这可以视为初始化过程。而第二个阶段如下图所示每一个卷积运算的输入不仅包括前面所有层的输出特征图,同样还包括后面层级的输出特征图。第二阶段中的循环反馈结构会利用更高级视觉信息精炼前面层级的卷积核,因而能实现空间注意力的效果。

如上所示在第一阶段中,若输入 0、1、2 号特征图的拼接张量,卷积运算可得出特征图 3。在第二阶段中,特征图 1 会根据第一阶段输出的 2、3、4 号拼接特征图计算得出,我们可将其称为已更新特征图 1。第二阶段的特征图 3 在输入第一阶段的输出特征图 4 和已更新特征图 1、2 的情况下得出。
由此可以看出,每一步更新时,都利用最后得到的几个特征图去精炼相对最早得到的特征图。因为最后得到的特征图相对包含更高阶的视觉信息,所以该方法用交替的方式,实现了对各个层级特征图的精炼。
Clique Block 中的第一阶段比较好理解,与上文 Dense Block 的前向传播相同。可能读者对第二阶段的传播过程仍然有些难以理解,不过原论文中给出了一个很好的表达式来描述第 2 阶段。对于第二阶段中的第 i 层和第 k 个循环,交替更新的表达式为:

如上所示有两套卷积核,即阶段 2 中的前向卷积运算与反向卷积运算。每一套卷积核参数在不同阶段中是共享的。
对于有五个卷积层的 Clique Block,传播方式如下表所示。其中 W_ij 表示 X_i 到 X_j 的参数,它在不同阶段可以重复利用和更新,「{}」表示拼接操作。
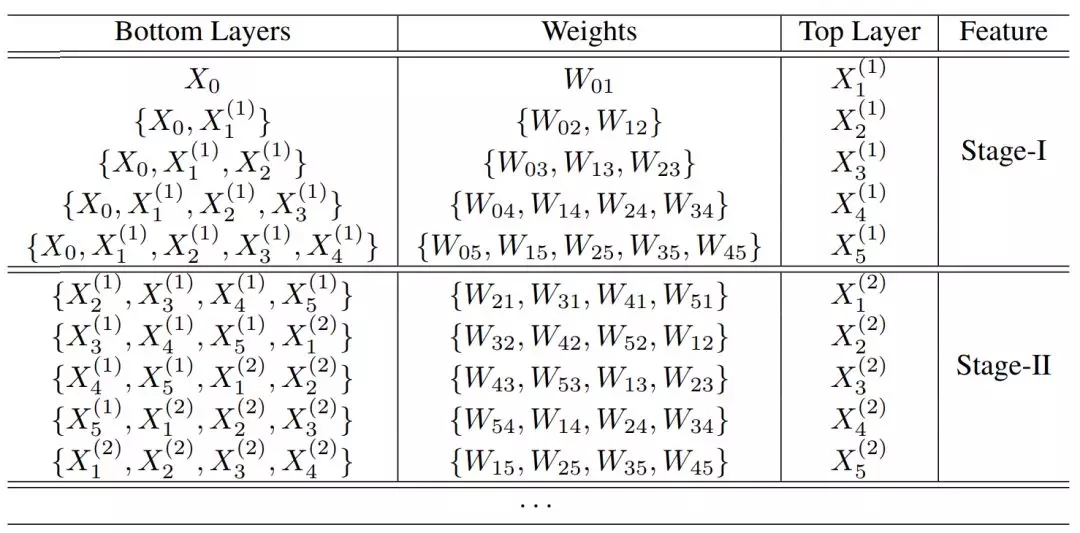
如上所示,第一阶段的输出特征图都是拼接前面层级的特征图 X^1 和输入数据 X_0 ,并做对应的卷积运算而得出。第二阶段的输出特征图会拼接前面层级更新过的特征图 X^2 与第一阶段的特征图 X^1 而得出。
除了特征图的复用与精炼外,CliqueNet 还采用了一种多尺度的特征策略来避免参数的快速增长。具体如下所示我们将每一个 Block 的输入特征图与输出特征图拼接在一起,并做全局池化以得到一个向量。将所有 Block 的全局池化结果拼接在一起就能执行最后的预测。由于损失函数是根据所有 Block 结果计算得出,那么各个 Block 就能直接访问梯度信息。
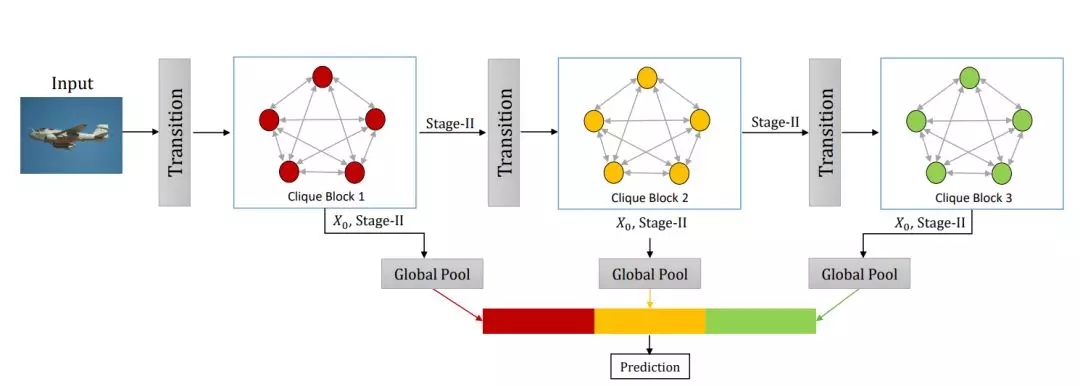
此外,由于每一个 Block 只有第二阶段的输出会作为下一个 Block 的输入,因此 Block 的特征图维度也不会超线性的增加,从而具有参数量和计算量上的优势。
如下所示为 CliqueNet 的关键代码,build_model 函数会先构建 3 个 Clique Block,并将它们全局池化的结果传入列表中。最终的特征即使用 tf.concat() 函数将所有池化结果拼接在一起,且在进行一个线性变换后可传入 Softmax 函数获得类别的预测概率。
import tensorflow as tf
from utils import *
block_num=3
def build_model(input_images, k, T, label_num, is_train, keep_prob, if_a, if_b, if_c):
current=first_transit(input_images, channels=64, strides=1, with_biase=False)
current_list=[]
## build blocks
for i in range(block_num):
block_feature, transit_feature = loop_block_I_II(current, if_b, channels_per_layer=k, layer_num=T/3, is_train=is_train, keep_prob=keep_prob, block_name="b"+str(i))
if if_c==True:
block_feature=compress(block_feature, is_train=is_train, keep_prob=keep_prob, name="com"+str(i))
current_list.append(global_pool(block_feature, is_train))
if i==block_num-1:
break
current=transition(transit_feature, if_a, is_train=is_train, keep_prob=keep_prob, name="tran"+str(i))
## final feature
final_feature=current_list[0]
for block_id in range(len(current_list)-1):
final_feature=tf.concat((final_feature, current_list[block_id+1]),
axis=3)
feature_length=final_feature.get_shape().as_list()[-1]
print "final feature length:",feature_length
feature_flatten=tf.reshape(final_feature, [-1, feature_length])
## final_fc
Wfc=tf.get_variable(name="FC_W", shape=[feature_length, label_num], initializer=tf.contrib.layers.xavier_initializer())
bfc=tf.get_variable(name="FC_b", initializer=tf.constant(0.0, shape=[label_num]))
logits=tf.matmul(feature_flatten, Wfc)+bfc
prob=tf.nn.softmax(logits)
return logits, prob
以上的 CliqueNet 就是北京大学和上海交通大学在 CVPR 2018 对卷积网络架构的探索,也许还有更多更高效的结构,但这需要研究社区长期的努力。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4775.html
摘要:近日,谷歌大脑发布了一篇全面梳理的论文,该研究从损失函数对抗架构正则化归一化和度量方法等几大方向整理生成对抗网络的特性与变体。他们首先定义了全景图损失函数归一化和正则化方案,以及最常用架构的集合。 近日,谷歌大脑发布了一篇全面梳理 GAN 的论文,该研究从损失函数、对抗架构、正则化、归一化和度量方法等几大方向整理生成对抗网络的特性与变体。作者们复现了当前较佳的模型并公平地对比与探索 GAN ...
摘要:和是两个非常重要的网络,它们显示了深层卷积神经网络的能力,并且指出使用极小的卷积核可以提高神经网络的学习能力。也有工作考察与的关系,与其相似,本文考察了与的关系。与的网络架构配置以及复杂度见表。 DPN Dual Path NetworksYunpeng Chen, Jianan Li, Huaxin Xiao, Xiaojie Jin, Shuicheng Yan, Jiashi F...
摘要:一个简单的解释是,在论文和论文中,恒等映射的输出被添加到下一个模块,如果两个层的特征映射有着非常不同的分布,那么这可能会阻碍信息流。 在 AlexNet [1] 取得 LSVRC 2012 分类竞赛冠军之后,深度残差网络(Residual Network, 下文简写为 ResNet)[2] 可以说是过去几年中计算机视觉和深度学习领域最具开创性的工作。ResNet 使训练数百甚至数千层成为可能...

阅读 1915·2021-09-29 09:35
阅读 2776·2021-09-22 15:25
阅读 2025·2021-08-23 09:43
阅读 2097·2019-08-30 15:54
阅读 3393·2019-08-30 15:53
阅读 2442·2019-08-30 13:50
阅读 2453·2019-08-30 11:24
阅读 2317·2019-08-29 15:37




