
摘要:或许是有的这是一篇关于随机加权平均的新论文所获得的成果。随机加权平均,随机加权平均和快速几何集成非常近似,除了计算损失的部分。
在这篇文章中,我将讨论最近两篇有趣的论文。它们提供了一种简单的方式,通过使用一种巧妙的集成方法提升神经网络的性能。
Garipov 等人提出的 “Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs”
https://arxiv.org/abs/1802.10026
Izmailov 等人提出的 “Averaging Weights Leads to Wider Optima and Better Generalization”
https://arxiv.org/abs/1803.05407
若希望更容易理解这篇博客,可以先阅读这一篇论文:
Vitaly Bushaev 提出的 “Improving the way we work with learning rate”
https://techburst.io/improving-the-way-we-work-with-learning-rate-5e99554f163b
传统的神经网络集成方法
传统的集成方法通常是结合几种不同的模型,并使他们对相同的输入进行预测,然后使用某种平均方法得到集合的最终预测。 它可以是简单的投票法,平均法。或者甚至可以使用另一个模型,根据集成模型的输入学习并预测正确的值或标签。岭回归是一种特殊的集成方法,被许多在 Kaggle 竞赛获奖的机器学习从业人员所使用。

网络快照集成法是在每次学习率周期结束时保存模型,然后在预测过程中同时使用保存下来的模型。
当集成方法应用在深度学习中时,可以通过组合多个神经网络的预测,从而得到一个最终的预测结果。通常情况下,集成不同结构的神经网络是一个很好的方法,因为不同的模型可能在不同的训练样本上犯错,因此集成模型将会得到更大的好处。
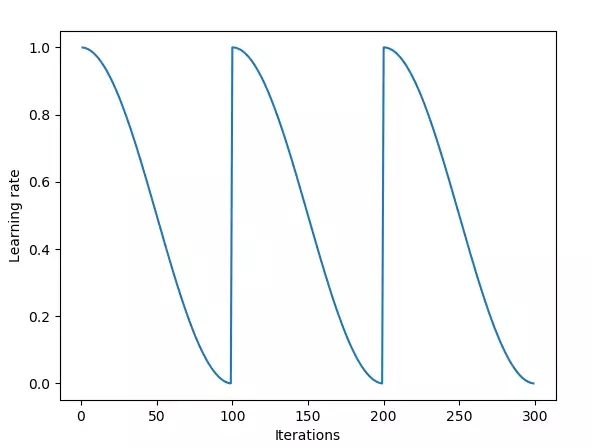
网络快照集成法使用基于退火策略的循环学习率策略。
但是,你也可以集成相同结构的神经网络模型,也会得到很棒的结果。在网络快照集成法论文中,作者基于这种方法使用了一个非常酷的技巧。作者在训练相同网络时使用权重快照,在训练结束后用这些结构相同但权重不同的模型创建一个集成模型。这种方法使测试集效果提升,而且这也是一种非常简单的方法,因为你只需要训练一次模型,将每一时刻的权重保存下来就可以了。
想要了解更多的细节,你可以参考这个博客。如果你还没有使用循环学习率策略,那么你一定要了解它。因为这是当前较先进而且最简单的训练技巧了,计算量不大,也几乎不需要额外成本就可以提供很大的收益。
上面的例子都是基于模型的集成方法,因为它们是通过结合多个模型的预测从而产生最终的预测结果。
但在这篇博客即将讨论的论文中,作者提出了一种新的基于权重的集成方法。这种方法通过结合相同网络结构不同训练阶段的权重获得集成模型,然后进行预测。这种方法有两个优点:
当结合权重时,我们最后仍然是得到一个模型,这提升了预测的速度
实验结果表明,这种方法打败了当前较先进的网络快照集成法
来看看它是怎么实现的吧。但首先我们需要了解一些关于损失平面和泛化问题的重要结论。
权重空间中的解决方案
第一个重要的观点是:一个训练好的网络是多维权重空间中的一个点。对于一个给定的网络结构,每一种不同的权重组合将得到不同的模型。因为所有模型结构都有无限多种权重组合,所以将有无限多种组合方法。训练神经网络的目标是找到一个特别的解决方案(权重空间中的点),从而使训练集和测试集上的损失函数的值达到很小。
训练过程中,通过改变权重,训练算法改变网络的结构,并在权重空间中不断搜索。随机梯度下降法在损失平面上传播,损失平面的高低由损失函数的值决定。
局部与全局最优解
可视化与理解多维权重空间的几何特点是非常困难的。同时,这也是非常重要的,因为在训练时,随机梯度下降法的本质是在多维空间的损失平面上传播,并努力找到一个好的解决方案--损失平面上的一个损失函数值很低的"点”。众所周知,这些平面有许多局部最优解,但并不是所有局部最优解都是优秀的解决方案。
Hinton: “为了处理14维空间中的超平面, 可视化3维空间并大声对自己说“14”。 每个人都这样做。“
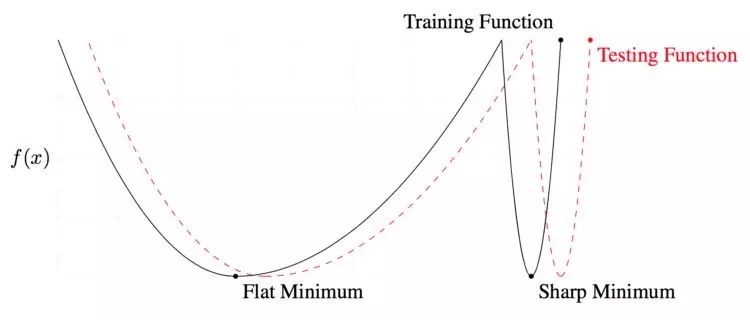
局部和全局最优解。在训练和测试过程中,平滑的较低值会产生相似的损失。然而,训练和测试过程中产生的局部损失,有非常大的差异。换句话说,全局最小值比局部最小值更通用。
判断解决方案好坏的一个标准就是该方案解的平滑性。 这一思想在于训练数据和测试数据会产生类似的但并不完全一样的损失面。你可以想象一下,一个测试表面相对于训练表面移动一点。对于一个局部解,在测试过程中,因为这一点移动,一个给出低损失值的点会给出一个高损失值。这意味着这个”局部“解决方案没有产生最优值——训练损失小,而测试损失大。另一方面,对于一个”全局“平滑解决方案,这一点移动会导致训练和测试损失的差值很小。
我之所以解释局部和全局解决方案的不同,是因为这篇博客聚焦的新方法提供非常好的全局解决方案。
快照集成
最初,随机梯度下降(SGD,Stochastic Gradient Descent) 会在权重空间产生大的跃变。随后,当学习率由于余弦退火算法越来越小时, SGD 会收敛到某个局部解,该算法会对模型拍个”快照“,即将这个局部解加入到集合中。接着,学习率再次被重置成高值,SGD在收敛到某个不同的局部解之前,再次产生一个大的跃变。
快照集成方法的循环长度是20到40个 epoch(使用训练集的全部数据对模型进行一次完整的训练,称为一个epoch)。长学习率循环的思想在于能够在权重空间找到足够多不同的模型。如果模型相似度太高,集合中各网络的预测就会太接近,而体现不出集成带来的好处。
快照集成确实效果很好,提高了模型的性能,但是快速几何集成更有效。
快速几何集成 (FGE)
快速几何集成与快照集成类似,但有一些与快照集成不同的特征。FGE使用线性分段循环学习率策略代替余弦。其次,FGE的循环长度更短——每个循环只有2到4个epoch。最初的直觉认为,短循环是错误的,因为每次循环结束时产生的模型都非常相似,差别不大,所以集成这些模型不能带来益处。然而,正如作者发现的,由于在足够多的不同模型间,存在低损失的连接通路,沿着那些通路,采用短循环是可行的,而且在这一过程中,会产生差异足够大的模型,集成这些模型会产生很好的结果。因此,与快照集成相比,FGE提高了模型的性能,每次循环经过更少的epoch就能找到差异足够大的模型(这使训练速度更快)。
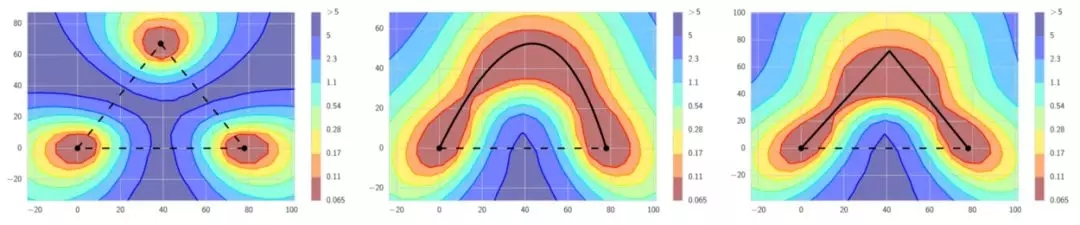
左边:传统观点认为好的局部最小值被高损失区域分隔开。如果我们观察连接局部最小值的直线,会发现这是正确的。中间和右边:然而,在局部最小值之间存在通路,这些通路上的损失值始终很低。FGE沿着这些通路拍快照,并利用这些快照构建一个集合。
为了从快照集成或者FGE中获益,需要存储多种模型并得出这些模型的预测,然后对这些预测求平均,作为最终的预测。因此,集合的附加性能需要消耗更多的计算。所以没有免费的午餐。或许是有的?这是一篇关于随机加权平均的新论文所获得的成果。
随机加权平均(SWA,Stochastic Weight Averaging)
随机加权平均和快速几何集成非常近似,除了计算损失的部分。 SWA 可以应用于任何架构和数据集,而且都能产生较好的结果。这篇论文给出了参考建议,SWA可以得到更大范围的最小值,上文已经讨论过这一点的好处。SWA不是经典意义上的集成。在训练结束的时候,会产生一个模型,这个模型的性能优于快照集成,接近FGE。
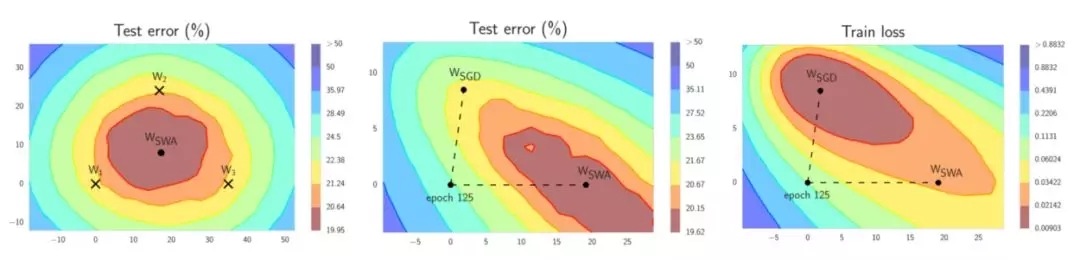
左边:W1,W2和W3 代表了3个独立的训练网络,Wswa是它们的平均。 中间:与SGD相比,Wswa 在测试集上产生了更优越的性能。右边:注意即使Wswa在训练集上的性能更差,它在测试集上的效果仍然更好。
SWA的灵感来自于实际观察,每次学习率循环结束时产生的局部最小值趋向于在损失面的边缘区域累积,这些边缘区域上的损失值较小(上面左图中,显示低损失的红色区域上的点W1,W2和W3)。通过对几个这样的点取平均,很有可能得到一个甚至更低损失的、全局化的通用解(上面左图上的Wswa)。
这儿展示了 SWA 是如何工作的。不需要集成很多模型,只需要两个模型。
第一个模型存储模型权重的平均值(公式中的 w_swa )。这就是训练结束后的最终模型,用于预测。
第二个模型(公式中的w)变换权重空间,利用循环学习率策略找到最优权重空间。

随机加权平均权重更新公式
每次学习率循环结束的时候,第二个模型的当前权重会被用于更新正在运行的平均模型的权重,即对已有的平均权重和第二个模型产生的新权重进行加权平均(左图中的公式)。采用这个方法,训练时,只需要训练一个模型,存储两个模型。而预测时,只需要一个当前的平均模型进行预测。用这个模型做预测,比前面提到的方法,速度快得多。之前的方法是用集合中的多个模型做预测,然后对多个预测结果求平均。
实现
该论文的作者提供了他们自己的实现,这个实现是用PyTorch完成的。
当然,著名的fast.ai库也实现了SWA。每个人应该都在使用这个库。如果你还没有看到这个课程,请点击此链接。
感谢您的阅读!
原文链接:
https://towardsdatascience.com/stochastic-weight-averaging-a-new-way-to-get-state-of-the-art-results-in-deep-learning-c639ccf36a
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4771.html
摘要:机器学习系统被用来识别图像中的物体将语音转为文本,根据用户兴趣自动匹配新闻消息或产品,挑选相关搜索结果。而深度学习的出现,让这些问题的解决迈出了至关重要的步伐。这就是深度学习的重要优势。 借助深度学习,多处理层组成的计算模型可通过多层抽象来学习数据表征( representations)。这些方法显著推动了语音识别、视觉识别、目标检测以及许多其他领域(比如,药物发现以及基因组学)的技术发展。...
摘要:三大牛和在深度学习领域的地位无人不知。逐渐地,这些应用使用一种叫深度学习的技术。监督学习机器学习中,不论是否是深层,最常见的形式是监督学习。 三大牛Yann LeCun、Yoshua Bengio和Geoffrey Hinton在深度学习领域的地位无人不知。为纪念人工智能提出60周年,的《Nature》杂志专门开辟了一个人工智能 + 机器人专题 ,发表多篇相关论文,其中包括了Yann LeC...
摘要:和的得分均未超过右遗传算法在也表现得很好。深度遗传算法成功演化了有着万自由参数的网络,这是通过一个传统的进化算法演化的较大的神经网络。 Uber 涉及领域广泛,其中许多领域都可以利用机器学习改进其运作。开发包括神经进化在内的各种有力的学习方法将帮助 Uber 发展更安全、更可靠的运输方案。遗传算法——训练深度学习网络的有力竞争者我们惊讶地发现,通过使用我们发明的一种新技术来高效演化 DNN,...

阅读 892·2021-10-13 09:39
阅读 3772·2021-10-12 10:12
阅读 1835·2021-08-13 15:07
阅读 1060·2019-08-29 15:31
阅读 2933·2019-08-26 13:25
阅读 1829·2019-08-23 18:38
阅读 1944·2019-08-23 18:25
阅读 1896·2019-08-23 17:20




