
摘要:本论文研究只有遗忘门的话会怎样,并提出了,实验表明该模型的性能优于标准。这里我们发现,一个只有遗忘门且带有偏置项的版本不仅能节省计算成本,而且在多个基准数据集上的性能优于标准,能与一些当下较好的模型竞争。
本论文研究 LSTM 只有遗忘门的话会怎样,并提出了 JANET,实验表明该模型的性能优于标准 LSTM。
1.介绍
优秀的工程师确保其设计是实用的。目前我们已经知道解决序列分析问题较好的方式是长短期记忆(LSTM)循环神经网络,接下来我们需要设计一个满足资源受限的现实世界应用的实现。鉴于使用两个门的门控循环单元(Cho 等,2014)的成功,第一种设计更硬件高效的 LSTM 的方法可能是消除冗余门(redundant gate)。因为我们要寻求比 GRU 更高效的模型,所以只有单门 LSTM 模型值得我们研究。为了说明为什么这个单门应该是遗忘门,让我们从 LSTM 的起源讲起。
在那个训练循环神经网络(RNN)十分困难的年代,Hochreiter 和 Schmidhuber(1997)认为在 RNN 中使用单一权重(边)来控制是否接受记忆单元的输入或输出带来了冲突性更新(梯度)。本质上来讲,每一步中长短期误差(long and short-range error)作用于相同的权重,且如果使用 sigmoid 激活函数的话,梯度消失的速度要比权重增加速度快。之后他们提出长短期记忆(LSTM)单元循环神经网络,具备乘法输入门和输出门。这些门可以通过「保护」单元免受不相关信息(其他单元的输入或输出)影响,从而缓解冲突性更新问题。
LSTM 的第一个版本只有两个门:Gers 等人(2000)首先发现如果没有使记忆单元遗忘信息的机制,那么它们可能会无限增长,最终导致网络崩溃。为解决这个问题,他们为这个 LSTM 架构加上了另一个乘法门,即遗忘门,完成了我们今天看到的 LSTM 版本。
鉴于遗忘门发现的重要性,那么设想 LSTM 仅使用一个遗忘门,输入和输出门是否必要呢?本研究将探索多带带使用遗忘门的优势。在五个任务中,仅使用遗忘门的模型提供了比使用全部三个 LSTM 门的模型更好的解决方案。
3 JUST ANOTHER NETWORK
我们提出了一个简单的 LSTM 变体,其只有一个遗忘门。它是 Just Another NETwork,因此我们将其命名为 JANET。我们从标准 LSTM(Lipton 等,2015)开始,其中符号具备标准含义,定义如下
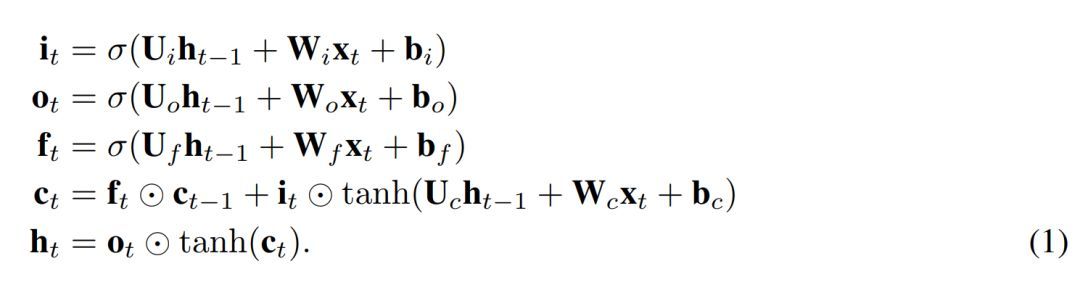
为了将上述内容转换成 JANET 架构,我们删除了输入和输出门。将信息的累积和删除关联起来似乎是明智的,因此我们将输入和遗忘调制结合起来,就像 Greff et al. (2015) 论文中所做的那样,而这与 leaky unit 实现 (Jaeger, 2002, §8.1) 类似。此外,h_t 的 tanh 激活函数使梯度在反向传播期间出现收缩,这可能加剧梯度消失问题。权重 U∗ 可容纳 [-1,1] 区间外的值,因此我们可移除这个不必要且可能带来问题的 tanh 非线性函数。得出的 JANET 结果如下:
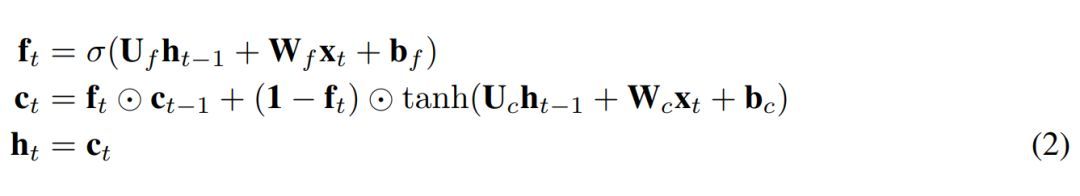
4 实验与结果
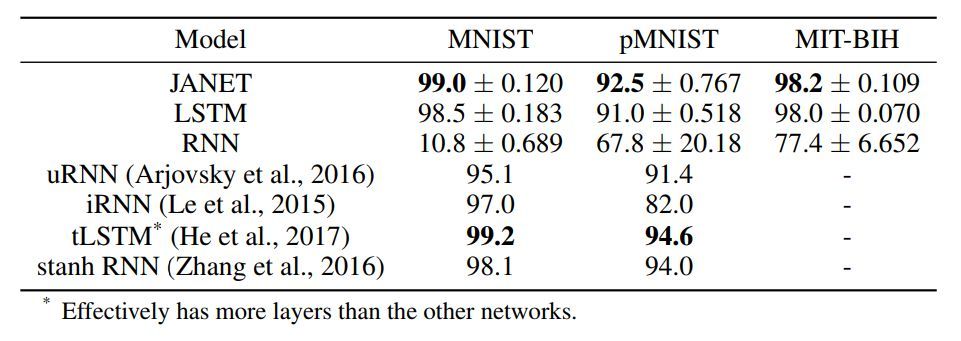
表 1:不同循环神经网络架构的准确率 [%]。图中展示了 10 次独立运行得到的平均值和标准差。我们实验中的较佳准确率结果以及引用论文中的较佳结果以粗体显示。
令人惊讶的是,结果表明 JANET 比标准 LSTM 的准确率更高。此外,JANET 是在所有分析数据集上表现较佳的模型之一。因此,通过简化 LSTM,我们不仅节省了计算成本,还提高了测试集上的准确率!
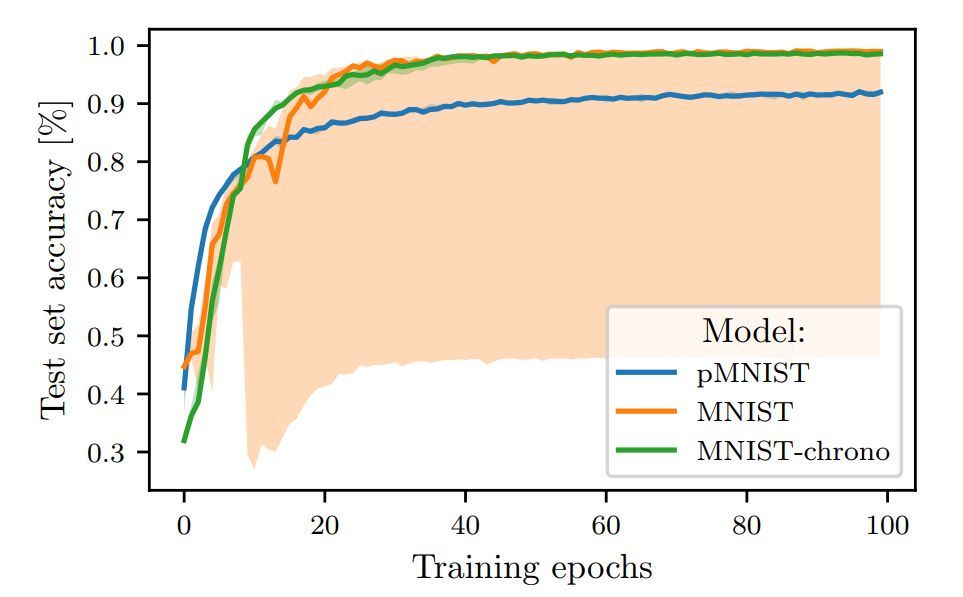
图 1:在 MNIST 和 pMNIST 上训练的 LSTM 的测试准确率。
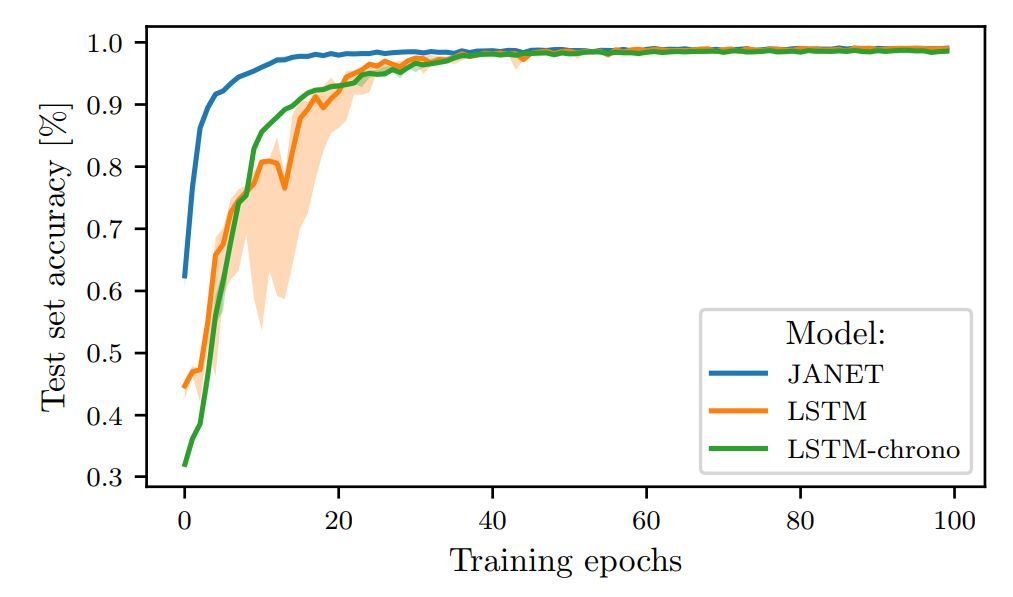
图 2:JANET 和 LSTM 在 MNIST 上训练时的测试集准确率对比。
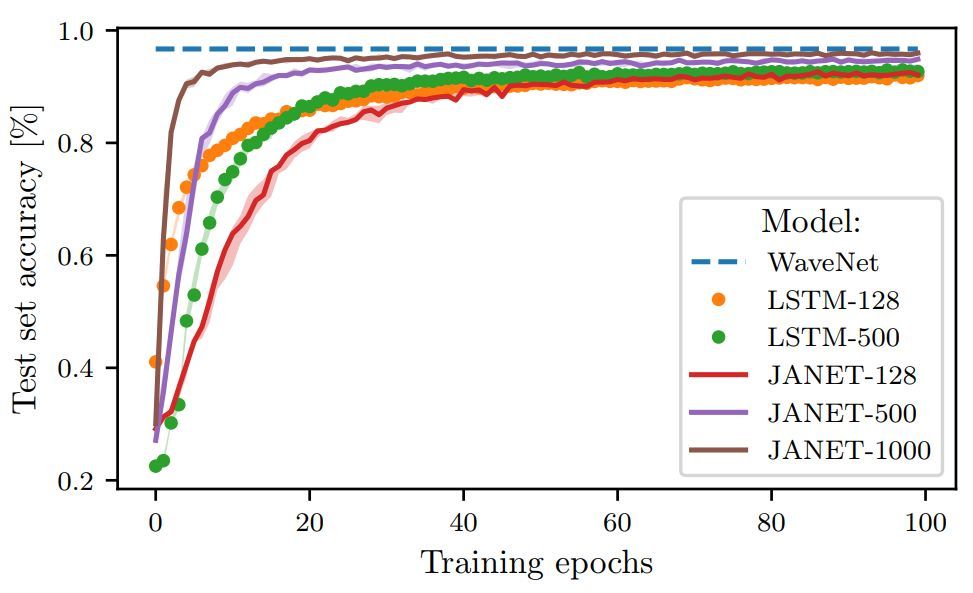
图 3:不同层大小的 JANET 和 LSTM 在 pMNIST 数据集上的准确率(%)。
论文:THE UNREASONABLE EFFECTIVENESS OF THE FORGET GATE
论文链接:https://arxiv.org/abs/1804.04849
摘要:鉴于门控循环单元(GRU)的成功,一个很自然的问题是长短期记忆(LSTM)网络中的所有门是否是必要的。之前的研究表明,遗忘门是 LSTM 中最重要的门之一。这里我们发现,一个只有遗忘门且带有 chrono-initialized 偏置项的 LSTM 版本不仅能节省计算成本,而且在多个基准数据集上的性能优于标准 LSTM,能与一些当下较好的模型竞争。我们提出的网络 JANET,在 MNIST 和 pMNIST 数据集上分别达到了 99% 和 92.5% 的准确率,优于标准 LSTM 98.5% 和 91% 的准确率。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4765.html
摘要:作为解决方案的和和是解决短时记忆问题的解决方案,它们具有称为门的内部机制,可以调节信息流。随后,它可以沿着长链序列传递相关信息以进行预测,几乎所有基于递归神经网络的技术成果都是通过这两个网络实现的。和采用门结构来克服短时记忆的影响。 短时记忆RNN 会受到短时记忆的影响。如果一条序列足够长,那它们将很难将信息从较早的时间步传送到后面的时间步。 因此,如果你正在尝试处理一段文本进行预测,RNN...
摘要:前馈网络的反向传播从最后的误差开始,经每个隐藏层的输出权重和输入反向移动,将一定比例的误差分配给每个权重,方法是计算权重与误差的偏导数,即两者变化速度的比例。随后,梯度下降的学习算法会用这些偏导数对权重进行上下调整以减少误差。 目录前馈网络递归网络沿时间反向传播梯度消失与梯度膨胀长短期记忆单元(LSTM)涵盖多种时间尺度本文旨在帮助神经网络学习者了解递归网络的运作方式,以及一种主要的递归网络...
摘要:得到的结果如下上图是门卷积神经网络模型与和模型在数据集基准上进行测试的结果。虽然在这一研究中卷积神经网络在性能上表现出了对递归神经网络,尤其是的全面超越,但是,现在谈取代还为时尚早。 语言模型对于语音识别系统来说,是一个关键的组成部分,在机器翻译中也是如此。近年来,神经网络模型被认为在性能上要优于经典的 n-gram 语言模型。经典的语言模型会面临数据稀疏的难题,使得模型很难表征大型的文本,...

阅读 2530·2021-11-22 15:35
阅读 3815·2021-11-04 16:14
阅读 2759·2021-10-20 13:47
阅读 2557·2021-10-13 09:49
阅读 2124·2019-08-30 14:09
阅读 2473·2019-08-26 13:49
阅读 937·2019-08-26 10:45
阅读 2829·2019-08-23 17:54




