
摘要:如果不一致,那么就出现了新的机器学习问题,如等。要解决独立同分布的问题,理论正确的方法就是对每一层的数据都进行白化操作。变换为均值为方差为的分布,也并不是严格的同分布,只是映射到了一个确定的区间范围而已。
“ 深度神经网络模型训练之难众所周知,其中一个重要的现象就是 Internal Covariate Shift. Batch Normalization 大法自 2015 年由Google 提出之后,就成为深度学习必备之神器。自 BN 之后, Layer Norm / Weight Norm / Cosine Norm 等也横空出世。本文从 Normalization 的背景讲起,用一个公式概括 Normalization 的基本思想与通用框架,将各大主流方法一一对号入座进行深入的对比分析,并从参数和数据的伸缩不变性的角度探讨 Normalization 有效的深层原因。本文是该系列的第一篇。”
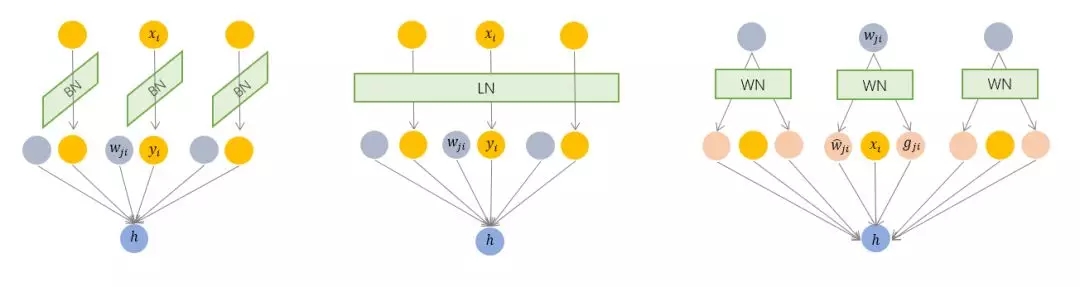
01、为什么需要 Normalization
1.1 独立同分布与白化
机器学习界的炼丹师们最喜欢的数据有什么特点?窃以为,莫过于“独立同分布”了,即 independent and identically distributed,简称为 i.i.d. 独立同分布并非所有机器学习模型的必然要求(比如 Naive Bayes 模型就建立在特征彼此独立的基础之上,而Logistic Regression 和 神经网络 则在非独立的特征数据上依然可以训练出很好的模型),但独立同分布的数据可以简化常规机器学习模型的训练、提升机器学习模型的预测能力,已经是一个共识。
因此,在把数据喂给机器学习模型之前,“白化(whitening)”是一个重要的数据预处理步骤。白化一般包含两个目的:
(1)去除特征之间的相关性 —> 独立;
(2)使得所有特征具有相同的均值和方差 —> 同分布。
白化最典型的方法就是PCA,本文不再展开。
1.2 深度学习中的 Internal Covariate Shift
深度神经网络模型的训练为什么会很困难?其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。为了训好模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。
Google 将这一现象总结为 Internal Covariate Shift,简称 ICS. 什么是 ICS 呢?@魏秀参 在一个回答中做出了一个很好的解释:
大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如 transfer learning / domain adaptation 等。而 covariate shift 就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同,即:对所有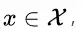 有:
有:
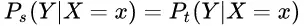
但是

大家细想便会发现,的确,对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了 covariate shift 的定义。由于是对层间信号的分析,也即是 “internal”的来由。
1.3 ICS 会导致什么问题?
简而言之,每个神经元的输入数据不再是“独立同分布”。
其一,上层参数需要不断适应新的输入数据分布,降低学习速度。
其二,下层输入的变化可能趋向于变大或者变小,导致上层落入饱和区,使得学习过早停止。
其三,每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能的谨慎。
02、Normalization 的基本思想与框架
我们以神经网络中的一个普通神经元为例。神经元接收一组输入向量
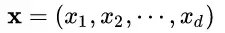
通过某种运算后,输出一个标量值:

由于 ICS 问题的存在, x 的分布可能相差很大。要解决独立同分布的问题,“理论正确”的方法就是对每一层的数据都进行白化操作。然而标准的白化操作代价高昂,特别是我们还希望白化操作是可微的,保证白化操作可以通过反向传播来更新梯度。
因此,以 BN 为代表的 Normalization 方法退而求其次,进行了简化的白化操作。基本思想是:在将 x 送给神经元之前,先对其做平移和伸缩变换, 将 x 的分布规范化成在固定区间范围的标准分布。
通用变换框架就如下所示:
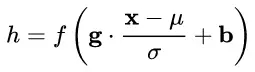
我们来看看这个公式中的各个参数。
(1) μ 是平移参数(shift parameter), σ 是缩放参数(scale parameter)。通过这两个参数进行 shift 和 scale 变换:
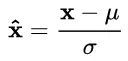
得到的数据符合均值为 0、方差为 1 的标准分布。
(2)b 是再平移参数(re-shift parameter),b 是再缩放参数(re-scale parameter)。将 上一步得到的 hat{x} 进一步变换为:

最终得到的数据符合均值为 b 、方差为 g^2 的分布。
奇不奇怪?奇不奇怪?
说好的处理 ICS,第一步都已经得到了标准分布,第二步怎么又给变走了?
答案是——为了保证模型的表达能力不因为规范化而下降。
我们可以看到,第一步的变换将输入数据限制到了一个全局统一的确定范围(均值为 0、方差为 1)。下层神经元可能很努力地在学习,但不论其如何变化,其输出的结果在交给上层神经元进行处理之前,将被粗暴地重新调整到这一固定范围。
沮不沮丧?沮不沮丧?
难道我们底层神经元人民就在做无用功吗?
所以,为了尊重底层神经网络的学习结果,我们将规范化后的数据进行再平移和再缩放,使得每个神经元对应的输入范围是针对该神经元量身定制的一个确定范围(均值为 b 、方差为 g^2 )。rescale 和 reshift 的参数都是可学习的,这就使得 Normalization 层可以学习如何去尊重底层的学习结果。
除了充分利用底层学习的能力,另一方面的重要意义在于保证获得非线性的表达能力。Sigmoid 等激活函数在神经网络中有着重要作用,通过区分饱和区和非饱和区,使得神经网络的数据变换具有了非线性计算能力。而第一步的规范化会将几乎所有数据映射到激活函数的非饱和区(线性区),仅利用到了线性变化能力,从而降低了神经网络的表达能力。而进行再变换,则可以将数据从线性区变换到非线性区,恢复模型的表达能力。
那么问题又来了——
经过这么的变回来再变过去,会不会跟没变一样?
不会。因为,再变换引入的两个新参数 g 和 b,可以表示旧参数作为输入的同一族函数,但是新参数有不同的学习动态。在旧参数中, x 的均值取决于下层神经网络的复杂关联;但在新参数中,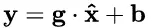 仅由 b 来确定,去除了与下层计算的密切耦合。新参数很容易通过梯度下降来学习,简化了神经网络的训练。
仅由 b 来确定,去除了与下层计算的密切耦合。新参数很容易通过梯度下降来学习,简化了神经网络的训练。
那么还有一个问题(问题怎么这么多!)——
这样的 Normalization 离标准的白化还有多远?
标准白化操作的目的是“独立同分布”。独立就不说了,暂不考虑。变换为均值为 b 、方差为 g^2 的分布,也并不是严格的同分布,只是映射到了一个确定的区间范围而已。(所以,这个坑还有得研究呢!)
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4738.html
摘要:最普遍的变换是线性变换,即和均将规范化应用于输入的特征数据,而则另辟蹊径,将规范化应用于线性变换函数的权重,这就是名称的来源。他们不处理权重向量,也不处理特征数据向量,就改了一下线性变换的函数其中是和的夹角。 深度神经网络模型训练之难众所周知,其中一个重要的现象就是 Internal Covariate Shift. Batch Normalization 大法自 2015 年由Googl...
摘要:但是其仍然存在一些问题,而新提出的解决了式归一化对依赖的影响。上面三节分别介绍了的问题,以及的工作方式,本节将介绍的原因。作者基于此,提出了组归一化的方式,且效果表明,显著优于等。 前言Face book AI research(FAIR)吴育昕-何恺明联合推出重磅新作Group Normalization(GN),提出使用Group Normalization 替代深度学习里程碑式的工作B...
摘要:为了解决这个问题出现了批量归一化的算法,他对每一层的输入进行归一化,保证每层的输入数据分布是稳定的,从而加速训练批量归一化归一化批,一批样本输入,,个样本与激活函数层卷积层全连接层池化层一样,批量归一化也属于网络的一层,简称。 【DL-CV】数据预处理&权重初始化【DL-CV】正则化,Dropout 先来交代一下背景:在网络训练的过程中,参数的更新会导致网络的各层输入数据的分布不断变化...

阅读 3174·2021-09-22 14:59
阅读 1989·2021-09-22 10:02
阅读 2164·2021-09-04 16:48
阅读 2313·2019-08-30 15:53
阅读 3025·2019-08-30 11:27
阅读 3491·2019-08-29 18:35
阅读 1008·2019-08-29 17:07
阅读 2721·2019-08-29 13:27




