
摘要:在低端领域,在上训练模型的价格比便宜两倍。硬件定价价格变化频繁,但目前提供的实例起价为美元小时,以秒为增量计费,而更强大且性能更高的实例起价为美元小时。
随着越来越多的现代机器学习任务都需要使用GPU,了解不同GPU供应商的成本和性能trade-off变得至关重要。
初创公司Rare Technologies最近发布了一个超大规模机器学习基准,聚焦GPU,比较了几家受欢迎的硬件提供商,在机器学习成本、易用性、稳定性、可扩展性和性能等方面的性能。
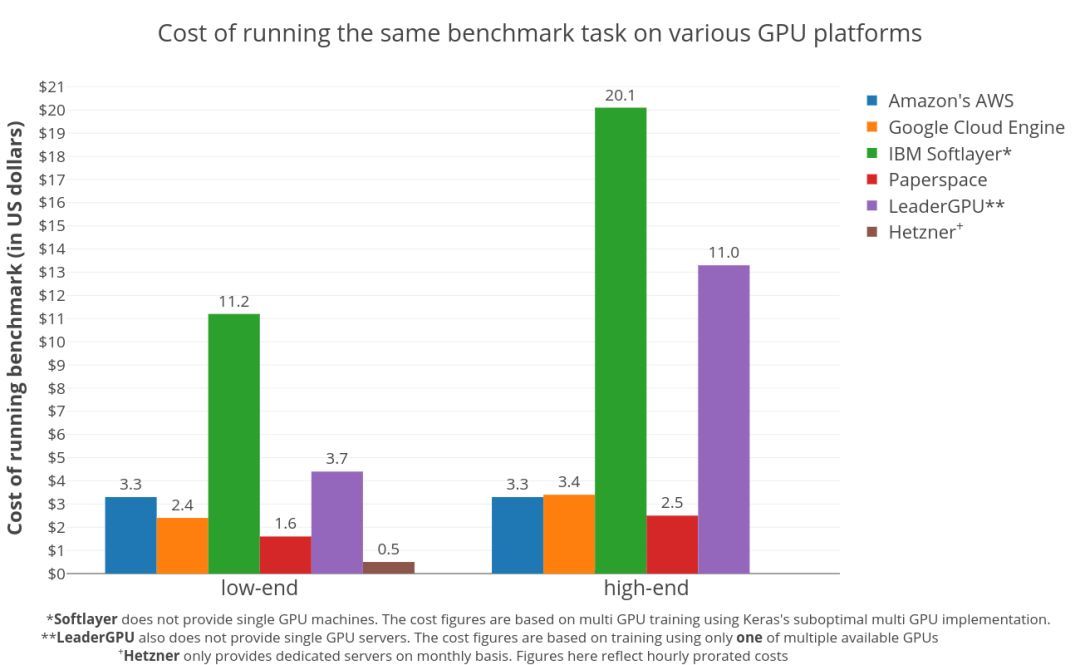
在6大GPU硬件平台上,执行Twitter情绪分类任务(大约150万条推文,4个时期),训练双向LSTM的成本。由上图可知,专用服务器是控制成本的较佳选择。
这项基准测试横向比较了以下硬件平台:亚马逊AWS EC2,谷歌Google Cloud Engine GCE,IBM Softlayer,Hetzner,Paperspace,以及LeaderGPU,这些硬件提供商都在这项测试期间提供了credits和支持。基准发布时,微软Azure官方还没有回应,因此很遗憾没有纳入比较。
不过,这项测试还是涵盖各种不同类型的GPU平台:提供虚拟机的(AWS,GCE),裸机基础设施(Softlayer),专用服务器(Hetzner)和专门提供GPUaaS的(LeaderGPU,Paperspace),也算很全面。研究人员也表示,他们希望通过测试,看看高端GPU是否更真的值价。
先说结果,经过这个测试后他们发现:


*这些是多GPU实例的结果,使用multi_gpu_model的multi_gpu_model函数在所有GPU上训练模型,后来发现对多GPU利用率不足。
**由于上述原因,这些GPU模型仅使用多GPU种的其中一个进行训练。
+ Hzzner是按月收费,提供专用服务器。
基准设置:Twitter文本情绪分类任务
接下来,我们将详细讨论和比较所有的平台,以及这项测试的情况。
任务 这项基准使用的是情绪分类任务(sentiment classification task [1])。具体说,训练双向LSTM来对Twitter的推文做二元分类。算法的选择并不是很重要,作者Shiva Manne表示,他对这个基准测试的真正要求,是这项任务是否应该是GPU密集型的。为了确保GPU的较大利用率,他使用了由CuDNN( CuDNNLSM层)支持的Keras快速LSTM实现。
数据集 Twitter情绪分析数据集(Twitter Sentiment Analysis Dataset [2]),包含1,578,627条分过类的推文,每行用“1”标记为积极情绪,“0”表示消极情绪。模型对90%(shuffled)数据进行了4个epoch的训练,剩下的10%用于模型评估。
Docker 为了可重复性,他们创建了一个Nvidia Docker镜像 ,其中包含重新运行此基准测试所需的所有依赖项和数据。Dockerfile和所有必需的代码可以在这个Github[3]库中找到。
订购和使用:LeaderGPU、AWS、Paperspace尤其适合初学者
在LeaderGPU和Paperspace上的订购过程非常顺畅,没有任何复杂的设置(settings)。与AWS或GCE相比,Paperspace和LeaderGPU的供应时间要稍长一些(几分钟)。
LeaderGPU,Amazon和Paperspace提供免费的深度学习机器图像(Deep Learning Machine Images),这些图像预安装了Nvidia驱动程序,Python开发环境和Nvidia-Docker,基本上立即就能启动实验。这让事情变得容易很多,尤其是对于那些只希望尝试机器学习模型的初学者。但是,为了评估定制实例满足个性化需求的难易程度,Manne从零开始(除了LeaderGPU),设置了所有的东西。在这个过程中,他发现了各家平台常见的一些问题,例如NVIDIA驱动与安装的gcc版本不兼容,或者在安装驱动之后,没有证据表明正在运行程序,但GPU的使用率却达到100%。
意外的是,在Paperspace低端实例(P6000)上运行Docker导致错误,这是由由Docker上的Tensorflow是由源优化(MSSE,MAVX,MFMA)构建的,而Paperspace实例不支持。在没有这些优化的情况下运行Docker可以解决这个问题。
至于稳定性,各家表现都很好,没有遇到任何问题。
成本:专用服务器是控制成本的较佳选择;更便宜的GPU性价比更高
不出所料,专用服务器是控制成本的较佳选择。这是因为Hetzner按月收费,这意味着每小时的价格非常低,而且这个数字是按比例分摊的。所以,只要你的任务足够多,让服务器不会闲着,选择专用服务器就是正确的。
在虚拟机供应商中,Paperspace是明显的赢家。在低端GPU领域,在Paperspace上训练模型的价格比AWS便宜两倍($1.6 vs $3.3)。Paperspace进一步显示了,在高端GPU部分也有类似的成本效益模式。
刚才你可能已经看过这张图了,不过配合这里讨论的话题,再看一次:
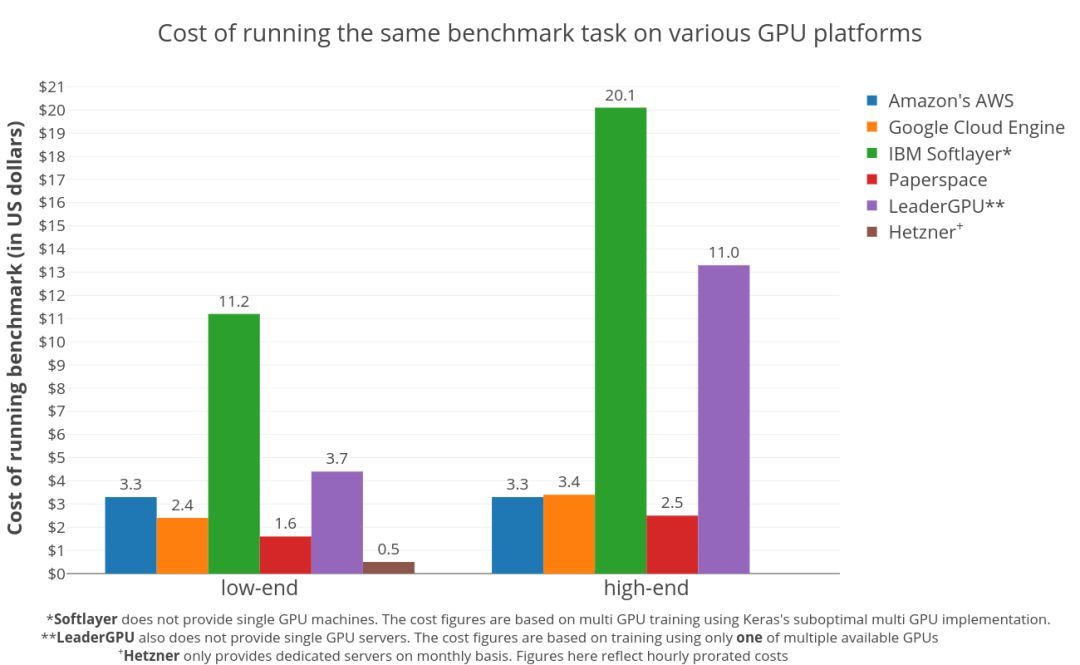
基准测试结果:在各种GPU硬件平台上对Twitter情绪分类任务(大约150万条推文,4个时期)进行双向LSTM训练的成本。
在AWS和GCE之间,低端GPU是AWS稍贵($3.3 vs $2.4),但在高端GPU领域则反了过来($3.3 vs $3.4)。这意味着,选高端GPU,AWS可能更好,多付出的那部分价钱或许能收到回报。
需要指出,IBM Softlayer和LeaderGPU看起来很贵,主要是由于其多GPU实例的利用率不足。这项基准测试使用Keras框架进行,因此多GPU实现的效率惊人地低,有时甚至比同一台机器上运行的单个GPU更差。而这些平台都不提供单个的GPU实例。在Softlayer上运行的基准测试使用了所有可用的GPU,使用multi_gpu_model的multi_gpu_model函数,而multi_gpu_model上的测试只使用了一个可用的GPU。这导致资源利用不足,产生了很多的额外成本。
另外,LeaderGPU提供了更强大的GPU GTX 1080 Ti和Tesla V100,价格却与GTX 1080和Tesla P100相同(每分钟)。在这些服务器上运行,肯定会降低整体成本。综上,LeaderGPU在图表中,低端GPU成本部分,实际上是相当合理的。如果你打算使用非Keras框架,更好地利用多个GPU时,记住这些很重要。
另外还有一个大趋势,更便宜的GPU比更贵的GPU性价比更高,这表明训练时间的减少,并不能抵消总成本的增加。
使用Keras做多GPU训练模型:加速难以预测
既然也说到了使用Keras训练多GPU模型,就多说几句。
很多学术界和产业界人士非常喜欢使用像Keras这样的高级API来实现深度学习模型。Keras本身也很流行,接受度高,迭代更新也快,用户会以为使用Keras就不需要任何额外处理,能加快转换到多GPU模型。
但实际情况并非如此,从下图可以看出。
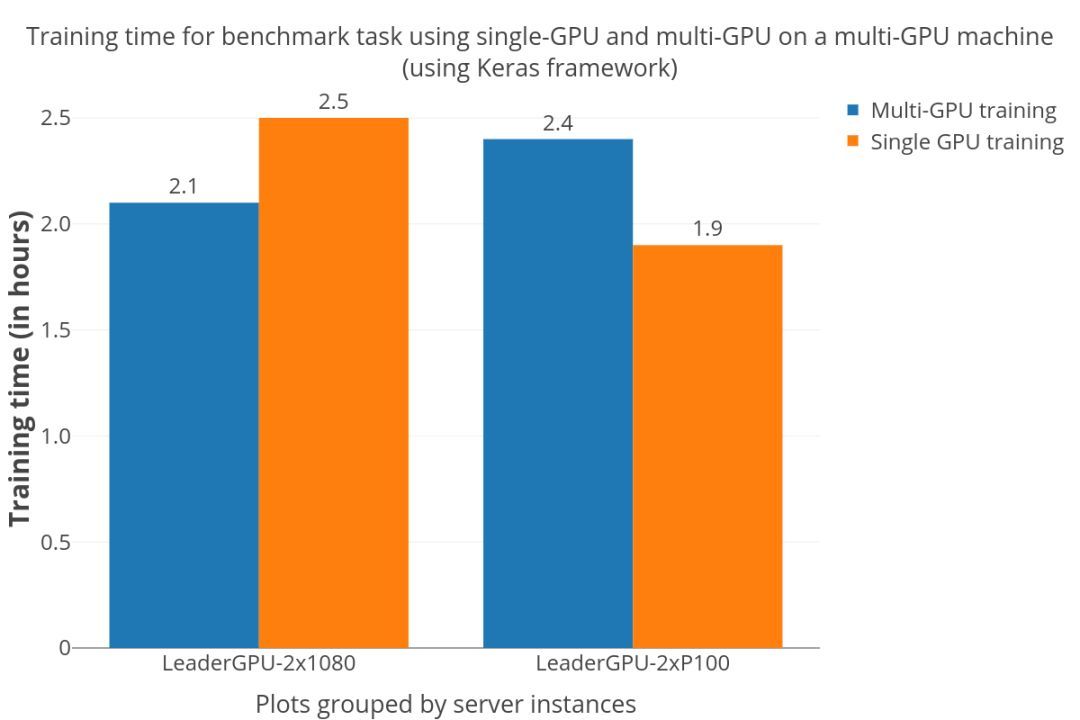
加速相当难以预测,与“双P100”服务器上的单GPU训练相比,“双GTX 1080”服务器显然有了加速,但多GPU训练却花费了更长的时间。这种情况在一些博客和Github issue中都有提出,也是Manne在调查成本过程中遇到的值得注意的问题。
模型精准度、硬件定价、现货测评及体验感受
模型精准度
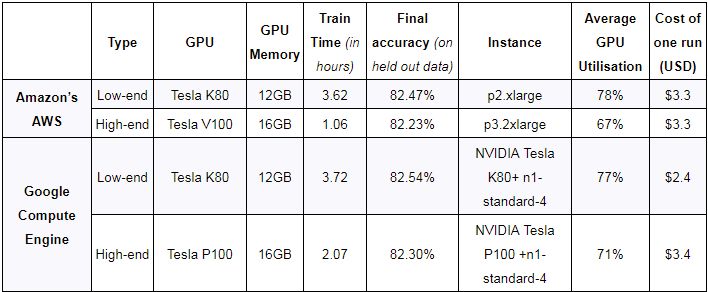
我们在训练结束时对模型最终的精度做了完整性测试,从表1可以看出,底层硬件/平台对训练质量没有影响,基准设置正确。
硬件定价
GPU价格变化频繁,但目前AWS提供的K80 GPU(p2实例)起价为0.9美元/小时,以1秒为增量计费,而更强大且性能更高的Tesla V100 GPU(p3实例)起价为3.06美元/小时。数据传输、弹性IP地址和EBS优化实例等附加服务需要支付额外费用。 GCE是一种经济的替代方案,它可以按照0.45美元/小时和1.46美元/小时的价格分别提供K80和P100。这些收费以一秒为增量,并通过基于折扣的使用有可观的奖励。尽管与AWS不同,它们需要附加到CPU实例(n1-standard-1,价格为0.0475美元/小时)。
Paperspace在低成本的联盟中与GCE竞争,专用GPU有Quadro M4000,0.4美元/小时,也有2.3美元/小时的Tesla V100。除了惯常的小时费外,他们还要收取月租费(每月5美元),服务包括储存和维修。以毫秒为基础的论文空间账单,附加服务可以以补充成本获得。 Hetzner每月仅提供一台配备GTX 1080的专用服务器,并额外支付一次设置费用。
IBM Softlayer是市场上为数不多的每月和每小时提供带有GPU的裸机服务器的平台之一。它提供3个GPU服务器(包含特斯拉M60s和K80s),起价为2.8美元/小时。这些服务器具有静态配置,这意味着与其他云提供商相比,其定制可能性有限。以小时为单位的软计算结果也是非常糟糕的,而且对于短时间运行的任务而言可能更昂贵。
LeaderGPU是一个相对较新的玩家,它提供了多种GPU(P100s,V100s,GTX1080s,GTX1080Ti)的专用服务器。用户可以利用按秒计费的每小时或每分钟定价。服务器至少有2个GPU,最多8个GPU,价格从0.02欧元/分钟到0.08欧元/分钟。
现货/抢先实例
某些平台在其备用计算容量(AWS spot实例和GCE的抢先实例)上提供了显着的折扣(50%-90%),尽管它们随时可能意外终止。这会导致高度不可预测的训练时间,因为不能保证实例何时再次启动。对于可以处理这种终端但是有许多任务的应用程序来说,这很好,而时间限制的项目在这种情况下不会很好(特别是如果考虑浪费的劳动时间)。
在抢先实例上运行任务需要额外的代码来优雅地处理实例的终止和重新启动(检查点/将数据存储到永久磁盘等)。此外,价格波动可能导致成本在很大程度上取决于基准运行时的产能供求。这将需要多次运行来平均成本。鉴于在完成基准测试时所花的时间有限,我没有以现场/先发实例为基准。
体验评论
Paperspace似乎在性能和成本方面领先一步,尤其适合希望深度学习技术的实验在另一个基准测试中得出类似的结论。
专用服务器(如LeaderGPU提供的服务器)和裸机服务器(如Hetzner)适合考虑长期使用这些资源(doh)的用户。但请注意,由于在定制服务器方面灵活性较差,因此请确保您的任务具有高度的CPU / GPU密集度以真正感受物超所值。
像Paperspace和LeaderGPU这样的新玩家不应该被解雇,因为他们可以帮助削减大部分的成本。由于相关的惯性和转换成本,企业可能不愿意切换提供商,但这些小型平台值得考虑。
AWS和GCE对于寻求与其他服务集成的用户来说是非常棒的选择(AI集成 - 亚马逊的Rekognition,Google的Cloud AI)。
除非你计划需要几天完成任务,否则坚持一个低端的单个GPU实例是较好的选择。
更高端的GPU运行更快,但实际上投资回报率更差。只有在较短的训练时间(较少的研发周期)比硬件成本更重要时,才应该选择这些方案。
原文链接:
https://rare-technologies.com/machine-learning-benchmarks-hardware-providers-gpu-part-2/
参考资料:
[1] http://thinknook.com/twitter-sentiment-analysis-training-corpus-dataset-2012-09-22/
[2] http://deeplearning.net/tutorial/lstm.html
[3] https://github.com/RaRe-Technologies/benchmark_GPU_platforms
商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4734.html
摘要:用于机器学习人工智能数据分析的基于云计算的工具日前增多。亚马逊公司创建了,以简化使用其机器学习工具的工作。用于机器学习、人工智能、数据分析的基于云计算的工具日前增多。其中的一些应用是在基于云计算的文档编辑和电子邮件,技术人员可以通过各种设备登录中央存储库,并在远程位置,甚至在路上或海滩上进行工作。云计算可以处理文件备份和同步,简化工作流程。数据分析是很多组织在云计算平台进行的一项主要计算工作...
摘要:关于请点击这里随着谷歌新机器学习平台的首次展示,等于在这片沙地上首次插入了这面旗帜,后续会有比如,的等等有着高级机器学习和云基础设施的公司比如纷至沓来。 在NEXT2016会议上,Google的Eric Schmidt提到Google所占最大的优势之一就是站在云计算下一个十年的前沿。它不是基础设施或者软件,也不像纯数据一样简单。 Crowdsourced 智能,是个进化,可以创建更加智...
摘要:关于请点击这里随着谷歌新机器学习平台的首次展示,等于在这片沙地上首次插入了这面旗帜,后续会有比如,的等等有着高级机器学习和云基础设施的公司比如纷至沓来。 在NEXT2016会议上,Google的Eric Schmidt提到Google所占最大的优势之一就是站在云计算下一个十年的前沿。它不是基础设施或者软件,也不像纯数据一样简单。 Crowdsourced 智能,是个进化,可以创建更加智...
摘要:亚马逊也宣布推出,这是一款完全自主的规模赛车,旨在帮助开发人员学习机器学习。此次问世,更是亚马逊要进一步占领市场的节奏。那么,面对已经发布芯片的谷歌云阿里云或者华为云,亚马逊真的要祭出大杀招,不战不休了。本周,亚马逊AWS re:Invent 2018大会在拉斯维加斯举办,AWS首席执行官Andy Jassy在会上发布了一款名为Inferentia的首款云端AI芯片。他表示,Inferent...
摘要:谷歌公司公布了其年的云计算市场收入。公司对其云计算市场收入进行了详细记录并且认为自治功能和数据即服务是与其他公有云服务商最大的差异。用户的采用率公司对行业厂商的名受访者进行的调查表明和微软是业界公认的两大顶级公有云服务商。近来,公司规模已经不再是企业选择云服务商的重要因素,市场对云服务商优劣的判断有了多种标准。企业对全球一些大型云计算服务商(例如亚马逊AWS,谷歌云平台,IBM Cloud和...

阅读 1440·2021-09-22 10:02
阅读 2116·2021-09-08 09:35
阅读 4133·2021-08-12 13:29
阅读 2664·2019-08-30 15:55
阅读 2311·2019-08-30 15:53
阅读 2368·2019-08-29 17:13
阅读 2812·2019-08-29 16:31
阅读 3003·2019-08-29 12:24






