
摘要:通过在中结合进化算法执行架构搜索,谷歌开发出了当前较佳的图像分类模型。本文是谷歌对该神经网络架构搜索算法的技术解读,其中涉及两篇论文,分别是和。此外,谷歌还使用其新型芯片来扩大计算规模。
通过在 AutoML 中结合进化算法执行架构搜索,谷歌开发出了当前较佳的图像分类模型 AmoebaNet。本文是谷歌对该神经网络架构搜索算法的技术解读,其中涉及两篇论文,分别是《Large-Scale Evolution of Image Classifiers》和《Regularized Evolution for Image Classifier Architecture Search》。
从 5 亿年前的超简单的蠕虫脑到今天的各种各样的现代结构,大脑经历了漫长的进化过程。例如,人类大脑可以指导完成非常广泛的活动,大部分活动都能轻而易举地完成,例如辨别一个视觉场景中是否包含动物或建筑对我们来说是很简单的事。而要执行类似的活动,人工神经网络需要专家数年的艰苦研究、精心设计,且通常只能执行单个具体的任务,例如识别照片中的目标、调用遗传变异,或者帮助诊断疾病等。人们希望拥有自动化的方法,为任意给定的任务生成合适的网络架构。
使用进化算法生成这些架构是其中一种方法。传统的拓扑神经进化研究(如《Evolving Neural Networks through Augmenting Topologies》Stanley and Miikkulainen,2002)为大规模应用进化算法奠定了基础,很多团队都在研究这个主题,例如 OpenAI、Uber Labs、Sentient Labs 和 DeepMind。当然,Google Brain 团队也在尝试用 AutoML 执行架构搜索。除了基于学习的方法(如强化学习),谷歌想了解使用谷歌的计算资源以前所未有的规模来程序化地演化图像分类器,会得到什么样的结果。可以用最少的专家参与获得足够好的解决方案吗?目前的人工进化神经网络能达到什么样的程度?谷歌通过两篇论文来解决这个问题。
在 ICML 2017 大会中展示的论文《Large-Scale Evolution of Image Classifiers》中,谷歌用简单的构建模块和常用的初始条件设置了一个进化过程。其主要思想是让人「袖手旁观」,让进化算法大规模构建网络架构。当时,从非常简单的网络开始,该过程可以找到与手动设计模型性能相当的分类器。这个结果振奋人心,因为很多应用可能需要较少的用户参与。例如,一些用户可能需要更好的模型,但没有足够的时间成为机器学习专家。接下来要考虑的问题自然就是手动设计和进化的组合能不能获得比多带带使用一个方法更好的结果。因此,在近期论文《Regularized Evolution for Image Classifier Architecture Search》(2018)中,谷歌通过提供复杂的构建模块和较好的初始条件(参见下文)来参与进化过程。此外,谷歌还使用其新型 TPUv2 芯片来扩大计算规模。通过现代硬件、专家知识和进化过程的组合,谷歌获得了在两个流行的图像分类基准 CIFAR-10 和 ImageNet 上的当前最优模型。
简单方法
接下来我们介绍第一篇论文中的一个例子。下图中,每个点都是一个在 CIFAR-10 数据集(通常用于训练图像分类器)上训练的神经网络。在初始阶段,该群体中有 1000 个相同的简单种子模型(没有隐藏层)。从简单的种子模型开始非常重要:假如从初始条件包含专家知识的高质量模型开始,则系统将更容易最终获得高质量模型。而一旦从简单的模型开始,进化过程就可以随时间步逐渐提高模型质量。在每个时间步,进化算法会随机选择一对神经网络,具备更高准确率的网络被选为亲代网络,并通过复制和变异获得子代网络,然后该子代网络被加入原来的群体中,而另一个准确率较低的网络则被移除。在这个时间步内,所有其它的网络都保持不变。通过持续应用多个此类时间步,该群体得以不断进化。

进化实验过程。每个点表示群体中的一个个体。四个 diagram 是算法发现的架构。它们对应较佳个体(最右、通过验证准确率选出)及其三个 ancestor。
谷歌第一篇论文中的变异设置得很简单:随机删除卷积层,在任意层之间添加 skip connection,或者改变学习率等等。通过这种方式,研究结果证实了进化算法的潜力,与搜索空间的质量成反比。例如,如果我们使用单个变异,在某一步将一个种子网络变换成 Inception-ResNet 分类器,那么我们会错误地认为该算法找到了优秀的答案。但是,在那种情况中,我们只能将最终答案硬编码为复杂的变异,控制输出。而如果我们坚持使用简单的变异,则这种情况不会发生,进化算法能够真正完成任务。在图中的实验中,简单的变异和选择过程导致网络随着时间不断改进,并达到了很高的测试准确率,且测试集在训练过程中不曾出现。在这篇论文中,网络可以继承其亲代网络的权重。因此,除了促进架构进化以外,群体可以训练其网络,同时探索初始条件和学习率调度(learning-rate schedule)的搜索空间。因此,该过程获得了完全训练的模型,且该模型具备优化过的超参数。实验开始后不需要专家输入。
上述情况中,即使我们通过掌握简单的初始架构和直观变异最小化研究人员的参与,这些架构的构建模块中也存在大量专家知识,包括卷积、ReLU 和批归一化层等重要创新。谷歌对这些组件构成的架构进行了进化操作。「架构」一词并非偶然:它就像用高质量砖石建筑房屋。
结合进化和手动设计
在第一篇论文发布后,谷歌想通过给予算法更少探索选择来减少搜索空间,提高可控性。就像刚才那个关于架构的类比一样,谷歌去除了搜索空间中所有可能导致大型误差的方式,比如建筑房屋时把墙建在屋顶上。类似地,在神经网络架构搜索方面,固定网络的大尺度结构可以为算法解决问题提供一定的帮助。例如,Zoph et al. (《Learning Transferable Architectures for Scalable Image Recognition》) 论文中提出的用于架构搜索的类 inception 模块非常强大。他们想构建一个重复模块 cell 的深度堆叠结构。该堆叠是固定的,但是单个模块的架构可以改变。

Zoph et al. (2017) 论文中提到的构建模块。左侧是完整神经网络的外部结构,自下而上地通过一串堆叠的重复 cell 解析输入数据。右侧是 cell 的内部结构。算法旨在寻找能够获取准确网络的 cell。
在第二篇论文《Regularized Evolution for Image Classifier Architecture Search》中,谷歌展示了将进化算法应用到上述搜索空间的结果。通过随机重连输入(上图右侧的箭头)或随机替换操作(如将图中的较大池化操作「max 3x3」替换成任意其他可替换操作)等变异来修改 cell。这些变异仍然比较简单,但是初始条件并不简单:群体中初始化的模型必须遵从 cell 外部堆叠(由专家设计)。尽管这些种子模型中的 cell 是随机的,但是我们不再从简单模型开始,这样更易获得高质量模型。如果进化算法发挥出很大作用,则最终网络应该显著优于我们目前已知的可在该搜索空间内构建的网络。这篇论文展示了进化算法确实能够找到当前最优的模型,可匹配甚至优于手动设计的搜索方式。
受控比较
尽管变异/选择进化过程并不复杂,但可能存在更直接的方法(如随机搜索)可以达到同样的效果。其他方法尽管并不比进化算法简单,但仍然存在(如强化学习)。因此,谷歌第二篇论文的主要目的是提供不同技术之间的受控比较。
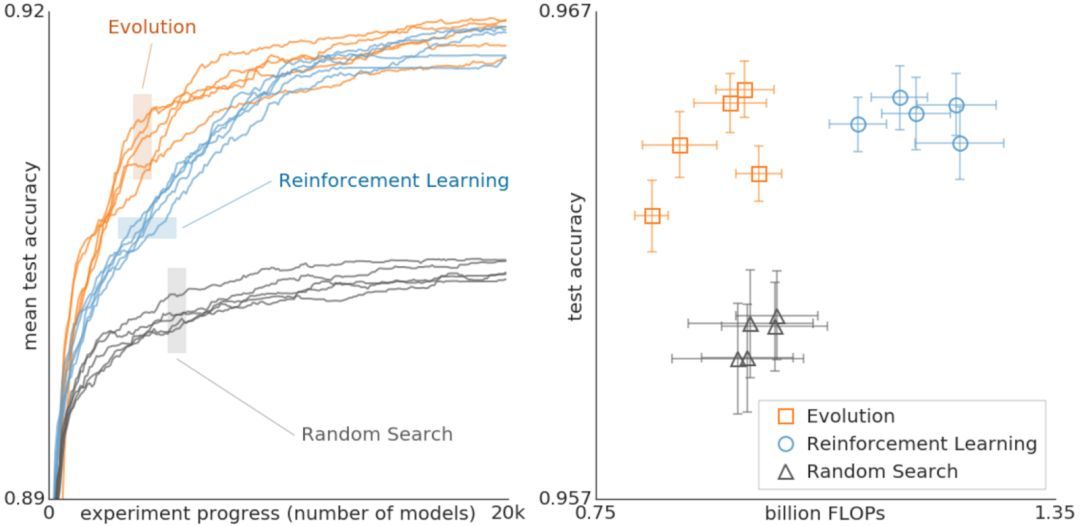
进化算法、强化学习与随机搜索分别执行架构搜索时的对比结果。这些实验是在 CIFAR-10 数据集上完成的,条件和 Zoph 等人 2017 年的论文一样,其中的搜索空间最初使用强化学习。
上图对比了进化算法、强化学习与随机搜索。左图,每个曲线表示实验的进程,结果表明进化算法在搜索的早期阶段要比强化学习快。这非常重要,因为在计算资源有限的情况下,实验可能不得不早早结束。此外,进化算法对数据集或者搜索空间的变化具备很强的稳健性。总之,这一受控对比旨在向研究社区提供该计算成本高昂的实验的结果。谷歌希望通过提供不同搜索算法之间关系的案例分析,为社区做架构搜索提供帮助。这里面有些需要注意的东西,例如,上图中表明,尽管使用更少的浮点运算,进化算法获得的最终模型也能达到很高的准确率。
在第二篇论文中,谷歌所用进化算法的一大重要特征是采用了一种正则化形式:相比于移除最差的神经网络,他们移除了最老的神经网络(无论它有多好)。这提升了对任务优化时所发生变化的稳健性,并最终更可能得到更加准确的网络。其中一个原因可能是由于不允许权重继承,所有的网络必须都从头开始训练。因此,这种形式的正则化选择重新训练后依旧较好的网络。也就是说,得到更加准确的模型只是偶然的,训练过程中存在的噪声意味着即使完全相同的架构准确率也可能不同。更多细节可参看论文《Regularized Evolution for Image Classifier Architecture Search》。
谷歌开发出的当前最优模型叫作 AmoebaNet,这也是从 AutoML 中发展出的成果。所有实验都需要大量算力,谷歌使用数百 GPU/TPU 运行了数天。
原文链接:https://research.googleblog.com/2018/03/using-evolutionary-automl-to-discover.html
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4725.html
摘要:今年月,谷歌发布了。在谷歌内部被称为的方法中,一个控制器神经网络可以提出一个子模型架构,然后可以在特定任务中对其进行训练和评估质量。对于整个领域来说,一定是下一个时代发展重点,并且极有可能是机器学习的大杀器。 为什么我们需要 AutoML?在谈论这个问题之前,我们需要先弄清楚机器学习的一般步骤。其实,不论是图像识别、语音识别还是其他的机器学习项目,其结构差别是很小的,一个效果好的模型需要大量...
摘要:据介绍,在谷歌近期的强化学习和基于进化的的基础上构建,快速灵活同时能够提供学习保证。刚刚,谷歌发布博客,开源了基于的轻量级框架,该框架可以使用少量专家干预来自动学习高质量模型。 TensorFlow 是相对高阶的机器学习库,用户可以方便地用它设计神经网络结构,而不必为了追求高效率的实现亲自写 C++或 CUDA 代码。它和 Theano 一样都支持自动求导,用户不需要再通过反向传播求解...

阅读 3270·2021-10-13 09:40
阅读 3810·2019-08-30 15:54
阅读 1351·2019-08-30 13:20
阅读 3041·2019-08-30 11:26
阅读 519·2019-08-29 11:33
阅读 1133·2019-08-26 14:00
阅读 2401·2019-08-26 13:58
阅读 3413·2019-08-26 10:39




