
摘要:在此,我们将借用和的算子,分析硬件加速的需求。池化层池化层主要用于尺度变换,提取高维特征。此种类型主要用于深度卷积神经网络中卷积部分与部分的连接。和可以认为是的特例。
NNVM是由陈天奇团队提出的一套可复用的计算流图中间表达层,它提供了一套精简的API函数,用以构建、表达和传输计算流图,从而便于高层级优化。另外NNVM也可以作为多个深度学习框架的共享编译器,可以优化、编译和部署在多种不同的硬件后端。其特点是部署的模型拥有最小依赖,可加入新的操作(operators),可将新的优化通路加入到现有的图结构中。从NNVM的观点看,它可用于将M个框架,N个机器之间构建一个单一的纽带,以实现各种框架向各种实现平台的无差别部署。如图所示。
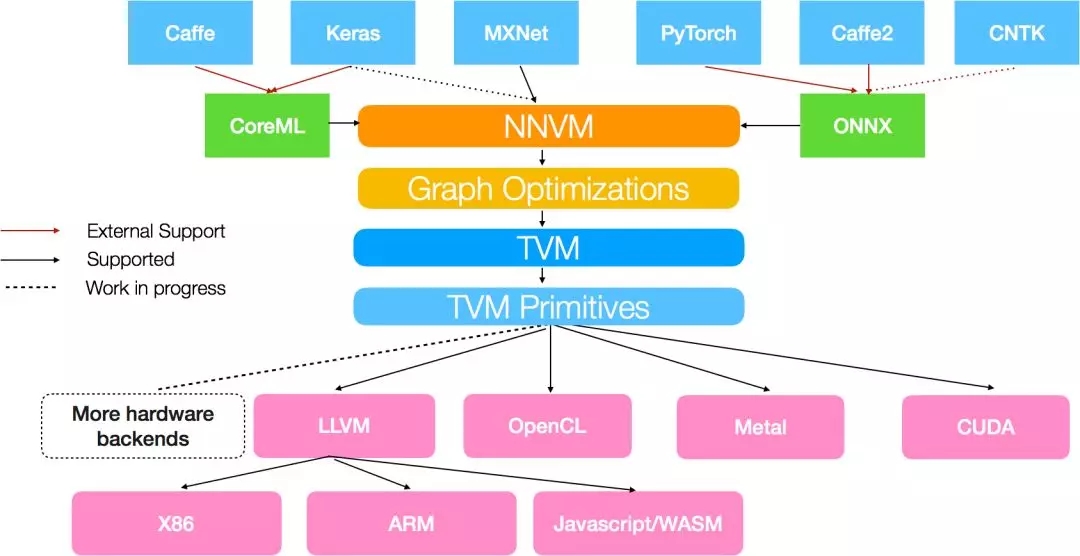
ONNX[1]是Facebook联合微软和AWS推出的开源的深度学习表示格式。通过ONNX,AI开发人员可以容易地在不同模型和工具间转换,并将工具组合使用。目前可以支持Caffe2, CNTK, PyTorch等主流模型,也对Tensorflow提供了早期支持。一下是ONNX的一些基本信息(来自ONNX网站[1])。



严格而言,和NNVM相比,ONNX更像是一个协议转换器,可以在各个框架之间进行转换。
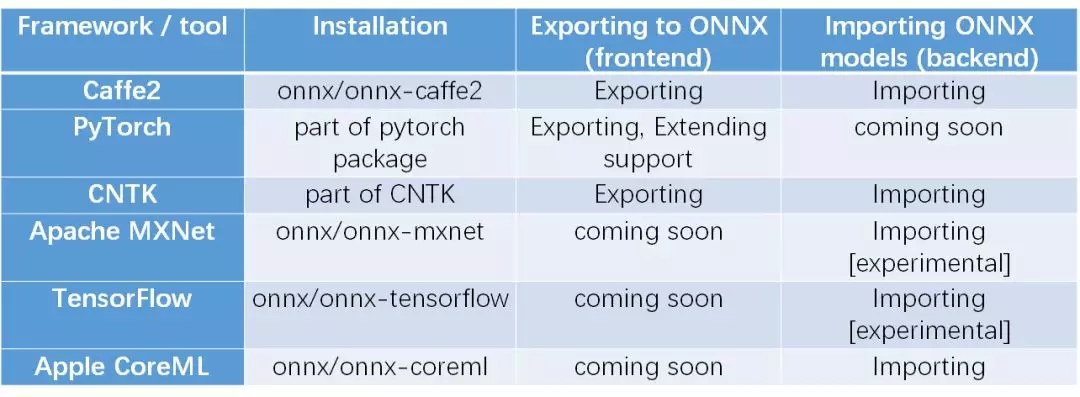
目前多种标准的转换工具已经开发了出来,如表格所示。
在此,我们将借用NNVM和ONNX的算子,分析AI硬件加速的需求。这些算子都包含了相关参数,在此不细致表述。有关这些算子的完整解释,可以查看ONNX的官方表述[2];NNVM目前的版本是0.8,因此本文参考版本0.8。算子的官方解释参见[3]。
ONNX以张量(Tensor)作为输入输出数据格式,可以认为是多维数组。主要支持如下的数据格式:tensor(float16), tensor(float), tensor(double)。目前还不太支持定点,但提供了定点化的一些函数,如floor, ceil, clip, cast等。NNVM也以Tensor作为数据格式。
ONNX不完整支持神经网络的训练,但它提供了训练所需要的完整的图描述,其实就是对BN和dropout两个功能上加了一个区别参数,用来描述可训练的图和不可训练的图。由于ONNX实际上就是把各种框架的图转换成了它自己的Operator表示的图,它只负责描述这个图的结构,具体前后向的计算都需要一个执行框架(称为后端)。 因此,如果需要实现训练,需要实现系统根据这个图自动实现所有的反向过程的微分算子,并且实现loss函数。此外,还需要编译器根据这个前向图结构推演出反向图的各个步骤,这个过程可以是工具链自动的。而对于前向而言,基本不需要转化就可以直接部署在支持这些算子的实现平台上。
本人对这些算子进行了一个简单的归类,并将ONNX和NVM进行了比对。由于在硬件实现上,不同的算子的实现复杂度是不同的,因此加入了Complexity的度量。另外,根据当前神经网络在图像/语音/文本三方面的应用情况,对这些算子的使用频率进行了估计。由于应用领域和硬件平台各不相同,因此复杂度和使用频率仅作参考。
1. 深度神经网络计算
1.1. 计算层
这部分算子是深度网络的核心,用于将输入的神经元激活值与突触连接强度(权重)进行积分求和,得到新的神经元的模电位。根据是否滑窗,是否具有时序结构,可分为如下几种算子,其中FC(全连接)是多层感知机(MLP)的基础,Conv和FC是深度卷积神经网络的基础。RNN, GRU, LSTM是带有时序结构的神经网络模型,主要用于非静态图像的场合,例如语音/文字/视频等。可见,ONNX的关注面比较全面,包括了时序模型,而NNVM暂时还没有包括时序模型。
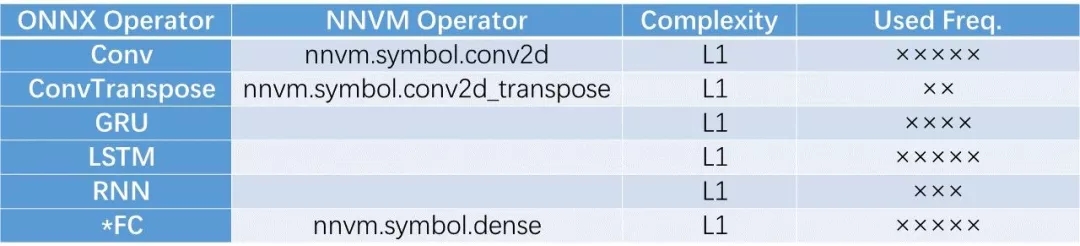
注: (*)代表ONNX库中此函数带有实验阶段(Experimental)标志。下同。
1.2 池化层
池化层主要用于尺度变换,提取高维特征。主要分三种池化,第一种是局部池化,在图像维度上,几个相邻的点被缩减为一个输出点,在Channel维度上不变。包括计算相邻点的平均值(AveragePool),较大值(MaxPool),范数(LpPool)。主要用于图像的尺寸变换。第二种是全局的池化,此时一个Channel的所有数据点缩为1个点,因此有几个Channel就输出几个数据点。此种类型主要用于深度卷积神经网络中卷积部分与FC部分的连接。第三种是ROI-pooling,用于Faster-RCNN等检测识别网络中对感兴趣区域进行尺度归一化,从而输入到识别网络进行识别处理。可见,ONNX实现了比较全面的算子覆盖,NNVM实现了比较常见的局部池化和全局池化,但是暂时还没有实现ROI-pool。

1.3 批数据归一化层
归一化层作为一个特殊层,可用于数据的归一化,提高神经网络的性能,降低训练时间。对于带有残差的神经网络非常重要。目前高性能网络大多带有归一化层,而绝大多数都会采用Batch Normalization(BN)。BN前向操作并不复杂,但反向比较复杂,因此用于训练的BN需要加入更多的子层。ONNX构建了两套图描述,用标志位进行区分,用户可以选择是用于训练的还是仅用于前向的。另外,ONNX还提供了在这方面其他的选择,例如Instance归一化 (y = scale * (x - mean) / sqrt(variance + epsilon) + B)和基于范数的归一化,LRN被用在AlexNet等早期设计,目前用的比较少。对比之下,NNVM只支持了BN,可以覆盖约95%的应用情形。

1.4. 数据归一化
将数据进行归一化处理,通常用于输出层的归一化。

1.5. 其他计算层
在进行训练时,DropOut随机扔掉一些通路,可以用于防止过拟合。这方面两个框架都实现了。Embedding用于将词转换为高维表达,是文本的预处理的主要步骤。GRUUnit是个试验性函数,功能类似于GRU的激活层。

2. 基础Tensor运算
2.1 逐元素运算(element-wise)类
这个类别包括了Tensor的一些基础运算,由于输出的数据点只跟对应的那一个输入的数据点有关系,因此可以称为element-wise运算,这类运算与输入的数据的维度和结构无关,可以等价的认为是一维向量运算的Tensor等效表示。由于输入数据可能是各种维度,也可以是标量,因此此中的操作都是维度兼容的。一种特殊情况是输入的参数中,一个是向量,另一个是标量,此时,NNVM区别对待,而ONNX将其统一处理。在此处,ONNX只支持了Tensor-Scalar,不支持scalar-tensor, 而NNVM两者都支持。除法情况类似。对于加减乘除,ONNX自带broadcast操作,而NNVM通过多带带函数实现。ONNX对逻辑运算和比较运算提供了支持,而NVVM没有。另外ONNX提供了一些数据格式转换(cast)和量化方面的函数(clip, floor, ceil),而NVVM暂时不支持。两者都对指数运算和对数运算,开方运算提供了支持,可是这两个函数其实是加速芯片比较难较精确实现的函数(可以通过查找表或近似函数实现)。
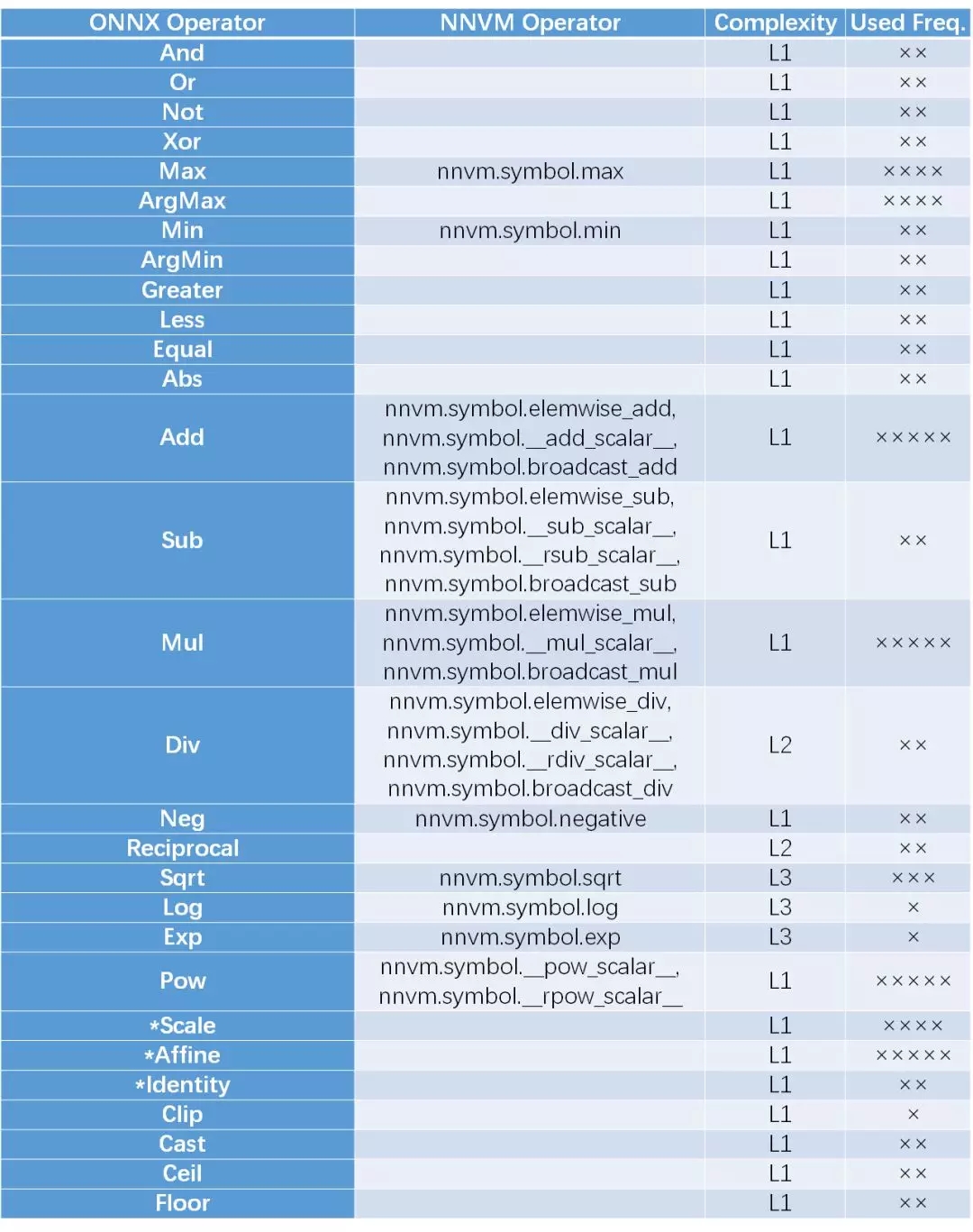
2.2 Tensor/矩阵处理类
这部分操作是对整个Tensor的数据进行的,即输出可能关系到Tensor中的不止一个数据。包括求和,求平均,通用矩阵运算(Gemm),矩阵乘法,图像缩放等。其中Gemm是矩阵处理的通用表达形式,即Y = alpha * A * B + beta * C。其中A 为M X K维, B为K X N维,C和Y为M X N维。可以认为NNVM目前还缺乏对通用矩阵运算的支持。

2.3 激活和非线性函数
激活函数提供了神经网络的非线性拟合能力,不同的激活函数具有各自的性能特点。由于ReLU简单且性能较好,因此一般图像处理算法采用ReLU函数。而Sigmoid和Tanh在LSTM/GRU/RNN中较为常见。这些函数可以认为是2.1中所述的element-wise算子,但为了表达其在神经网络中的特殊功用,在此多带带提出。
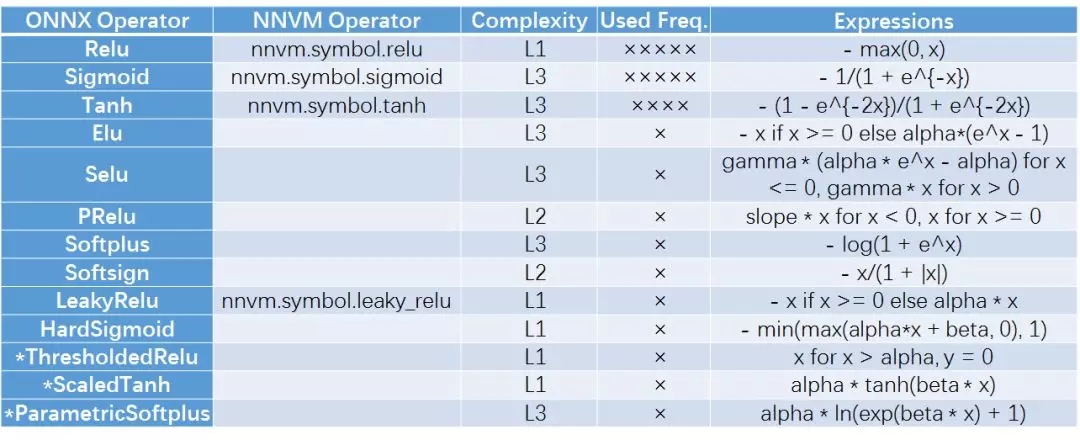
2.4. 随机数和常数
这些操作用于产生数据,包括正态随机产生,均匀随机产生,常数等。可以看出ONNX支持随机数加入到图中,而NNVM目前还不支持图中包括随机数。

2.5. 降维系列
降维系列是ONNX特有的。可以指定哪些维度根据某个计算度量去除。由于计算度量的方法比较多,本人认为功能类似于Global pooling。这些方法在神经网络应用中不是很多,NNVM目前还不支持这些方法。

3. Tensor变换
此部分算子不会改变Tensor的数据,只会对数据的位置和维度进行调整。
3.1. 分割组合算子
此部分可以将多个Tensor合并成一个,或者将一个拆分为多个。可以用于分组卷积等。

3.2. 索引变换
索引变换包括Reshape, 矩阵转置,空间维度与Feature Map互换等。可以认为是数据排布关系的变化。Flatten和Squeeze可以认为是Reshape的特例。

3.3. 数据选取
此部分操作可以根据维度参数、边框或者脚标矩阵参数选取Tensor的部分数据,或者对Tensor的数据进行复制拓展。

3.4. 数据填充
数据填充分为边缘补0,常数填充和拷贝。其中NNVM没有在官方文档页面中提供fill函数的解释,但是确实存在这个函数。

综上,我们总结了作为IR表示层的所有操作(Operator)。将这些操作连接起来就构成了数据流图,使得神经网络可以表达为一个基于Operator和Tensor的有向图。采用Netron[4]可以查看ONNX的数据流图,具有很好的可视化体验。推荐大家可以尝试。不过NNVM目前好像还没有类似的工具。
另外,总体感觉是ONNX的灵活度高于NNVM,尤其是在RNN的支持上边,但NNVM给大家提供了一个很好的范例,用以说明如何抓住重点,覆盖典型的应用场景。另外,NNVM提供了一个很好的扩展机制,用户可以将自己的原子操作加入到框架中去而不改变原有的框架结构。上文中提及的可以认为是本征支持的操作(native operation)。
对于一个视频/图像类神经网络芯片,可以先考虑支持NNVM所支持的本征原语部分,如果有需要,再向着ONNX的更多操作扩展。而对于文本/语音处理而言,ONNX是比较好的考评量度。也许将来大家在进行加速器的功能比拼时,会以ONNX框架提供的兼容性为尺度。
另外,值得注意的是,要做到对一个操作的支持,并不只是有没有的问题,还包括执行效率的问题。后者可以从功耗效率的角度来衡量,也可以从有效计算能力和峰值计算能力的比值看出来。因此想设计一个高灵活的神经网络芯片还是一个各方面权衡,灵活度与性能联合调优的过程。
[ Reference ]
[1] Open Neural Network Exchange (ONNX), https://onnx.ai/
[2] ONNX Operator Schemas, https://github.com/onnx/onnx/blob/master/docs/Operators.md
[3] NNVM Core Tensor Operators, http://nnvm.tvmlang.org/top.html#detailed-definitions
[4] NETRON, https://github.com/lutzroeder/Netron
作者简介:
吴臻志博士,清华大学类脑计算研究中心助理研究员。专长神经网络芯片设计,众核芯片设计,神经网络高效实现等。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4724.html
摘要:亚马逊和华盛顿大学今天合作发布了开源的端到端深度学习编译器。项目作者之一陈天奇在微博上这样介绍这个编译器我们今天发布了基于工具链的深度学习编译器。陈天奇团队对的性能进行了基准测试,并与进行了比较。 亚马逊和华盛顿大学今天合作发布了开源的端到端深度学习编译器NNVM compiler。先提醒一句,NNVM compiler ≠ NNVM。NNVM是华盛顿大学博士陈天奇等人2016年发布的模块化...
摘要:两者取长补短,所以深度学习框架在年,迎来了前后端开发的黄金时代。陈天奇在今年的中,总结了计算图优化的三个点依赖性剪枝分为前向传播剪枝,例已知,,求反向传播剪枝例,,求,根据用户的求解需求,可以剪掉没有求解的图分支。 虚拟框架杀入从发现问题到解决问题半年前的这时候,暑假,我在SIAT MMLAB实习。看着同事一会儿跑Torch,一会儿跑MXNet,一会儿跑Theano。SIAT的服务器一般是不...
摘要:如何进行操作本文将介绍在有道云笔记中用于文档识别的实践过程,以及都有些哪些特性,供大家参考。年月发布后,有道技术团队第一时间跟进框架,并很快将其用在了有道云笔记产品中。微软雅黑宋体以下是在有道云笔记中用于文档识别的实践过程。 这一两年来,在移动端实现实时的人工智能已经形成了一波潮流。去年,谷歌推出面向移动端和嵌入式的神经网络计算框架TensorFlowLite,将这股潮流继续往前推。Tens...
摘要:据悉,在旧金山举行的高通活动上,这家巨头正式宣布进军云计算市场,并发布了面向人工智能推理计算的专用加速器。没有任何预告,继谷歌亚马逊和英伟达之后,高通成为第四家成功在云端推理上正式发布芯片的公司。提起高通,业内对它的直接印象就是移动芯片领域的巨头。一直以来,高通也确实只在移动通信领域深耕,并从芯片到底层平台一揽子都包下。而现在,高通冷不丁扔出的一枚炸弹也将一改以往大家对它的认知。据悉,在旧金...
摘要:近日,与微软联合推出了开放式神经网络交换格式,它是一个表征深度学习模型的标准,可实现模型在不同框架之间的迁移。例如,在中,条件句通常是对输入张量的大小或维度上的计算。 近日,Facebook 与微软联合推出了开放式神经网络交换(ONNX)格式,它是一个表征深度学习模型的标准,可实现模型在不同框架之间的迁移。ONNX 是构建开源生态环境的第一步,供人工智能开发者轻松选择并组合较先进的工具。开发...

阅读 2312·2021-11-15 11:39
阅读 1097·2021-09-26 09:55
阅读 1005·2021-09-04 16:48
阅读 2976·2021-08-12 13:23
阅读 989·2021-07-30 15:30
阅读 2520·2019-08-29 14:16
阅读 957·2019-08-26 10:15
阅读 588·2019-08-23 18:40






