
摘要:目前,生成对抗网络的大部分应用都是在计算机视觉领域。生成对抗网络生成对抗网络框架是由等人于年设计的生成模型。在设置中,两个由神经网络进行表示的可微函数被锁定在一个游戏中。我们提出了深度卷积生成对抗网络的实现。
让我们假设这样一种情景:你的邻居正在举办一场非常酷的聚会,你非常想去参加。但有要参加聚会的话,你需要一张特价票,而这个票早就已经卖完了。
而对于这次聚会的组织者来说,为了让聚会能够成功举办,他们雇佣了一个合格的安全机构。主要目标就是不允许任何人破坏这次的聚会。为了做到这一点,他们在会场入口处安置了很多警卫,检查每个人所持门票的真实性。
考虑到你没有任何武术上的天赋,而你又特别想去参加聚会,那么的办法就是用一张非常有说服力的假票来骗他们。
但是这个计划存在一个很大的bug——你从来没有真正看到过这张门票到底是什么样的。所以,在这种情况下,如果你仅是根据自己的创造力设计了一张门票,那么在第一次尝试期间就想要骗过警卫几乎是不可能的。除此之外,除非你有一个很好的关于此次聚会的门票的复印件,否则你较好不要把你的脸展露出来。
为了帮助解决问题,你决定打电话给你的朋友Bob为你做这个工作。
Bob的任务非常简单。他会试图用你的假通行证进入聚会。如果他被拒绝了,他将返回,然后告诉你一些有关真正的门票应该是什么样的建议。
基于这个反馈,你可以制作一张全新版本的门票,然后将其交给Bob,再去检票处尝试一下。这个过程不断重复,直到你能够设计一个完美的门票“复制品”。
这是一个必须去的派对。而下面这张照片,其实是我其实从一个假票据生成器器网站上拿到的。

对于上面这个小故事,抛开里面的假想成分,这几乎就是生成对抗网络(GAN)的工作方式。
目前,生成对抗网络的大部分应用都是在计算机视觉领域。其中一些应用包括训练半监督分类器,以及从低分辨率图像中生成高分辨率图像。
本篇文章对GAN进行了一些介绍,并对图像生成问题进行了实际实践。你可以在你的笔记本电脑上进行演示。
生成对抗网络(Generative Adversarial Networks)
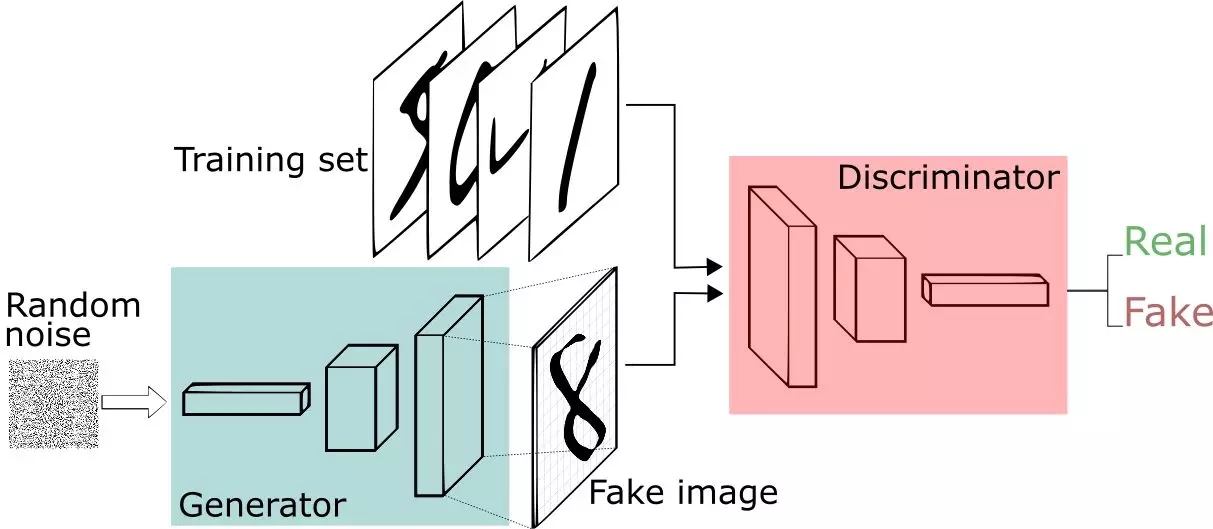
生成对抗网络框架
GAN是由Goodfellow等人于2014年设计的生成模型。在GAN设置中,两个由神经网络进行表示的可微函数被锁定在一个游戏中。这两个参与者(生成器和鉴别器)在这个框架中要扮演不同的角色。
生成器试图生成来自某种概率分布的数据。即你想重新生成一张聚会的门票。
鉴别器就像一个法官。它可以决定输入是来自生成器还是来自真正的训练集。这就像是聚会中的安保设置,比将你的假票和这正的门票进行比较,以找到你的设计中存在的缺陷。


我们将一个4层卷积网络用于生成器和鉴别器,进行批量正则化。对该模型进行训练以生成SVHN和MNIST图像。以上是训练期间SVHN(上)和MNIST(下)生成器样本
总而言之,游戏如下:
•生成器试图较大化鉴别器将其输入错认为正确的的概率。
•鉴别器引导生成器生成更逼真的图像。
在完美的平衡状态中,生成器将捕获通用的训练数据分布。结果,鉴别器总是不确定其输入是否是真实的。
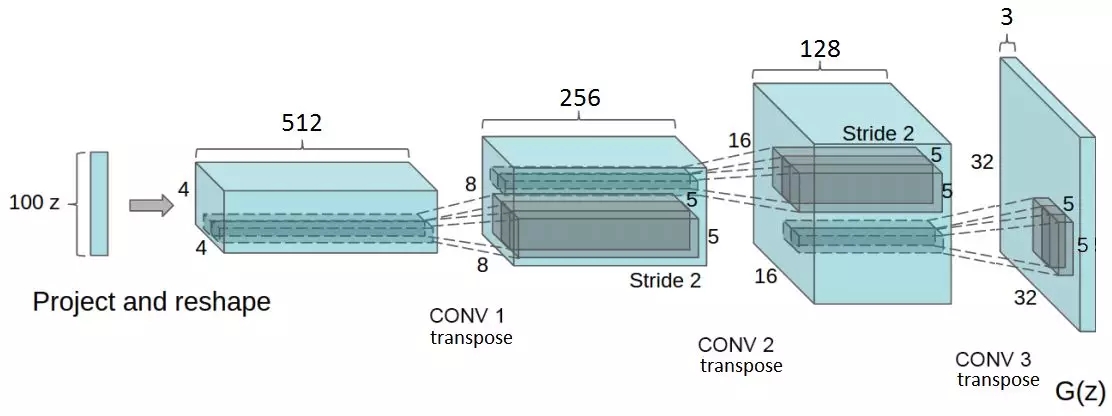
摘自DCGAN论文。生成器网络在这里实现。注意:完全连接层和池化层的不存在
在DCGAN论文中,作者描述了一些深度学习技术的组合,它们是训练GAN的关键。这些技术包括:(i)所有的卷积网络;(ii)批量正则化(BN)。
第一个强调的重点是带步幅的卷积(strided convolutions),而不是池化层:增加和减少特征的空间维度;第二个是,对特征向量进行正则化以使其在所有层中具有零均值和单位方差。这有助于稳定学习和处理权重不佳的初始化问题。
言归正传,在这里阐述一下实施细节,以及GAN的相关知识。我们提出了深度卷积生成对抗网络(DCGAN)的实现。我们的实现使用的是Tensorflow并遵循DCGAN论文中描述的一些实践方法。
生成器
该网络有4个卷积层,所有的位于BN(输出层除外)和校正线性单元(ReLU)激活之后。
它将随机向量z(从正态分布中抽取)作为输入。将z重塑为4D形状之后,将其馈送到启动一系列上采样层的生成器中。
每个上采样层都代表一个步幅为2的转置卷积(Transpose convolution)运算。转置卷积与常规卷积类似。
一般来说,常规卷积从宽且浅的层延展为更窄、更深的层。转移卷积走另一条路。他们从深而窄的层次走向更宽更浅。
转置卷积运算的步幅定义了输出层的大小。在“相同”的填充和步幅为2时,输出特征的大小将是输入层的两倍。
发生这种情况的原因是,每次我们移动输入层中的一个像素时,我们都会将输出层上的卷积内核移动两个像素。换句话说,输入图像中的每个像素都用于在输出图像中绘制一个正方形。
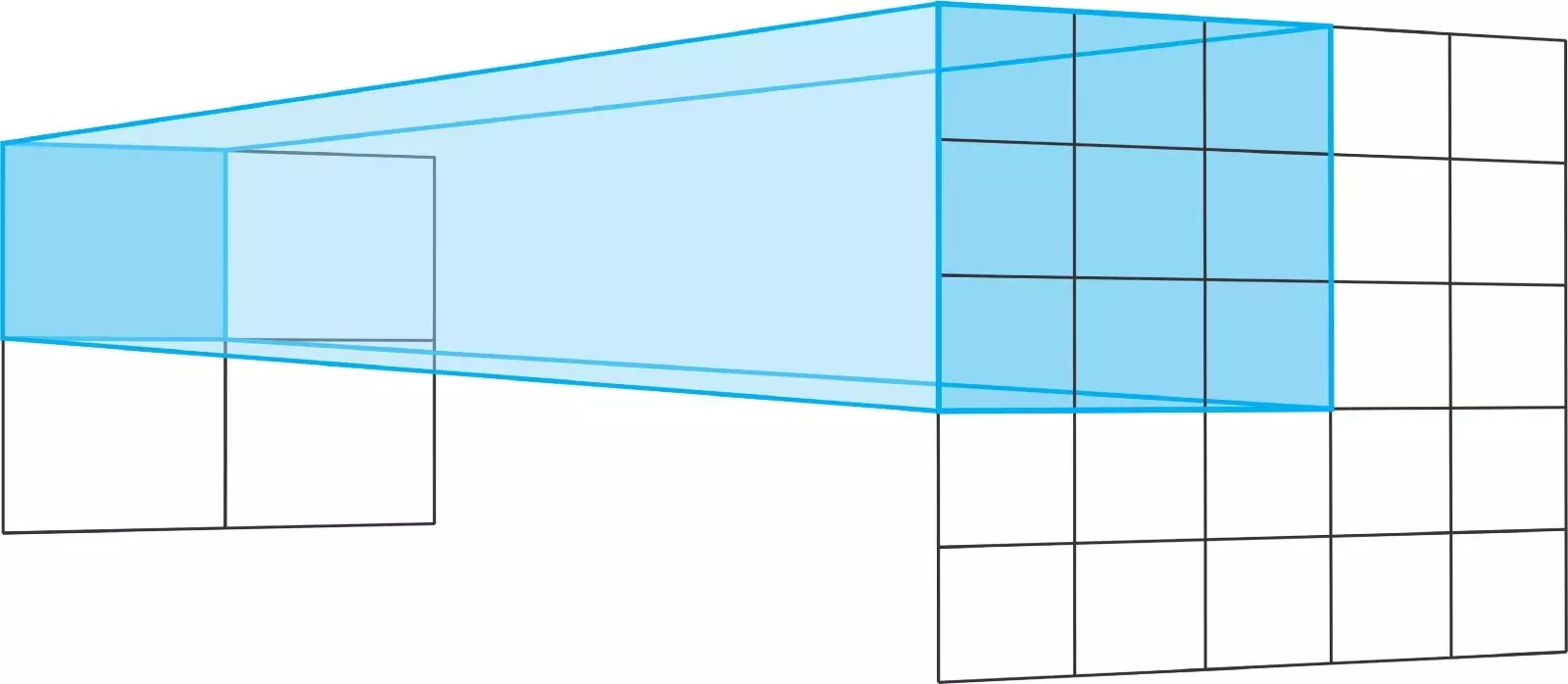
将一个3x3的内核在一个步幅为2的2x2输入上进行转置,就相当于将一个3x3的内核在一个步幅为2的5x5输入上进行卷积运算。对于二者,均不使用填充“有效”
简而言之,生成器开始于这个非常深但很窄的输入向量开始。在每次转置卷积之后,z变得更宽、更浅。所有的转置卷积都使用5x5内核的大小,且深度从512减少到3——代表RGB彩色图像。
def transpose_conv2d(x, output_space):
return tf.layers.conv2d_transpose(x, output_space,
kernel_size=5, strides=2, padding="same",
kernel_initializer=tf.random_normal_initializer(mean=0.0,
stddev=0.02))
最后一层通过双曲正切(tanh)函数输出一个32x32x3的张量——值在-1和1之间进行压缩。
这个最终的输出形状是由训练图像的大小来定义的。在这种情况下,如果是用于SVHN的训练,生成器生成32x32x3的图像。但是,如果是用于MNIST的训练,则会生成28x28的灰度图像。
最后,请注意,在将输入向量z馈送到生成器之前,我们需要将其缩放到-1到1的区间。这是遵循使用tanh函数的选择。
def generator(z, output_dim, reuse=False, alpha=0.2, training=True):
"""
Defines the generator network
:param z: input random vector z
:param output_dim: output dimension of the network
:param reuse: Indicates whether or not the existing model variables should be used or recreated
:param alpha: Scalar for lrelu activation function
:param training: Boolean for controlling the batch normalization statistics
:return: model"s output
"""
with tf.variable_scope("generator", reuse=reuse):
fc1 = dense(z, 4*4*512)
# Reshape it to start the convolutional stack
fc1 = tf.reshape(fc1, (-1, 4, 4, 512))
fc1 = batch_norm(fc1, training=training)
fc1 = tf.nn.relu(fc1)
t_conv1 = transpose_conv2d(fc1, 256)
t_conv1 = batch_norm(t_conv1, training=training)
t_conv1 = tf.nn.relu(t_conv1)
t_conv2 = transpose_conv2d(t_conv1, 128)
t_conv2 = batch_norm(t_conv2, training=training)
t_conv2 = tf.nn.relu(t_conv2)
logits = transpose_conv2d(t_conv2, output_dim)
out = tf.tanh(logits)
return out
鉴别器
鉴别器也是一个包含BN(除了其输入层之外)和leaky ReLU激活的4层CNN。许多激活函数都可以在这种基础GAN体系结构中进行良好的运算。但是leaky ReLUs有着非常广泛的应用,因为它们可以帮助梯度在结构中更轻易地流动。
常规的RELU函数通过将负值截断为0来工作。这样做的效果是阻止梯度流通过网络。leaky ReLU允许一个小负值通过,而非要求函数为0。也就是说,函数用来计算特征与小因素之间的较大值。
def lrelu(x, alpha=0.2):
# non-linear activation function
return tf.maximum(alpha * x, x)
leaky ReLU表示了一种解决崩溃边缘ReLU问题的尝试。这种情况发生在神经元陷于某一特定情况下,此时ReLU单元对于任何输入都输出0。对于这些情况,梯度完全关闭以通过网络回流。
这对于GAN来说尤为重要,因为生成器必须学习的方法是接受来自鉴别器的梯度。
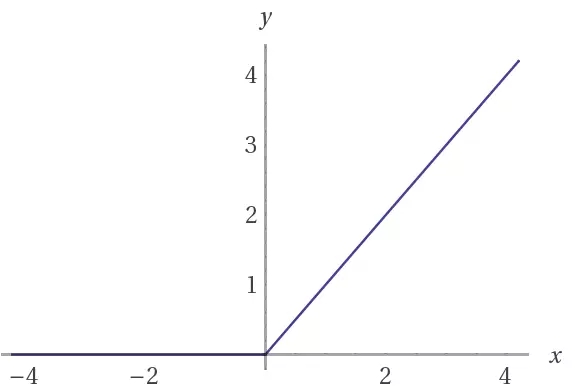
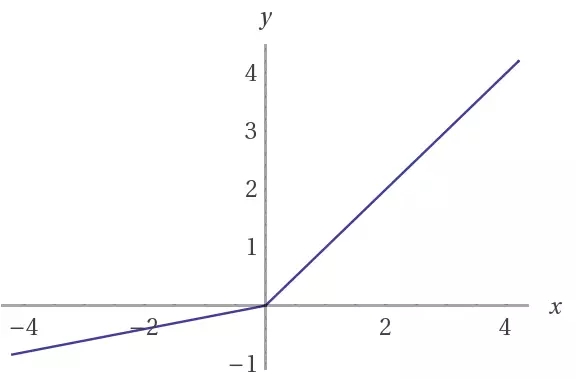
(上)ReLU,(下)leaky ReLU激活函数。 请注意,当x为负值时, leaky ReLU允许有一个小的斜率
这个鉴别器首先接收一个32x32x3的图像张量。与生成器相反的是,鉴别器执行一系列步幅为2的卷积。每一种方法都是通过将特征向量的空间维度缩小一半,从而使学习过滤器的数量加倍。
最后,鉴别器需要输出概率。为此,我们在最后的逻辑(logits)上使用Logistic Sigmoid激活函数。
def discriminator(x, reuse=False, alpha=0.2, training=True):
"""
Defines the discriminator network
:param x: input for network
:param reuse: Indicates whether or not the existing model variables should be used or recreated
:param alpha: scalar for lrelu activation function
:param training: Boolean for controlling the batch normalization statistics
:return: A tuple of (sigmoid probabilities, logits)
"""
with tf.variable_scope("discriminator", reuse=reuse):
# Input layer is 32x32x?
conv1 = conv2d(x, 64)
conv1 = lrelu(conv1, alpha)
conv2 = conv2d(conv1, 128)
conv2 = batch_norm(conv2, training=training)
conv2 = lrelu(conv2, alpha)
conv3 = conv2d(conv2, 256)
conv3 = batch_norm(conv3, training=training)
conv3 = lrelu(conv3, alpha)
# Flatten it
flat = tf.reshape(conv3, (-1, 4*4*256))
logits = dense(flat, 1)
out = tf.sigmoid(logits)
return out, logits
需要注意的是,在这个框架中,鉴别器充当一个常规的二进制分类器。一半的时间从训练集接收图像,另一半时间从生成器接收图像。
回到我们的故事中,为了复制聚会的票,你的信息来源是朋友Bob的反馈。换言之,Bob在每次尝试期间向你提供的反馈的质量对于完成工作至关重要。
同样的,每次鉴别器注意到真实图像和虚假图像之间的差异时,都会向生成器发送一个信号。该信号是从鉴别器向生成器反向流动的梯度。通过接收它,生成器能够调整其参数以接近真实的数据分布。
这就是鉴别器的重要性所在。实际上,生成器将要尽可能好地产生数据,因为鉴别器正在不断地缩小真实和虚假数据的差距。
损失
现在,让我们来描述这一结构中最棘手的部分——损失。首先,我们知道鉴别器收集来自训练集和生成器的图像。
我们希望鉴别器能够区分真实和虚假的图像。我们每次通过鉴别器运行一个小批量(mini-batch)的时候,都会得到逻辑(logits)。这些是来自模型的未缩放值(unscaled values)。
然而,我们可以将鉴别器接收的小批量(mini-batches)分成两种类型。第一种类型只由来自训练集的真实图像组成,第二种类型只包含由生成器生成的假图像。
def model_loss(input_real, input_z, output_dim, alpha=0.2, smooth=0.1):
"""
Get the loss for the discriminator and generator
:param input_real: Images from the real dataset
:param input_z: random vector z
:param out_channel_dim: The number of channels in the output image
:param smooth: label smothing scalar
:return: A tuple of (discriminator loss, generator loss)
"""
g_model = generator(input_z, output_dim, alpha=alpha)
d_model_real, d_logits_real = discriminator(input_real, alpha=alpha)
d_model_fake, d_logits_fake = discriminator(g_model, reuse=True, alpha=alpha)
# for the real images, we want them to be classified as positives,
# so we want their labels to be all ones.
# notice here we use label smoothing for helping the discriminator to generalize better.
# Label smoothing works by avoiding the classifier to make extreme predictions when extrapolating.
d_loss_real = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real, labels=tf.ones_like(d_logits_real) * (1 - smooth)))
# for the fake images produced by the generator, we want the discriminator to clissify them as false images,
# so we set their labels to be all zeros.
d_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, labels=tf.zeros_like(d_model_fake)))
# since the generator wants the discriminator to output 1s for its images, it uses the discriminator logits for the
# fake images and assign labels of 1s to them.
g_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, labels=tf.ones_like(d_model_fake)))
d_loss = d_loss_real + d_loss_fake
return d_loss, g_loss
由于两个网络同时进行训练,因此GAN需要两个优化器。它们分别用于最小化鉴别器和发生器的损失函数。
我们希望鉴别器输出真实图像的概率接近于1,输出假图像的概率接近于0。要做到这一点,鉴别器需要两部分损失。因此,鉴别器的总损失是这两部分损失之和。其中一部分损失用于将真实图像的概率较大化,另一部分损失用于将假图像的概率最小化。

比较真实(左)和生成的(右)SVHN样本图像。虽然有些图像看起来很模糊,且有些图像很难识别,但值得注意的是,数据分布是由模型捕获的
在训练开始的时候,会出现两个有趣的情况。首先,生成器不清楚如何创建与训练集中图像相似的图像。其次,鉴别器不清楚如何将接收到的图像分为真、假两类。
结果,鉴别器接收两种类型截然不同的批量(batches)。一个由训练集的真实图像组成,另一个包含含有噪声的信号。随着训练的不断进行,生成器输出的图像更加接近于训练集中的图像。这种情况是由生成器学习组成训练集图像的数据分布而造成的。
与此同时,鉴别器开始真正善于将样本分类为真或假。结果,这两种小批量(mini-batch)在结构上开始相互类似。因此,鉴别器无法识别出真实或虚假的图像。
对于损失,我们认为,使用具有Adam算法的vanilla交叉熵(vanilla cross-entropy)作为优化器是一个不错的选择。

比较real(左)和Generate(右)MNIST示例图像。由于MNIST图像具有更简单的数据结构,因此与SVHN相比,该模型能够生成更真实的样本
目前,GANs是机器学习中最热门的学科之一。这些模型具有解开无监督学习方法(unsupervised learning methods)的潜力,并且可以将ML拓展到新领域。
自从GANs诞生以来,研究人员开发了许多用于训练GANs的技术。在改进过后的GANs训练技术中,作者描述了图像生成(image generation)和半监督学习(semi-supervised learning)的技术。
原文链接:https://medium.freecodecamp.org/an-intuitive-introduction-to-generative-adversarial-networks-gans-7a2264a81394
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4722.html
摘要:引用格式王坤峰,苟超,段艳杰,林懿伦,郑心湖,王飞跃生成对抗网络的研究与展望自动化学报,论文作者王坤峰,苟超,段艳杰,林懿伦,郑心湖,王飞跃摘要生成式对抗网络目前已经成为人工智能学界一个热门的研究方向。本文概括了的研究进展并进行展望。 3月27日的新智元 2017 年技术峰会上,王飞跃教授作为特邀嘉宾将参加本次峰会的 Panel 环节,就如何看待中国 AI学术界论文数量多,但大师级人物少的现...
摘要:很多人可能会问这个故事和生成式对抗网络有什么关系其实,只要你能理解这段故事,就可以了解生成式对抗网络的工作原理。 男:哎,你看我给你拍的好不好?女:这是什么鬼,你不能学学XXX的构图吗?男:哦……男:这次你看我拍的行不行?女:你看看你的后期,再看看YYY的后期吧,呵呵男:哦……男:这次好点了吧?女:呵呵,我看你这辈子是学不会摄影了……男:这次呢?女:嗯,我拿去当头像了上面这段对话讲述了一位男...
摘要:但年在机器学习的较高级大会上,苹果团队的负责人宣布,公司已经允许自己的研发人员对外公布论文成果。苹果第一篇论文一经投放,便在年月日,斩获较佳论文。这项技术由的和开发,使用了生成对抗网络的机器学习方法。 GANs「对抗生成网络之父」Ian Goodfellow 在 ICCV 2017 上的 tutorial 演讲是聊他的代表作生成对抗网络(GAN/Generative Adversarial ...
摘要:我仍然用了一些时间才从神经科学转向机器学习。当我到了该读博的时候,我很难在的神经科学和的机器学习之间做出选择。 1.你学习机器学习的历程是什么?在学习机器学习时你最喜欢的书是什么?你遇到过什么死胡同吗?我学习机器学习的道路是漫长而曲折的。读高中时,我兴趣广泛,大部分和数学或科学没有太多关系。我用语音字母表编造了我自己的语言,我参加了很多创意写作和文学课程。高中毕业后,我进了大学,尽管我不想去...
摘要:是世界上最重要的研究者之一,他在谷歌大脑的竞争对手,由和创立工作过不长的一段时间,今年月重返,建立了一个探索生成模型的新研究团队。机器学习系统可以在这些假的而非真实的医疗记录进行训练。今年月在推特上表示是的,我在月底离开,并回到谷歌大脑。 理查德·费曼去世后,他教室的黑板上留下这样一句话:我不能创造的东西,我就不理解。(What I cannot create, I do not under...

阅读 3069·2021-10-27 14:15
阅读 3066·2021-09-07 10:18
阅读 1379·2019-08-30 15:53
阅读 1636·2019-08-26 18:18
阅读 3426·2019-08-26 12:15
阅读 3512·2019-08-26 10:43
阅读 700·2019-08-23 16:43
阅读 2257·2019-08-23 15:27






