
斯蒂文认为机器学习有时候像婴儿学习,特别是在物体识别上。比如婴儿首先学会识别边界和颜色,然后将这些信息用于识别形状和图形等更复杂的实体。比如在人脸识别上,他们学会从眼睛和嘴巴开始识别最终到整个面孔。当他们看一个人的形象时,他们大脑认出了两只眼睛,一只鼻子和一只嘴巴,当认出所有这些存在于脸上的实体,并且觉得“这看起来像一个人”。
斯蒂文首先给他的女儿悠悠看了以下图片,看她是否能自己学会认识图中的人(金·卡戴珊)。

斯蒂文接下来用几张图来考她:

悠悠
图中有两只眼睛一个鼻子一张嘴巴,图中的物体是个人。
斯蒂文
正确!

悠悠
图中有两只眼睛一个鼻子一张嘴巴,图中的物体是个人。
斯蒂文
错误!嘴巴长到眼睛上还是个人吗?

悠悠
图中有一大块都是黑色的,图中的物体好像是头发。
斯蒂文
错误!这只是把第一张图颠倒一下,怎么就变成头发了?
斯蒂文很失望,觉得她第二、三张都应该答对,但是他对悠悠要求太高了,要知道现在深度学习里流行的卷积神经网络 (convolutional neural network, CNN) 给出的答案也和悠悠一样,如下:

第一张 CNN 给出的答案是人,概率为 0.88,正确;第二张 CNN 给出的答案也是人,概率为 0.90 ,开玩笑在?第三张 CNN 给出的答案是黑发,概率为 0.79 ,呵呵,和悠悠一样天真。
CNN 弄错的两张图也是因为它的两个缺陷:
CNN 对物体之间的空间关系 (spatial relationship) 的识别能力不强,比如卡戴珊的嘴巴和眼睛换位置了还被识别成人?
CNN 对物体旋转之后的识别能力不强 (微微旋转还可以),比如卡戴珊倒过来就被识别成头发了?
Convolutional neural networks are doomed. -- Hinton
大神 Hinton 如此说道“卷积神经网络要完蛋了”,因此他最近也提出了一个 Capsule 的东西,直译成胶囊。但是这个翻译丢失了很多重要的东西,个人认为叫做向量神经元 (vector neuron) 甚至张量神经元 (tensor neuron) 更贴切。正式介绍 Capsule 的这篇文章在 2017 年 11 月 7 日才出来,论文名字叫《Dynamic Routing Between Capsules》,有兴趣的同学跟我走一遭吧。
目录
第一章 - 前戏王
1.1 物体姿态
1.2 不变性和同变性
1.3 全连接层
1.4 卷积神经网络
第二章 - 理论皇
2.1 胶囊定义
2.2 神经元类比
2.3 工作原理
2.4 动态路由
2.5 网络结构
第三章 - 实践狼
3.1 帆船房子
3.2 代码解析
总结和下帖预告
1、前戏王
1.1
物体姿态
为了正确的分类和识别物体,保持物体部分之间的分层姿态 (hierarchical pose) 关系是很重要的。姿态主要包括平移 (translation)、旋转 (rotation) 和放缩 (scale) 三种形式。
在拍摄人物时,我们调动照相机的角度从 3D 的人生成 2D 的照片。照出来的人物照角度多种多样,但人是个整体 (脸和身体对于人的相对位置不会变)。因此我们不想定义相对于相机的所有对象 (脸和身体),而将它们定义一个相对稳定的坐标系 (coordinate frame) 中,然后仅仅通过转动相机来照出不同角度的照片。
在创建这些图形时,我们首先会定义脸和身体相对于人的位置,更进一层,我们会定义眼睛和嘴巴对于相对于脸的位置,但不是相对于人的位置。因为之前已经有了脸相对于人的位置,现在又有了眼睛相对于脸的位置,那么也有了眼睛相对于人的位置。本质上,你将有层次的创建一个完整的人,而所需要的数学工具就是姿态矩阵 (pose matrix),这个矩阵定义所有对象相对于照相机的视点 (viewpoint),并且还表示了部件与整体之间的关系。
In order to correctly do classification and object recognition, it is important to preserve hierarchical pose relationships between object parts. -- Hinton
Hinton 认为,为了正确地进行分类和对象识别,重要的是保持对象部分之间的分层姿态关系。后面讲到的 Capsule 就符合这个重要直觉,它结合了对象之间的相对关系,并以姿态矩阵来表示。
首先我们看看 2 维平面中姿态矩阵是如何平移、旋转和放缩物体:
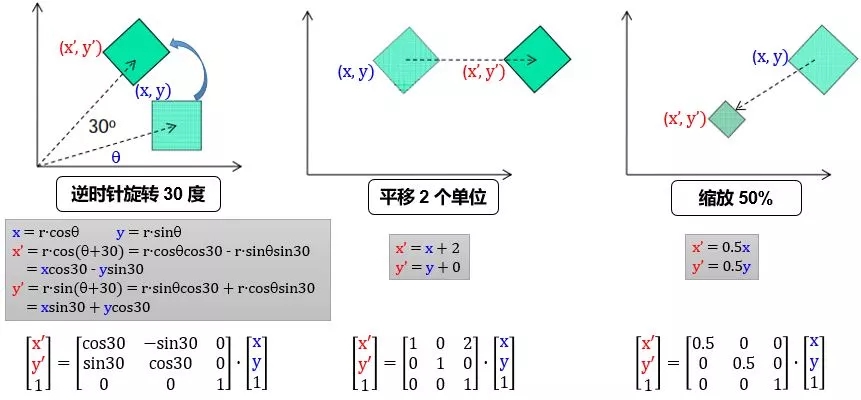
用 R, T, S 定义旋转、平移和缩放矩阵,那么将 (x, y) 先逆时针转 30 度,再向右平移 2 个单位,最后缩放 50% 到 (x", y") 可以由下列矩阵连乘得到

在 2 维平面中,我们加了 1 个维度 z,是为了方便完成平移操作。写出 2 维平面姿态矩阵 M 的一般形式,并延伸并类比到 3 维空间的姿态矩阵,表示如下:

下面看个具体例子:
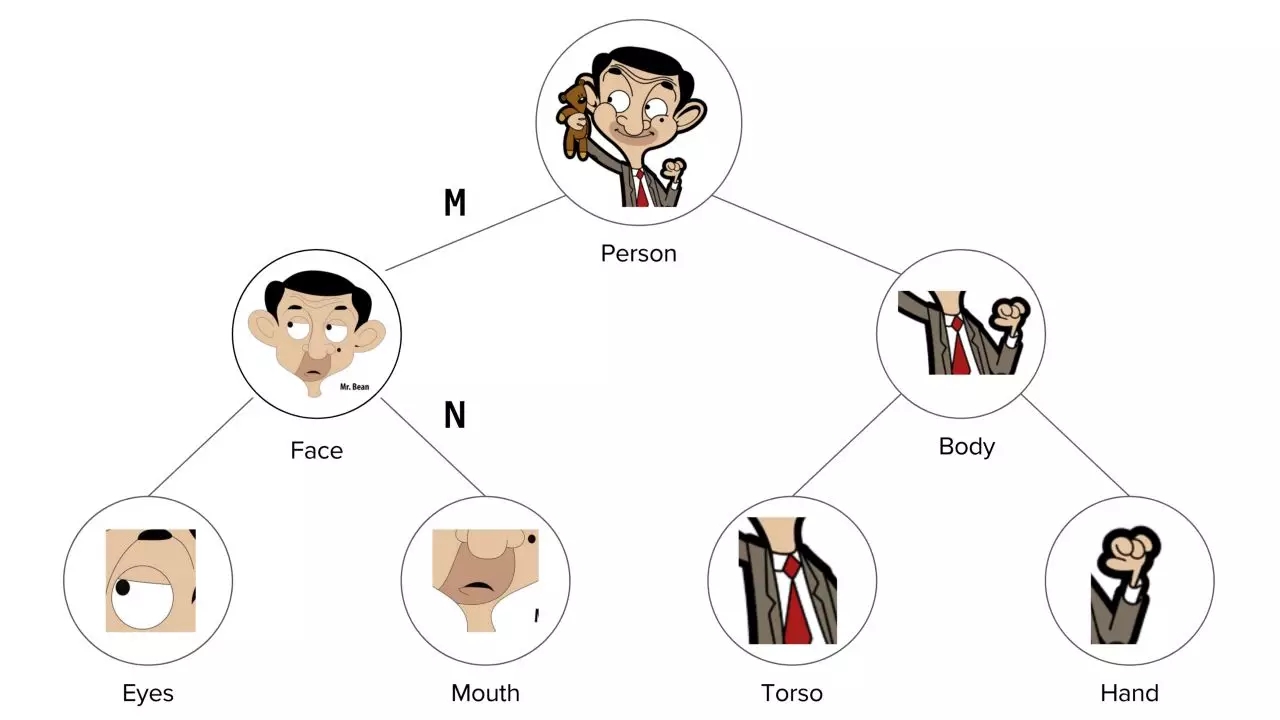
整体是由它的各个部分组成的,如上图:
人 (整体) 是由脸和身体组成
脸 (整体) 是由眼睛和嘴巴组成
身体 (整体) 是由躯干和手组成
每个部分通过一个姿态矩阵与其主体相关联。如果 M 是脸对人姿态矩阵,N 是嘴巴对脸姿态矩阵,那么嘴巴对人的姿态矩阵为 N" = MN。
现在我们有一个照相机,并且我们知道人对相机的帧的姿态矩阵是 P,可以通过连乘姿态矩阵来提取人的每个部分的所有基本属性,比如:
脸对相机的帧的姿态矩阵由 M" = PM 给出
嘴对相机的帧的姿态矩阵由 N" = M"N = PMN 给出

姿态矩阵 P 表示我们可以从相机看对象的不同视点。一张脸上所有特征都是一样的,所有不同的是你看脸的角度。所有其他对象 (比如身体、嘴巴和手) 的所有视点都可以由 P 得到。
现在告诉你左眼的位置,你可以想象脸的位置了吧。同理,你以为可以从嘴的位置估计脸的位置。如果由左眼和嘴的位置推出脸的位置相符,数学上表示为 Ev·E = Mv·M,其中
Ev 是眼睛的位置向量
E 是眼睛对脸的姿态矩阵
Mv 是嘴巴的位置向量
M 是嘴巴对脸的姿态矩阵

还记得引言中正常的卡戴珊的图像 (左图) 吗?从嘴和左眼推出脸的位置是相似的,因此得出结论它们属于同一个脸。

但是对于非正常的卡戴珊的图像 (下左图)
从嘴位置推出脸在图像上角 (下右图)
从左眼位置推出脸在图像底部 (下右图)

从嘴和左眼的位置出发得到的结论似乎不相符 (disagreement),因此它们不应该被认为出现在同一张脸上。只有当嘴和左眼处在正确的位置,从它们出发得到的结论才会相符 (agreement)。在这种情况下,我们就会发现嘴巴应该在两只眼睛的下面的中间,只有这样放置的眼睛和嘴巴才是脸部的一部分,而不是仅仅靠一张嘴巴和眼睛来识别脸部。
1.2、不变性和共变性
广义上讲,不变性 (invariance) 是表示 (representation) 不随变换 (transformation) 变化;而同变性(equivariance) 是表示的变换等价于变换的表示。
从计算机视觉角度上讲,不变性指不随一些变换来识别一个物体,具体变换包括平移 (translation),旋转 (rotation),视角 (viewpoint),放缩 (scale) 等,如下图所示:

不变性通常在物体识别上是好事,因为不管雕像怎么平移、2D旋转、3D旋转和放缩,我们都可以识别出它是雕像。
如果我们的任务比物体识别稍微困难一点,比如我想知道雕像平移了多少个单位,旋转了多少度,放缩了百分之多少,那么不变性远远不够,这时需要的是同变性。
下图给出不变性和同变性的具体例子
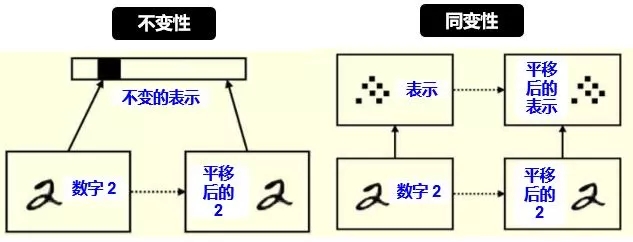
对平移和旋转的不变性,其实是丢弃了“坐标框架”,而同变性不会丢失这些信息,它只是对内容的一种变换。具体来讲:
左图:平移前的 2 和平移后的 2 的表示是一样的 (比如用 CNN 的池化),这样我们只能识别出 2 ,根本无法判断出 2 在图像中的位置。
右图:平移前的 2 和平移后的 2 的表示里含有位置这个信息 (比如用 Capsule),这样我们不但能识别出 2,还能判断出 2 在图像中的位置。
1.3、全连接层
在人工神经网络一贴讲的神经网络每层都是全连接的,也就是说上一层每一个神经元都连接到下一层每一个神经元,如下图所示:

除了偏置项,每层的每一个神经元都连着近邻层的所有神经元,以这种连接关系的层就叫做全连接层 (fully connected layer, FC layer),后文简称 FC 层。
如果一个神经网络每一层都是全连接的,那么它称作全连接神经网络 (fully connected neural network, FCNN),这种 FCNN 不能太深,要不然参数太多,训练速度太慢。在图像识别中,数据是高像素彩色照片,它的维度是 324×324×3,第一个 324 代表高,第二个 324 代表宽,最后的 3 代表 RGB 三个颜色维度,乘起来已经有 314928 个元素了,如果隐藏层有 1024 个神经元,那么总共有 314928×1024 = 3 亿多个参数 (假设忽略偏置项)。这还是一层,如果弄个十多层,那么训练这么多参数显然不现实,因此在图像识别中用的是卷积神经网络,它有稀疏连接 (sparse connection) 和参数共享 (parameter sharing) 等特性,会大大减少需要训练的参数。
1.4、卷积神经网络
卷积神经网络 (convolutional neural network,CNN) 的一个例子如下图。
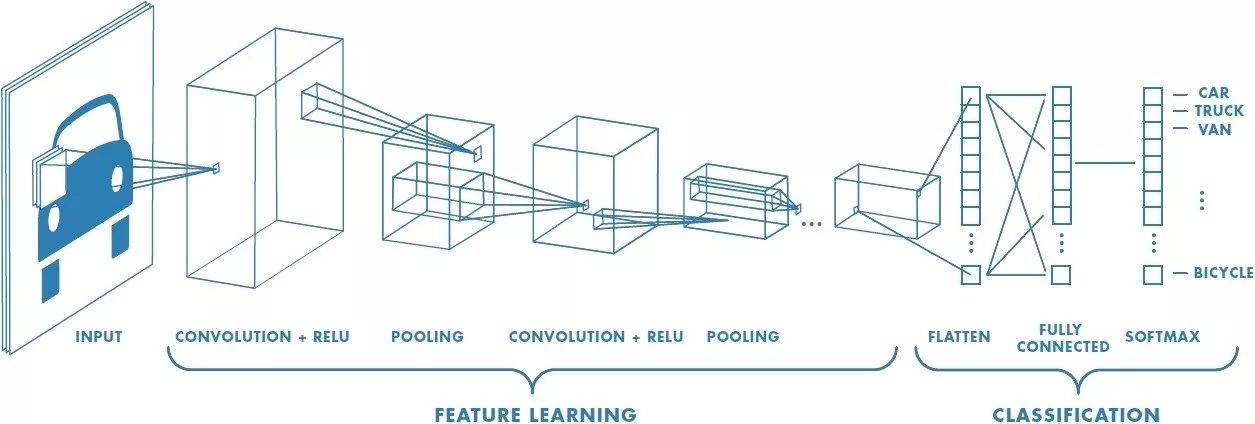
想象给了这张车的图片,在黑天里你看不到是辆车,你只能用手电筒一点一点扫过,把每次扫过看到的东西投影到下一层,以此类推。比如第一层你看到一些横线竖线斜线,第二层组合成一些圆形方形,第三层组合成轮子车门车身,第四层组合成一辆车。这样就能用个手电筒在黑天里辨别出照片里有辆车了。
上面的例子虽然不严谨,但是听起来很直观,接下来给出 CNN 里面的一些定义。
滤波器 (filter):在输入数据的宽度和高度上滑动,与输入数据进行卷积,就像上例中的手电筒
卷积 (convolution):在这里的定义就是把所有“滤波器的像素”乘以“滤波器扫过图片的像素”再加总
步长 (stride):遍历图像时滤波器的步长,默认值为 1,既滤波器每次移动一个像素
填充 (padding):有时候会将输入数据用 0 在边缘进行填充,可以控制输出数据的尺寸 (最常用的是保持输出数据的尺寸与输入数据一致)
千言万语不如两幅动图 (蓝色是输入图片的像素,绿色是滤波器扫过图片之后的卷积值):

第一幅动图将一个 5x5 的图像馈送到 3x3 的滤波器。其步长为 2 (滤波器每2格滑动),没用填充 (最外层没有虚线格),结果产生一个2x2 的图像。
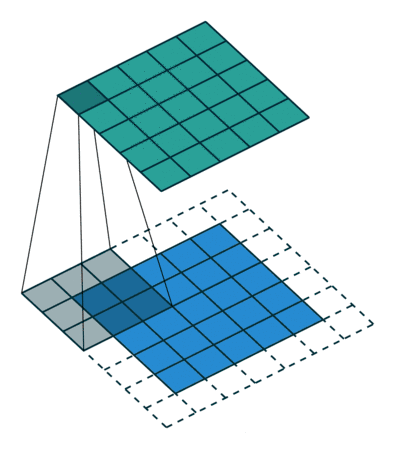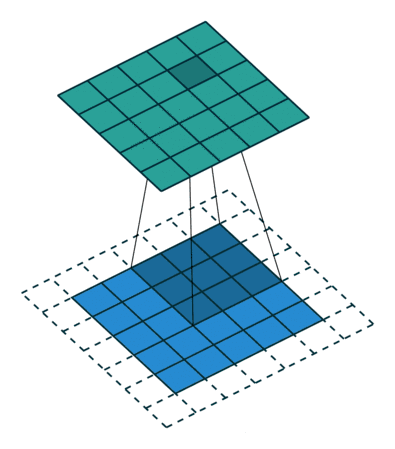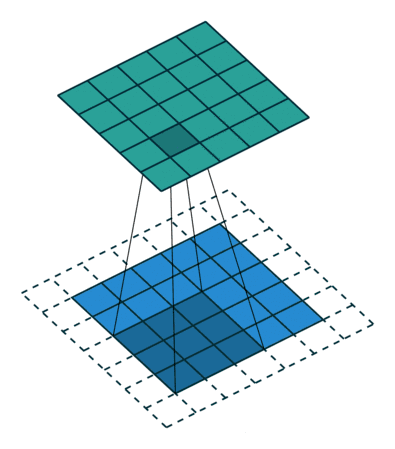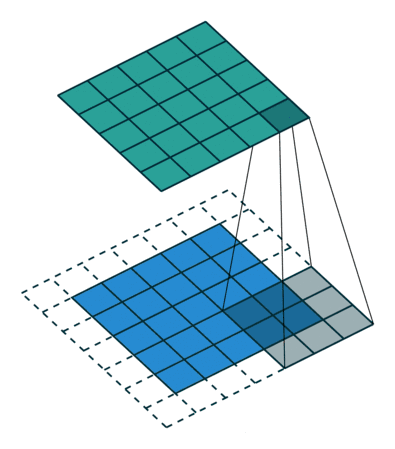
第二幅动图也将一个 5x5 的图像馈送到 3x3 的滤波器。其步长为 1 (滤波器每1格滑动),用了 1 层填充(最外层只有一格虚线格),结果产生一个 5x5 的图像 (加填充可使得输出和输入图像大小不变)。
如果用 nI 代表输入图像的大小,f 代表滤波器的大小,s 代表步长,p 代表填充层数,nO 代表输入图像的大小,那么有 (公式很简单就不推导了,大家可以试试上面两个例子)
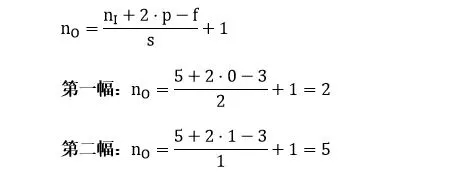
把具体数字带进来,大家再捋一遍上面的卷积、滤波器、步长和填充的概念:
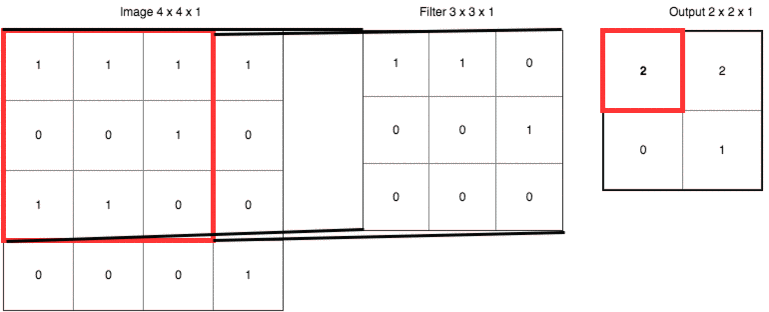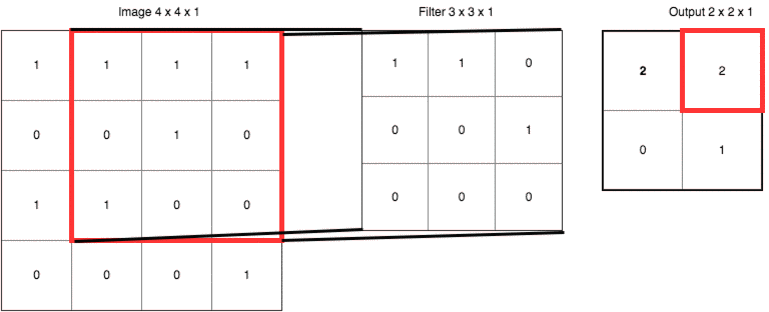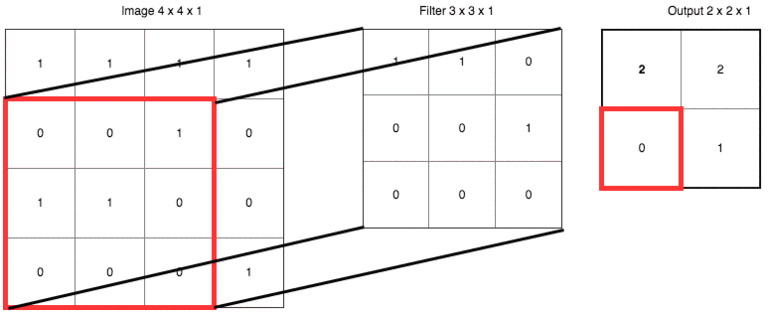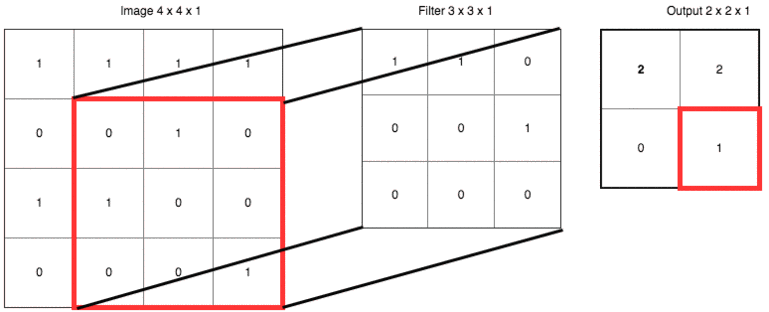
输出右下角的 1 是这样卷积来的:
0x1 + 1x1 + 0x0
+ 1x0 + 0x0 + 0x1
+ 0x0 + 0x0 + 1x0 = 1
除了上面定义之外,CNN 还有个很重要的概念叫做池化 (pooling)。它的作用是逐渐降低数据体的空间尺寸,这样的话能减少网络中参数的数量,使得计算资源消耗变少,也能有效的控制过拟合。通常池化使用 max 操作,比如使用尺寸 2x2 的滤波器,以步长为 2 对输入数据进行降采样,从 2x2 个数字中取较大值。字不如图,上图大家慢慢理会:
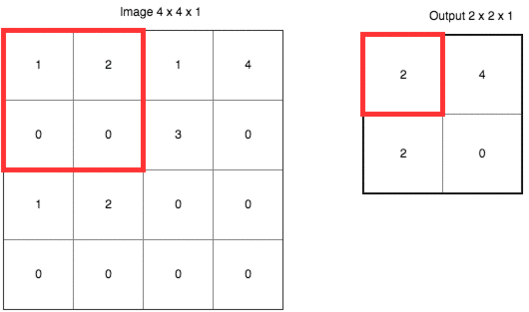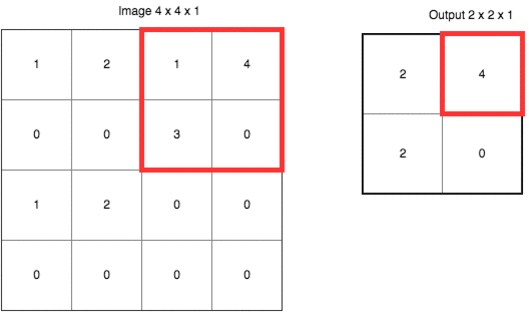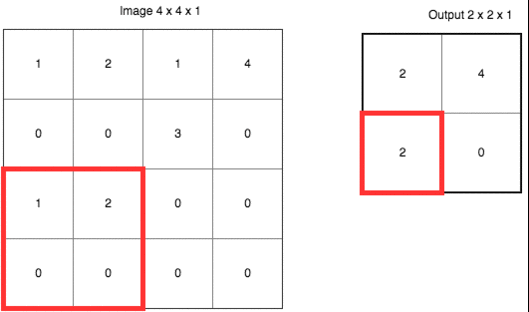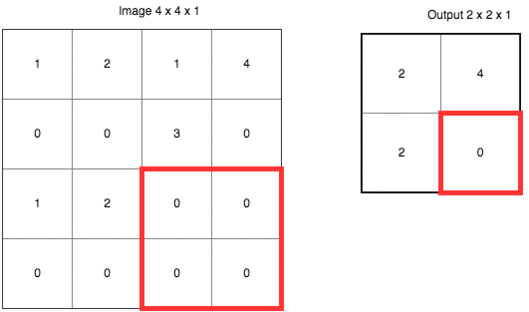
虽然池化这项技术在 CNN 上用的非常好,但是 Hinton 有话要说
The pooling operation used in convolutional neuralnetworks is a big mistake and the fact that it works so well is a disaster. -- Hinton
Hinton 认为池化在 CNN 的好效果是个大错误甚至灾难。因为池化会导致重要的信息丢失,如果它是两层之间的信使,它告诉第二层的是“我们看到左上角有一个较大值 2,右上角有一个较大值 4”,但不知道这个 2 和 4 是从第一层哪里来的。在引言的例子中,我们知道“两只眼睛一个鼻子一张嘴巴”并不代表“一张脸”,要确认是张脸,我们还需要知道这些器官之间的相互位置,比如眼睛要在鼻子上方,鼻子要在嘴巴上方,那么才可能是张脸。
2、理论皇
2.1、胶囊定义
胶囊 (Capsule) 是一个包含多个神经元的载体,每个神经元表示了图像中出现的特定实体的各种属性。这些属性可以包括许多不同类型的实例化参数 (instantiation parameter),例如姿态 (位置、大小、方向),变形,速度,色相,纹理等。胶囊里一个非常特殊的属性是图像中某个类别的实例的存在。它的输出数值大小就是实体存在的概率。
数学上常说的向量是一个有方向和长度的概念,把胶囊类比于数学向量,它也有所谓的“长度”和“方向”。假设一个胶囊代表卡戴珊的眼睛,戏称“卡戴珊眼睛胶囊”,那么其
长度代表眼睛在图像某个位置存在的概率
方向代表眼睛的一些参数,比如位置,转角,清晰度等等
两者类比图如下:

现在大家看胶囊的概念可能还是一头雾水,我确保你越看到后面思路越清晰,尤其要看小节 3.1。
2.2、神经元类比
为了用词严谨和类比方便,我们将 Capsule 称作向量神经元 (vector neuron, VN),而普通的人工神经元叫做标量神经元 (Scalar neuron, SN),下表总结了 VN 和 SN 之间的差异:

上表中 VN 里的操作不懂不要紧,接下来会一一详述,本节只是想从高层面上区分 VN 和 SN 的区别,因此大家比较熟悉 SN,从对 SN 的性质理解再慢慢过渡到对 VN 的理解。
回想一下人工神经网络一贴,SN 从其他神经元接收输入标量,然后乘以标量权重再求和,然后将这个总和传递给某个非线性激活函数 (比如 sigmoid, tanh, Relu),生出一个输出标量。该标量将作为下一层的输入变量。实质上,SN 可以用以下三个步骤来描述:
将输入标量 x 乘上权重 w
对加权的输入标量求和成标量 a
用非线性函数将标量 a 转化成标量 h
VN 的步骤在 SN 的三个步骤前加一步:
将输入向量 u 用矩阵 W 加工成新的输入向量 U
将输入向量 U 乘上权重 c
对加权的输入向量求和成向量 s
用非线性函数将向量 s 转化成向量 v
VN 和 SN 的过程总结如下图所示:

下一节来仔细研究 VN 的四步工作原理。
2.3、工作原理
为了使问题具体化,假设:
上一层的 VN 代表眼睛 (u1), 鼻子 (u2) 和嘴巴 (u3),称为低层特征
下一层第 j 个的 VN 代表脸,称为高层特征。注意下一层可能还有很多别的高层特征,脸是最直观的一个
第一步:矩阵转化
公式

根据小节 1.1 介绍的姿态矩阵可知
Uj|1 是根据眼睛位置来检测脸的位置
Uj|2 是根据鼻子位置来检测脸的位置
Uj|3 是根据嘴巴位置来检测脸的位置
现在,直觉应该是这样的:如果这三个低层特征 (眼睛,鼻子和嘴) 的预测指向相同的脸的位置和状态,那么出现在那个地方的必定是一张脸。如下图所示:

上左图预测出脸,因为红蓝黄绿圈非常吻合;而上右图没有没有预测出脸,因为红蓝黄绿圈相差甚远。
第二步:输入加权
公式

乍一看,这个步骤和标量神经元 SN 的加权形式有点类似。在 SN 的情况下,这些权重是通过反向传播 (backward propagation) 确定的,但是在 VN 的情况下,这些权重是使用动态路由 (dynamic routing) 确定的,具体算法见小节 2.4。本节只从高层面来解释动态路由,如下图:
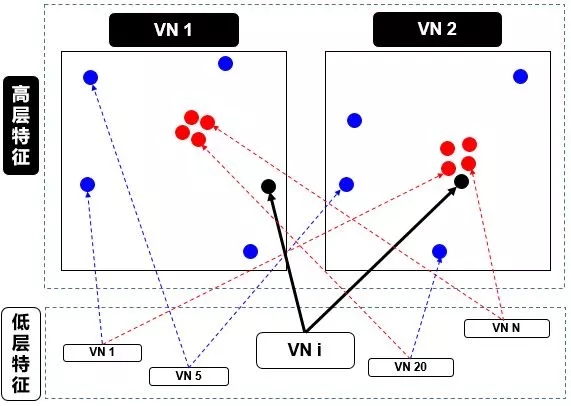
在上图中,我们有一个较低级别 VNi 需要“决定”它将发送输出给哪个更高级别 VN1 和 VN2。它通过调整权重 ci1 和 ci2 来做出决定。
现在,高级别 VN1 和 VN2 已经接收到来自其他低级别 VN 的许多输入向量,所有这些输入都以红点和蓝点表示。
红点聚集在一起,意味着低级别 VN 的预测彼此接近
蓝点聚集在一起,意味着低级别 VN 的预测相差很远
那么,低别级 VNi 应该输出到高级别 VN1 还是 VN2?这个问题的答案就是动态路由的本质。由上图看出
VNi 的输出远离高级别 VN1 中的“正确”预测的红色簇
VNi 的输出靠近高级别 VN2 中的“正确”预测的红色簇
而动态路由会根据以上结果产生一种机制,来自动调整其权重,即调高 VN2 相对的权重 ci2,而调低 VN1 相对的权重 ci1。
第三步:加权求和
公式
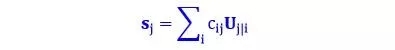
这一步类似于普通的神经元的加权求和步骤,除了总和是向量而不是标量。加权求和的真正含义就是计算出第二步里面讲的红色簇心 (cluster centroid)。
第四步:非线性激活
公式

这个公式的确是 VN 的一个创新,采用向量的新型非线性激活函数,又叫 squash 函数,姑且翻译成“压缩”函数。这个函数主要功能是使得 vj 的长度不超过 1,而且保持 vj 和 sj 同方向。
公式第一项压扁函数
如果 sj 很长,第一项约等于 1
如果 sj 很短,第一项约等于 0
公式第二项单位化向量 sj,因此第二项长度为 1
这样一来,输出向量 vj 的长度是在 0 和 1 之间的一个数,因此该长度可以解释为 VN 具有给定特征的概率。
2.4、动态路由
在小节 2.3 的第二步已经讲过,低级别 VNi 需要决定如何将其输出向量发送到高级别 VNj,它是通过改变权重 cij 而实现的。首先来看看 cij 的性质:
每个权重是一个非负值
对于每个低级别 VNi,所有权重 cij 的总和等于 1
对于每个低级别 VNi,权重的个数等于高级别 VN 的数量
权重由迭代动态路由 (iterative dynamic routing) 算法确定
前两个性质说明 c 符合概率概念。回想一下小节 2.1,VN 的长度被解释为它的存在概率。VN 的方向是其特征的参数化状态。因此,对于每个低级别 VNi,其权重 cij 定义了属于每个高级别 VNj 的输出的概率分布。
一言以蔽之,低级别 VN 会将其输出发送到“同意”该输出的某个高级别 VN。这是动态路由算法的本质。很绕口是吧?分析完 Hinton 论文中的动态路由算法就懂了,见截图:

算法字面解释如下:
第 1 行:这个过程用到的所有输入 - l 层的输出 Uj|i,路由迭代次数 r
第 2 行:定义 bij 是 l 层 VNi 应该连接 l+1 层 VNj 的可能性,初始值为 0
第 3 行:执行第 4-7 行 r 次
第 4 行:对 l 层的 VNi,将 bij 用 softmax 转化成概率 cij
第 5 行:对 l+1 层的 VNj,加权求和 sj
第 6 行:对 l+1 层的 VNj,压缩 sj 得到 vj
第 7 行:根据 Uj|i 和 vj 的关系来更新 bij
算法逻辑解释如下:
第 1 行无需说明,要指出的是迭代次数为 3 次,Hinton 在他论文里这样说道
第 2 行初始化所有 b 为零,这是合理的。因为从第 4 行可看出,只有这样 c 才是均匀分布的,暗指“l 层 VN 到底要传送输出到 l+1 层哪个 VN 是最不确定的”
第 4 行的 softmax 函数产出是非负数而且总和为 1,致使 c 是一组概率变量
第 5 行的 sj 就是小节 2.3 第二步里面讲的红色簇心,可以认为是低层所有 VN 的“共识”输出
第 6 行的 squash 确保向量 sj 的方向不变,但长度不超过 1,因为长度代表 VN 具有给定特征的概率
第 7 行是动态路由的精华,用 Uj|i 和 vj 的点积 (dot product) 更新 bij,其中前者是 l 层 VNi 对 l+1 层 VNj 的“个人”预测,而后者是所有 l 层 VN 对 l+1 层 VNj 的“共识”预测:
当两者相似,点积就大,bij 就变大,低层 VNi 连接高层 VNj 的可能性就变大
当两者相异,点积就小,bij 就变小,低层 VNi 连接高层 VNj 的可能性就变小
下面两幅图帮助进一步理解第 7 行的含义,第一幅讲的是点积,论文中用点积来度量两个向量的相似性,当然还有很多别的度量方式。
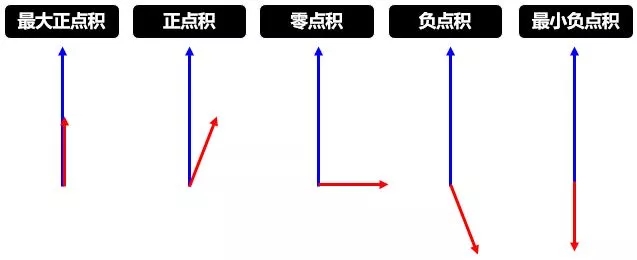
第二幅讲的是更新权重,此消彼长。
2.5、网络结构
本章的前四节已经讲明 Capsule 的工作原理和动态路由的逻辑。本节以 MNIST 数据集为例,来阐明向量神经网络 (capsule network, CapsNet) 的结构和工作原理。
MNIST 全称为 Modified National Institute of Standards and Technology,其中训练集由来自 250 个不同人手写的数字构成,其中 50% 是高中学生,50% 来自人口普查局的工作人员,总共 60000 个数字;而测试集也是同样比例的手写数字数据,总共 10000 个数字。每幅图像为一个 28x28 像素的单元,下图给出 MNIST 里面 0-9 的一些示例。

CapsNet 的输入输出和 CNN 是一样的:
输入都是 28x28 的二维矩阵
输出都是 10x1 的概率向量
但 CapsNet 和业界较先进的 CNN 相比,是一个非常浅的网络,中间只有两个卷积 (Conv) 层 (见小节1.4) 和一个全连接 (FC) 层 (见小节1.3),如下图所示:

图像输入到低级特征 (Conv1)
这一步就是一个常规的卷积操作,用了 256 个 stride 为 1 的 9x9 的 filter,得到一个 20x20x256 的输出。按照原文的意思,这一步主要作用就是对图像像素做一次局部特征检测。让我们 Conv1 层的维度是如何得到的。

但为什么不一开始就用 Capsule 呢?因为 Capsule 是用来表征某个物体的“实例”,因此它更适合于表征高级的实例。如果直接用 Capsule 吸取图片的低级特征内容,不是很理想,而 CNN 却擅长抽取低级特征,因此一开始用 CNN 是合理的。
低级特征到 Primary Capsule (Conv2)
Conv2 层才是开始含有 Capsule。如果按照普通 CNN 里面的做法,用了 32 个 stride 为 2 的 9x9x256 的 filter,也只能得到 6x6x32 的输出,算法如下:

但是从上图和 Hinton 的论文发现,Conv2 层的维度是 6x6x8x32。这个 8 怎么来的?它又代表着什么含义?个人理解是用 32 个 stride 为 2 的 9x9x256 的filter做了 8 次卷积操作,而且
在 CNN 中,维度为 6x6x1x32 的层里有 6x6x32 元素,每个元素是一个标量
在 Capsule 中,维度为 6x6x8x32 的层里有 6x6x32 元素,每个元素是一个 1x8的向量,既 capsule
Conv2 层的输出在论文中称为 Primary Capsule,简称 PrimaryCaps,主要储存低级别特征的向量。
Primary Capsule 到 Digit Capsule (FC)
下一层就是存储高级别特征的向量,在本例中就是数字,FC 层的输出在论文中称为 Digit Capsule,简称 DigitCaps。PrimaryCaps 和 DigitCaps 是全连接的,但不是像传统神经网络标量和标量相连,而是向量与向量相连。
PrimaryCaps 里面有 6x6x32 元素,每个元素是一个 1x8 的向量,而 DigitCaps 有 10 个元素 (因为有 10 个数字),每个元素是一个 1x16 的向量。为了让 1x8 向量与 1x16 向量全连接,需要 6x6x32 个 8x16 的矩阵 (姿态矩阵还记得吗)。
现在 PrimaryCaps 有 6x6x32 = 1152 个 VN,而 DigitCaps 有 10 个 VN,那么 I= 1,2, …, 1152, j = 0,1, …, 9。再用小节 2.4 讲的动态路由算法迭代 3 次计算 cij 并输出 10 个 vj。
Digit Capsule 到最终输出
根据 Capsule 定义,它的长度表示其表征的内容出现的概率,所以做分类时取输出向量的 L2 范数 (也就是长度) 即可。需要注意的是,最后 Capsule 输出的概率总和并不等于 1,也就是 Capsule 有同时识别多个物体的能力。
损失函数
由于 Capsule 允许多个分类同时存在,所以不能直接用传统的交叉熵 (cross-entropy) 损失,一种替代方案是用间隔损失 (margin loss)
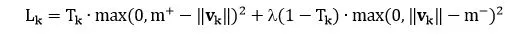
其中
k 是分类
Tk 是分类的指示函数 (k 类存在为 1,不存在为 0)
m+ 为上界,惩罚假阳性 (false positive) ,即预测 k 类存在但真实不存在,识别出来但错了
m- 为下界,惩罚假阴性 (false negative) ,即预测 k 类不存在但真实存在,没识别出来
λ 是比例系数,调整两者比重
总的损失是各个样例损失之和。论文中 m+ = 0.9, m- = 0.1, λ = 0.5,用大白话说就是
如果 k 类存在,||vk|| 不会小于 0.9
如果 k 类不存在,||vk|| 不会大于 0.1
惩罚假阳性的重要性大概是惩罚假阴性的重要性的 2 倍
重构表示
鲁棒性强的模型一定有重构的能力。如果模型能够重构,证明它至少有了一个好的表示,并且从重构结果中可以看出模型存在的问题。
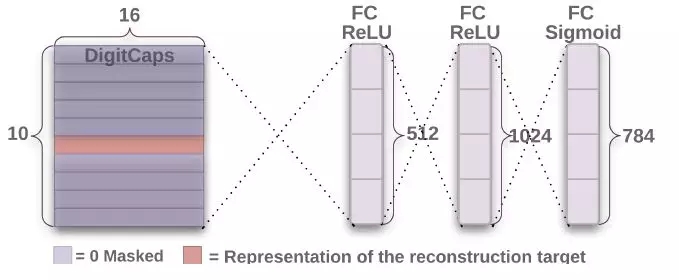
重构的时候,我们多带带取出 (上图橘色) 需要重构的向量,扔到后面的 3 层全连接网络中重构。注意最终输出的维度是 784 = 28×28,正好是最初图像输入的维度。
重构损失 (reconstruction loss) 就是把最终输出和最初输入的 784 个单元上的像素值相减并平方求和。总体损失 (total loss) 就是
总体损失 = 间隔损失 + α·重构损失
其中 α = 0.005,间隔损失还是占主导地位。
3、实践狼
3.1、帆船房子
本节用一个具体的“三角形长方形组成帆船房子”的例子来直观解释第 2 章的理论知识和重要概念,假设“低层 Capsule”里面有三角形和长方形,而“高层 Capsule”里面有帆船和房子。为了解释方便,定义:
三角形 VN:低层 Capsule 的三角形
长方形 VN:低层 Capsule 的长方形
帆船 VN:高层 Capsule 的帆船
房子 VN:高层 Capsule 的房子
正向作图和反向作图

如上图所示,计算机作图 (computer graphics) ,通常认为是正向作图,是根据各个物体的参数,比如中心横坐标 x,中心纵坐标 y 和旋转角度,在屏幕中打出 (rendering) 帆船的图像。而反向作图 (inverse graphics) 是根据屏幕中帆船的图像,反推出各个物体的参数。
想知道上图三角形的 -65 度和长方形的 16 度怎么来的,见下图解释。

向量神经元做的事就是反向作图。
向量神经元性质
假设蓝箭头代表三角形,黑箭头代表长方形:
蓝箭头的长度表示三角形出现的概率大小
黑箭头的长度表示长方形出现的概率大小
蓝箭头的方向表示三角形的姿态参数 (这里指朝向)
黑箭头的方向表示长方形的姿态参数 (这里指朝向)
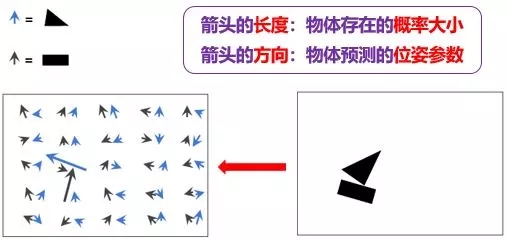
由上图左边明显看出
有一个蓝箭头和一个黑箭头非常大,说明在上图右边各自相应位置上存在的三角形和长方形的可能性非常大
其他地方的所有蓝箭头和黑箭头非常小,说明在上图右边那些位置上存在的三角形和长方形的可能性非常小
根据蓝箭头的方向,我们大概知道三角形逆时针转了 65 度
根据黑箭头的方向,我们大概知道长方形顺时针转了 16 度
同变性
CNN 的池化只能带来“不变性 (invariance)”,只能识别下面两图中都有帆船,但我们不想只追求识别率,我们想要的更多,比如 VN 带来的“同变性 (equivariance)”,不但能识别两图中有帆船,还能看出它们的倾斜度不同。

从上图看出,当帆船旋转了一些角度,它包含的三角形和长方形也旋转了一些角度,而对应的蓝箭头和黑箭头也旋转了一些角度。三角形和长方形是低层物体,帆船是高层物体,物体与物体之间是有层次 (hierarchy) 的。当高层物体转动时,它包含的所有低层物体也随之转动。
物体层次
三角形和长方形可以组成帆船,也可以组成房子。

如果把帆船和房子当成一个整体的话 (忽略其组成成分三角形和长方形),那么它们也有自己的 x-y 坐标和角度,如图所示,帆船沿顺时针方向旋转了 16 度,房子沿逆时针方向旋转了 5 度。
现在问题是,如果我们识别出图片上有三角形和长方形,那么它们组合的是房子还是帆船?
预测物体
下图勾画出由“低层 VN 代表的三角形和长方形”来预测“高层 VN 代表的房子和帆船”的来龙去脉。

如果根据长方形的姿态开始预测,则房子和帆船的姿态如左图所示。注意房子和帆船里的长方形朝向和位置完全相同。
如果根据三角形的姿态开始预测,则房子和帆船的姿态如右图所示。注意房子和帆船里的三角形朝向和位置完全相同。
浅谈路由
路由 (routing) 就是通过互联网络把信息从源地址传输到目的地址的活动,而这里路由指的是通过神经网络把信息从低层 VN 传输到高层 VN 的活动。
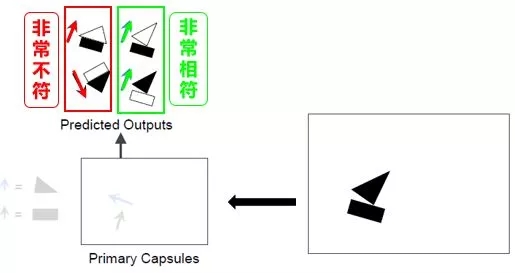
“三角形和长方形的 VN”路由出来的“帆船 VN”看起来非常相似,而它们路由出来的“房子 VN”看来一点也不像。因此我们有信心的认为图像里存在就是一艘帆船而不是一栋房子。
动态路由
动态路由 (dynamic routing) 是找到每一个“低层 VN”的输出最有可能贡献给哪个“高层 VN”。具体到我们的实例,就是找到“三角形或长方形”最有可能组成“房子或帆船”。
用 i 代表低层 VN 中长方形或三角形的索引 (本例中 i = 1, 2),用 j 代表高层 VN 中房子或帆船的索引 (本例中 j = 1, 2),定义
bij = 低层 VNi 连接高层 VNj 的可能性,初始值为 0
cij = 低层 VNi 连接高层 VNj 的概率,总和为 1
bi = 低层 VNi 连接所有高层 VNj 的可能性,初始值为 0
ci = 低层 VNi 连接所有高层 VNj 的概率
Uj|i = 由低层 VNi 预测的高层 VNj
cij 是 bij 做 softmax 之后的结果,因此初始值 0.5 (j 层只有 2 个 VN)。
为了达到以上目的,动态路由在每个回合都干了“归一、预测、加总、压缩和更新”这五件事,然后重复若干回合:
对长方形 (i=1) 和三角形 (i=2)
归一:
计算概率 (c11, c12) = 归一(b11, b12)
计算概率 (c21, c22) = 归一(b21, b22)
预测:
从长方形到房子 U1|1 和小船 U2|1
从三角形到房子 U1|2 和小船 U2|2
加总:
房子的综合预测 s1 = c11U1|1 + c21U1|2
帆船的综合预测 s2 = c12U2|1 + c22U2|2
压缩:
单位化房子的综合预测 v1 = 压缩(s1)
单位化帆船的综合预测 v2 = 压缩(s2)
更新:
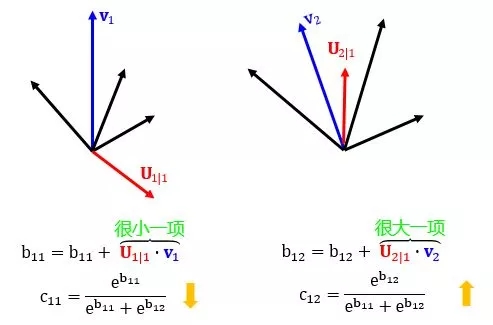
b11 = b11 + 相似度(U1|1, v1)
b12 = b12 + 相似度(U2|1, v2)
b21 = b21 + 相似度(U1|2, v1)
b22 = b22 + 相似度(U2|2, v2)
其中归一函数是 softmax 函数,压缩函数是 squash 函数,相似度函数是 dot product。下面接着用实例来解释上述步骤。
初始化概率和参数:
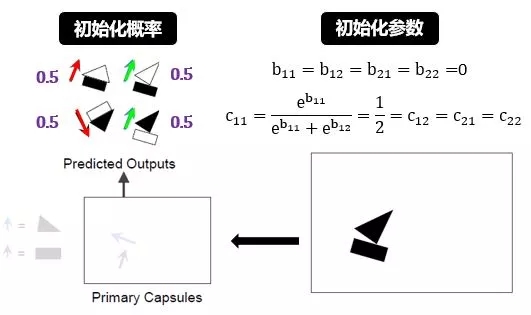
初始化所有 b 为零,根据 softmax 函数计算出所有 c 都是 0.5。该初始化是符合直觉的,一开始“三角形或长方形到底是帆船还是房子的一部分”这样一个判断是最不确定的,而 50% 的概率对应着这种最不确定情景。
预测-加总-压缩:
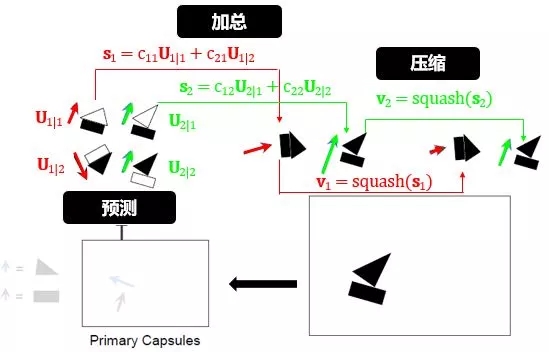
预测就是用姿态矩阵做了转化 (见小节 1.1),分别由长方形和三角形的位置预测了房子/帆船的位置:

加总就是分别将房子/帆船的预测位置求个加权总和,可以理解成房子/帆船的平均位置:

压缩就是单位化位置向量:

更新参数:
参数 b 就是从三角形/长方形推出房子/帆船的可能性,如图:
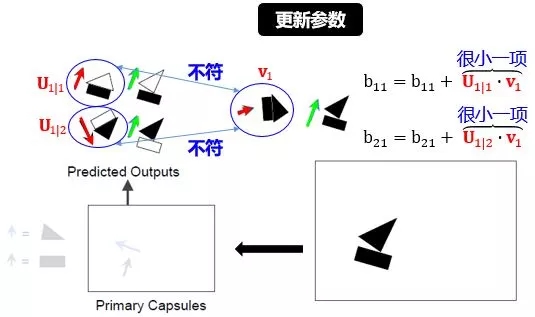

上图已解释的很清楚,核心思想就是
当两个物体相似时,它们的点积比较大,从而增大可能性
当两个物体相异时,它们的点积比较小,从而减小可能性

最后用 softmax 更新概率 cij

重复以上预测-加总-压缩的步骤,循环 r 次结束。

最后用以下规则来判断到底从低层 VN 路由到高层 VN:
如果 b11 > b12 则 c11 > c12,那么三角形路由到房子概率大,反之路由到帆船概率大
如果 b21 > b22 则 c21 > c22,那么长方形路由到房子概率大,反之路由到帆船概率大
3.2、代码解析
基本引入包和设置
# Import useful packages
import numpy as np
import tensorflow as tf
%matplotlib inline
import matplotlib.pyplot as plt
# Reset the default graph for rerun notebook
tf.reset_default_graph()
# Reset the random seed for reproducibility
np.random.seed(42)
tf.set_random_seed(42)
读取 MNIST 数据
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/")
n_samples = 5
plt.figure(figsize=(n_samples * 2, 3))
for index in range(n_samples):
plt.subplot(1, n_samples, index + 1)
sample_image = mnist.train.images[index].reshape(28, 28)
plt.imshow(sample_image, cmap="binary")
plt.axis("off")
plt.show()
从 tensorflow 数据库里引进 MNSIT 数据,选出 5 个样本打印出来。
特征 X 和标签 y
X = tf.placeholder(shape=[None, 28, 28, 1], dtype=tf.float32, name="X")
y = tf.placeholder(shape=[None], dtype=tf.int64, name="y")
定义特征 X 和标签 y,placeholder 是占位符的意思,用于创建占位,当需要时再将真正的数据传入进去,即利用 feed_dict 的字典结构给 placeholder 变量“喂数据”。Placeholder 有三个参数:
数据维数
数据类型
数据命名
X 有四维,分别是图片个数,宽度像素,高度像素,色彩维度。
图片个数在定义占位符时不知道,只有在喂数据时才知道,因此用 None
图片都包含 28x28 像素,每个像素用 float32 类型表示
图片是黑白的,没有 RGB,因此维度是 1
y 只有一维,就是图片个数。其标签值就是用 0 到 9 的 int64 类型表示。
卷积层
conv1_params = {
"filters": 256,
"kernel_size": 9,
"strides": 1,
"padding": "valid",
"activation": tf.nn.relu,
}
conv1 = tf.layers.conv2d(X, name="conv1", **conv1_params)
首先在字典 conv1_params 里定义卷积层的参数,滤波器个数 256、滤波器大小 9、步长 1,填充 valid 指的没有填充、激活函数用的 relu。然后用 tensorflow 里的函数 conv2d 建立 conv1,其中 ** 代表传递一个字典类型的变量。最终 conv1 的 shape 是 [?, 20, 20, 256],其中 ? 代表之后才确定的图片个数。
Primary Capsules
caps1_n_maps = 32
caps1_n_dims = 8
conv2_params = {
"filters": caps1_n_maps * caps1_n_dims,
"kernel_size": 9,
"strides": 2,
"padding": "valid",
"activation": tf.nn.relu
}
conv2 = tf.layers.conv2d(conv1, name="conv2", **conv2_params)
建立 conv2 和 conv1 是一样的,conv2 的 shape 是 [?, 6, 6, 256]。这里 256 其实是 32 和 8 的乘积,由小节 2.5 可知,该层实际用了 32 个滤波器滤了 8 遍。
更需要注意的是,该层 (PrimaryCaps) 每个 Capsule (1x8 向量) 和下层 (DigitCaps) 每个 Capsule (1x16 向量) 全连接,那么较好生成一个变量含有 1152 个 Capsule,因此将 conv2 的 shape 转成 [?, 1152, 8] (总元素和 6x6x256 一样多),该变量记做 caps1_raw, 见下图代码。
caps1_n_caps = caps1_n_maps * 6 * 6
caps1_raw = tf.reshape(conv2, [-1, caps1_n_caps, caps1_n_dims],
name="caps1_raw")
Reshape 函数里面 -1 指的是某个维度大小,使得变换维度后的变量和变换前的变量的总元素个数不变。比如 A 原来的 shape 是 [3, 2, 3],如果 B 用
reshape(A, [-1,9]),则 B.shape = [2,9]
reshape(A, [9,-1]),则 B.shape = [9,2]
reshape(A, [2,-1,3]),则 B.shape = [2,3,3]
定义压缩函数 squash
def squash(s, axis=-1, epsilon=1e-7, name=None):
with tf.name_scope(name, default_name="squash"):
squared_norm = tf.reduce_sum(tf.square(s), axis=axis,
keep_dims=True)
safe_norm = tf.sqrt(squared_norm + epsilon)
squash_factor = squared_norm / (1. + squared_norm)
unit_vector = s / safe_norm
return squash_factor * unit_vector

这里有个技巧,在分母 ||s|| 里面加入小量10-7,防止分母为零。最后用 squash 函数将 caps1_raw 单位化得到 cap1_output。它的 shape 也是 [?, 1152, 8]。
caps1_output = squash(caps1_raw, name="caps1_output")
Digit Capsules
根据小节 2.3,1152 个 PrimaryCaps 的变量 (1x8) 需要乘以姿态矩阵 (8x16) 得到 10 个 DigitCaps 的变量 (1x16)。下面设计的高维矩阵相乘是一种较高效的做法。

其中
第一个数组的 shape 是 [1152, 10, 16, 8]
第二个数组的 shape 是 [1152, 10, 8, 1]
第三个数组的 shape 是 [1152, 10, 16, 1]
上面数组已经是四维了,但别忘了还有图片个数这一维,需要用 tensorflow 里面的 tile 函数来增加一维。见下面三块代码:
数组 W
caps2_n_caps = 10
caps2_n_dims = 16
init_sigma = 0.01
W_init = tf.random_normal(
shape=(1, caps1_n_caps, caps2_n_caps, caps2_n_dims, caps1_n_dims),
stddev=init_sigma, dtype=tf.float32, name="W_init")
W = tf.Variable(W_init, name="W")
batch_size = tf.shape(X)[0]
W_tiled = tf.tile(W, [batch_size, 1, 1, 1, 1], name="W_tiled")
首先定义一个四维随机变量 W_init,当 W 的初始值,它的 shape 是 [1152, 10, 16, 8],batch_size 是一批图片的个数。tile 函数实际就是将 W 复制了batch_size个,储存在 W_tiled,它的 shape 是 [?, 1152, 10,16, 8],如下图:

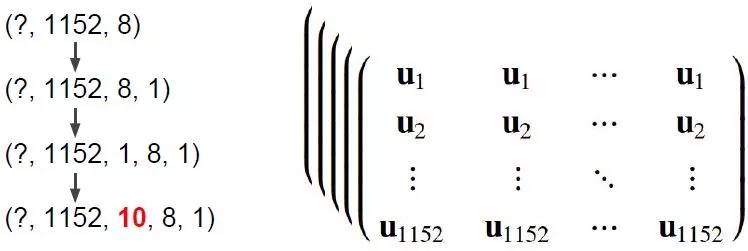
数组 u
caps1_output_expanded = tf.expand_dims(caps1_output, -1,
name="caps1_output_expanded")
caps1_output_tile = tf.expand_dims(caps1_output_expanded, 2,
name="caps1_output_tile")
caps1_output_tiled = tf.tile(caps1_output_tile, [1, 1, caps2_n_caps, 1, 1],
name="caps1_output_tiled")
这一步是最让人困惑的。
首先看最终想要的结果的 shape 是 [?, 1152, 10, 8, 1],而 caps1_output 的 shape 是 [?, 1152, 8]
需要在最后的 axis 上扩张一维,用 expand_dims 函数和参数 -1,得到 caps1_output_expanded 的 shape 是 [?, 1152, 8, 1]
需要在第二个 axis 上扩张一维,用 expand_dims 函数和参数 2,得到 caps1_output_tile 的 shape 是 [?, 1152, 1, 8, 1]
用 tile 函数将第三个 axis 上复制 10 个,得到 caps1_output_tiled 的 shape 是 [?, 1152, 10, 8, 1]
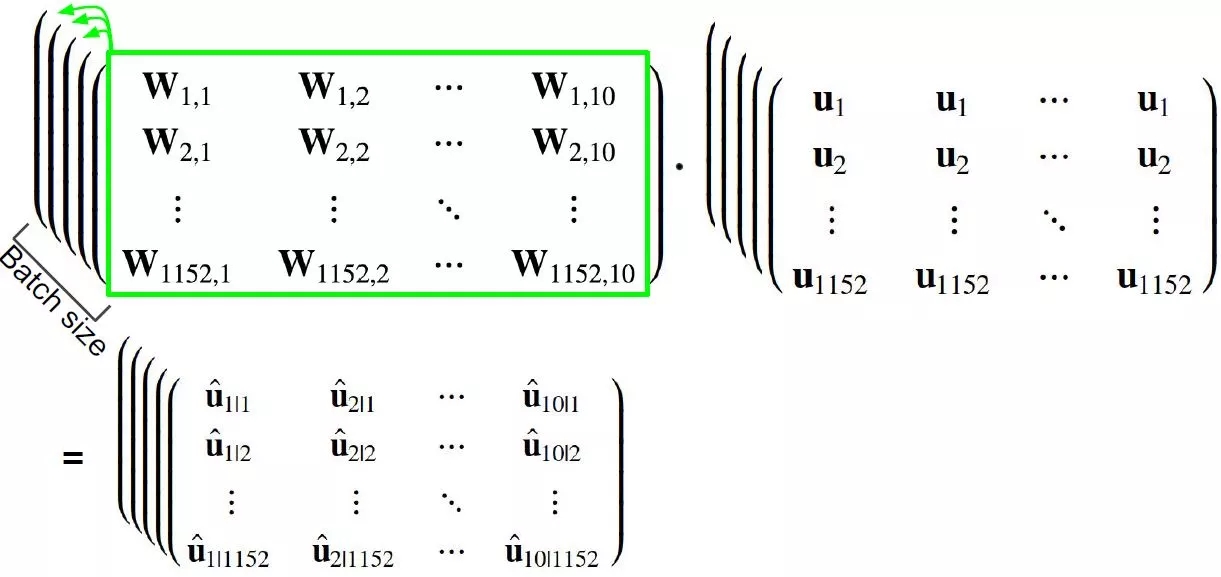
数组 u_hat
caps2_predicted = tf.matmul(W_tiled, caps1_output_tiled,
name="caps2_predicted")
函数 matmul 是将高维数组中每个矩阵元素相乘
用 shape 为 [?, 1152, 10, 16, 8] 的 W_tiled
乘以 shape 为 [?, 1152, 10, 8, 1] 的 caps1_output_tiled
等于 shape 为 [?, 1152, 10, 16, 1] 的 caps2_predicted
如下图所示:
动态路由
第一轮初始化 b
b = tf.zeros([batch_size, caps1_n_caps, caps2_n_caps, 1, 1],
dtype=np.float32, name="raw_weights")
b 的 shape 为 [?, 1152, 10, 1, 1]。
第一轮初始化 c
c = tf.nn.softmax(raw_weights, dim=2, name="routing_weights")
c 的 shape 为 [?, 1152, 10, 1, 1],而且在第二个 axis 上做归一化,原因就是每一个 caps1 到所有 caps2 的概率总和为一。
第一轮计算 s 和 v
weighted_predictions = tf.multiply(c, caps2_predicted,
name="weighted_predictions")
s = tf.reduce_sum(weighted_predictions, axis=1,
keep_dims=True, name="weighted_sum")
v = squash(s, axis=-2, name="caps2_output_round_1")
weighted_predictions 的 shape 为 [?, 1152, 10, 16, 1],而 s 和 v 的 shape 为 [?, 1, 10, 16, 1],因为在第一个 axis 上用 reduce_sum 函数求和再用 squash 函数压缩。
第二轮迭代
v_tiled = tf.tile(v, [1, caps1_n_caps, 1, 1, 1],
name="caps2_output_round_1_tiled")
agreement = tf.matmul(caps2_predicted, v_tiled,
transpose_a=True, name="agreement")
b = tf.add(b, agreement, name="raw_weights_round_2")
c = tf.nn.softmax(b, dim=2, name="routing_weights_round_2")
weighted_predictions = tf.multiply(c, caps2_predicted,
name="weighted_predictions_round_2")
s = tf.reduce_sum(weighted_predictions, axis=1,
keep_dims=True, name="weighted_sum_round_2")
v = squash(s, axis=-2, name="caps2_output_round_2")
第三轮迭代
v_tiled = tf.tile(v, [1, caps1_n_caps, 1, 1, 1],
name="caps2_output_round_2_tiled")
agreement = tf.matmul(caps2_predicted, v_tiled,
transpose_a=True, name="agreement")
b = tf.add(b, agreement, name="raw_weights_round_3")
c = tf.nn.softmax(b, dim=2, name="routing_weights_round_3")
weighted_predictions = tf.multiply(c, caps2_predicted,
name="weighted_predictions_round_3")
s = tf.reduce_sum(weighted_predictions, axis=1,
keep_dims=True, name="weighted_sum_round_3")
v = squash(s, axis=-2, name="caps2_output_round_3")
上面这种写出每一轮迭代的方法有点低效,一种替代方法可以用 for 语句,但是它是静态循环 (static loop), 在 tensorflow 里面每定义一次操作都会增大内部的流程图。这里三次迭代没问题,如果很多的建议用 tf.while_loop() 函数,这个是动态循环 (dynamic loop)。除了减小流程图大小以外,动态循环还能减少 GPU RAM 的使用。
间隔损失
m_plus = 0.9
m_minus = 0.1
lambda_ = 0.5
T = tf.one_hot(y, depth=caps2_n_caps, name="T")
v_norm = tf.norm(v, axis=-2, keep_dims=True, name="caps2_output_norm")
FP_raw = tf.square(tf.maximum(0., m_plus - v_norm), name="FP_raw")
FP = tf.reshape(FP_raw, shape=(-1, 10), name="FP")
FN_raw = tf.square(tf.maximum(0., v_norm - m_minus), name="FN_raw")
FN = tf.reshape(FN_raw, shape=(-1, 10), name="FN")
L = tf.add(T * FP, lambda_ * (1.0 - T) * FN, name="L")
margin_loss = tf.reduce_mean(tf.reduce_sum(L, axis=1), name="margin_loss")
实现小节 2.5 里面的公式,用 one_hot 函数将数字转换成 0-1 的哑变量矩阵。
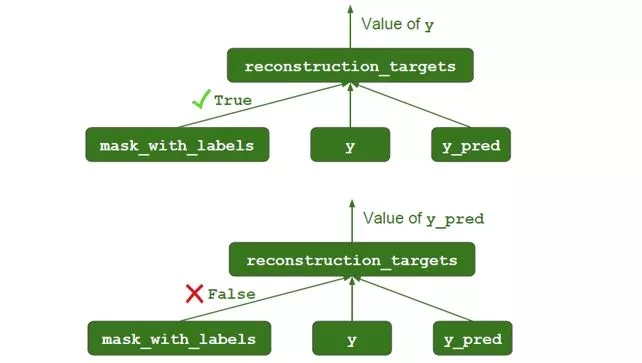
Mask 机制
mask_with_labels = tf.placeholder_with_default(False, shape=(),
name="mask_with_labels")
reconstruction_targets = tf.cond(mask_with_labels, # condition
lambda: y, # if True
lambda: y_pred, # if False
name="reconstruction_targets")
reconstruction_mask = tf.one_hot(reconstruction_targets,
depth=caps2_n_caps,
name="reconstruction_mask")
reconstruction_mask_reshaped = tf.reshape(
reconstruction_mask, [-1, 1, caps2_n_caps, 1, 1],
name="reconstruction_mask_reshaped")
caps2_output_masked = tf.multiply(
v, reconstruction_mask_reshaped,
name="caps2_output_masked")
在重构中,并不是每一个数字的输出都传送到解码器的,只有目标数字的输出才需要传送出去,因此需要做一个 one_hot 转换。此外
在训练中,需要传出的是 y
在测试中,需要传出的是 y_pred
解码器
n_hidden1 = 512
n_hidden2 = 1024
n_output = 28 * 28
decoder_input = tf.reshape(caps2_output_masked,
[-1, caps2_n_caps * caps2_n_dims],
name="decoder_input")
with tf.name_scope("decoder"):
hidden1 = tf.layers.dense(decoder_input, n_hidden1,
activation=tf.nn.relu,
name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2,
activation=tf.nn.relu,
name="hidden2")
decoder_output = tf.layers.dense(hidden2, n_output,
activation=tf.nn.sigmoid,
name="decoder_output")
解码器由个 3 全连接层组成,每层大小分别为 512,1024 和 784,用layers.dense 函数来构建。
重构损失
X_flat = tf.reshape(X, [-1, n_output], name="X_flat")
squared_difference = tf.square(X_flat - decoder_output,
name="squared_difference")
reconstruction_loss = tf.reduce_sum(squared_difference,
name="reconstruction_loss")
最终损失
alpha = 0.0005
loss = tf.add(margin_loss, alpha * reconstruction_loss, name="loss")
额外设置
# 全局初始化
init = tf.global_variables_initializer()
saver = tf.train.Saver()
# 计算精度
correct = tf.equal(y, y_pred, name="correct")
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
# 用 Adam 优化器
optimizer = tf.train.AdamOptimizer()
training_op = optimizer.minimize(loss, name="training_op")
小结
以上已经完成构建所有的网络结构,接下来训练和测试的步骤都非常标准化,就不再多言了。需要提醒的是,在训练时,mask_with_labels 设置成 True,y 被传出去用在重构损失函数里,如下图:
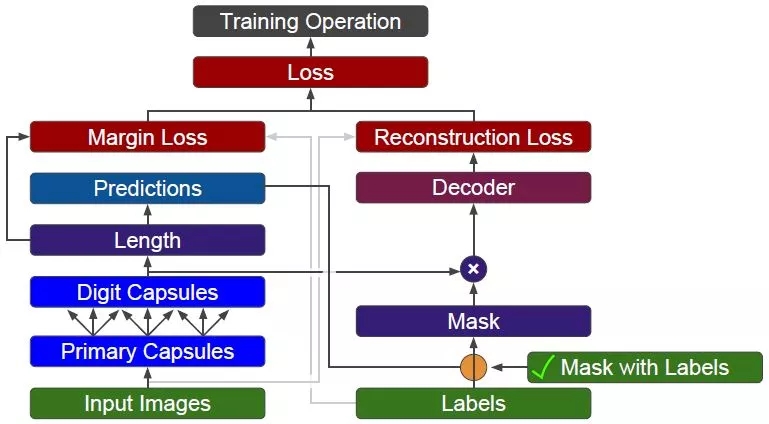
在测试时,mask_with_labels 设置成 False,y_pred 被传出去用在重构损失函数里,如下图:

4、总结
深度学习,本质就是一系列的张量变换 (tensor transformation)。Capsule 现在将神经元的输入和输出升级成二维向量,以后很容易会将其延伸为高维张量。
在识别数字上,人只需要看几十个最多几百个样例就能分辨数字。Capsule 只需要 CNN 需要的一小部分样例就能达到同等水平,而 CNN 通常需要上万的数据,从这点看 Capsule 的运作方式比 CNN 更接近人的大脑。此外Capsule还可以识别重叠数字。
不过 CapsNet 在 ImageNet 数据集上训练起来太耗时,而且目前这个路由算法过于简单 (Hinton 论文坑已挖好,等着大家来填)。最有趣的是从论文结果来看,引进重构比没引进重构的识别误差小很多,这到底是 Capsule 的功劳,还是单单重构的功劳?
本帖把 Capsule 的原理彻底弄清楚了,也提供了部分 tensorflow 代码,希望对大家了解这个前言课题有所帮助。Stay Tuned!
参考文献
Dynamic Routing Between Capsules. SaraSabour, Nicholas Frosst, Geoffery E.Hinton
Capsule Networks. Aurélien Géron
Implementing Capsule Networks with Tensorflow. Aurélien Géron
Uncovering the Intuition behind Capsule Networks and Inverse Graphics. Tanay Kothari
UnderstandingHinton’s Capsule Networks. Max Pechyonkin
Capsule NetworksAre Shaking up AI — Here’s How to Use Them. Nick Bourdakos
What is a CapsNet or Capsulte Network? Debarko De
知乎“浅析 Hinton 最近提出的 Capsule 计划”. SIY.Z
知乎“如何看待Hinton的论文Dynamic RoutingBetween Capsules”. 云梦局客
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4721.html
摘要:在底层的胶囊之后连接了层和层。胶囊效果的讨论在论文最后,作者们对胶囊的表现进行了讨论。他们认为,由于胶囊具有分别处理不同属性的能力,相比于可以提高对图像变换的健壮性,在图像分割中也会有出色的表现。 背景目前的神经网络中,每一层的神经元都做的是类似的事情,比如一个卷积层内的每个神经元都做的是一样的卷积操作。而Hinton坚信,不同的神经元完全可以关注不同的实体或者属性,比如在一开始就有不同的神...
摘要:链接是他们在数据集上达到了较先进的性能,并且在高度重叠的数字上表现出比卷积神经网络好得多的结果。在常规的卷积神经网络中,通常会有多个汇聚层,不幸的是,这些汇聚层的操作往往会丢失很多信息,比如目标对象的准确位置和姿态。 PPT由于笔者能力有限,本篇所有备注皆为专知内容组成员根据讲者视频和PPT内容自行补全,不代表讲者本人的立场与观点。胶囊网络Capsule Networks你好!我是Aurél...
摘要:而加快推动这一趋势的,正是卷积神经网络得以雄起的大功臣。卷积神经网络面临的挑战对的深深的质疑是有原因的。据此,也断言卷积神经网络注定是没有前途的神经胶囊的提出在批判不足的同时,已然备好了解决方案,这就是我们即将讨论的胶囊神经网络,简称。 本文作者 张玉宏2012年于电子科技大学获计算机专业博士学位,2009~2011年美国西北大学联合培养博士,现执教于河南工业大学,电子科技大学博士后。中国计...
摘要:等人最近关于胶囊网络的论文在机器学习领域造成相当震撼的影响。它提出了理论上能更好地替代卷积神经网络的方案,是当前计算机视觉领域的技术。而这就是这些胶囊网络运行方式的本质。为了简化,我们将假设一个两层的胶囊网络。产生的结果值将被称为。 Geoff Hinton等人最近关于胶囊网络(Capsule networks)的论文在机器学习领域造成相当震撼的影响。它提出了理论上能更好地替代卷积神经网络的...
摘要:本文从可视化的角度出发详解释了的原理的计算过程,非常有利于直观理解它的结构。具体来说,是那些水平方向的边缘。训练过程可以自动完成这一工作。更进一步地说,这意味着每个胶囊含有一个拥有个值的数组,而一般我们称之为向量。 CapsNet 将神经元的标量输出转换为向量输出提高了表征能力,我们不仅能用它表示图像是否有某个特征,同时还能表示这个特征的旋转和位置等物理特征。本文从可视化的角度出发详解释了 ...
摘要:胶囊网络是一种热门的新型神经网络架构,它可能会对深度学习特别是计算机视觉领域产生深远的影响。下几层胶囊也尝试检测对象及其姿态,但工作方式非常不同,即使用按协议路由算法。 胶囊网络(Capsule networks, CapsNets)是一种热门的新型神经网络架构,它可能会对深度学习特别是计算机视觉领域产生深远的影响。等一下,难道计算机视觉问题还没有被很好地解决吗?卷积神经网络(Convolu...

阅读 1295·2021-09-01 10:30
阅读 2204·2021-07-23 10:38
阅读 941·2019-08-29 15:06
阅读 3193·2019-08-29 13:53
阅读 3309·2019-08-26 11:54
阅读 1873·2019-08-26 11:38
阅读 2417·2019-08-26 10:29
阅读 3168·2019-08-23 18:15







