
摘要:何恺明和两位大神最近提出非局部操作为解决视频处理中时空域的长距离依赖打开了新的方向。何恺明等人提出新的非局部通用网络结构,超越。残差连接是何恺明在他的年较佳论文中提出的。
Facebook何恺明和RGB两位大神最近提出非局部操作non-local operations为解决视频处理中时空域的长距离依赖打开了新的方向。文章采用图像去噪中常用的非局部平均的思想处理局部特征与全图特征点的关系。这种非局部操作可以很方便的嵌入已有模型,在视频分类任务中取得的很好的结果,并在在静态图像识别的任务中超过了何恺明本人ICCV较佳论文的Mask R-CNN。何恺明等人提出新的非局部通用网络结构,超越CNN。
何恺明博士,2007年清华大学毕业之后开始在微软亚洲研究院(MSRA)实习,2011年香港中文大学博士毕业后正式加入MSRA,目前在Facebook AI Research (FAIR)实验室担任研究科学家。曾以第一作者身份拿过两次CVPR较佳论文奖(2009和2016),一次ICCV较佳论文。
Ross Girshick,在读博士的时候就因为dpm获得过pascal voc 的终身成就奖。同时也是RCNN,fast RCNN ,faster RCNN,YOLO一系列重要的目标检测算法的作者。现在同样就职于FAIR。
背景
文章主要受到NL-Means在图像去噪应用中的启发,在处理序列化的任务是考虑所有的特征点来进行加权计算,克服了CNN网络过于关注局部特征的缺点。
图像去噪是非常基础也是非常必要的研究,去噪常常在更高级的图像处理之前进行,是图像处理的基础。图像中的噪声常常用高斯噪声N(μ,σ^2)来近似表示。 一个有效的去除高斯噪声的方式是图像求平均,对N幅相同的图像求平均的结果将使得高斯噪声的方差降低到原来的N分之一,现在效果比较好的去噪算法都是基于这一思想来进行算法设计。
NL-Means的全称是:Non-Local Means,直译过来是非局部平均,在2005年由Baudes提出,该算法使用自然图像中普遍存在的冗余信息来去噪声。与常用的双线性滤波、中值滤波等利用图像局部信息来滤波不同的是,它利用了整幅图像来进行去噪,以图像块为单位在图像中寻找相似区域,再对这些区域求平均,能够比较好地去掉图像中存在的高斯噪声。
通常的CNN网络模拟人的认知过程,在网络的相邻两层之间使用局部连接来获取图像的局部特性,一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。网络部分连通的思想,也是受启发于生物学里面的视觉系统结构,底层的去捕捉轮廓信息,中层的组合轮廓信息,高层的组合全局信息,最终不同的全局信息最终被综合,但由于采样以及信息逐层传递损失了大量信息,所以传统cnn在全局信息捕捉上存在局限性。

图3是指在res3上一个非局部模块的行为的示例,其在Kinetics数据集上基于5-block的非局部模型训练得到的。这些例子来自于验证集视频。
而在处理视频等序列化数据时,传统cnn的这种局限性就显得尤为严重了。比如在记录一场网球比赛的视频中,每一帧都能很容易的检测到他的手握拍在哪,一个卷积核就能覆盖位置也就是手腕周围的区域。
但是为了识别挥拍这个动作,仅仅关注手腕周围的信息是不够的,我们需要了解到人的手腕跟他的胳膊、肩膀、膝盖以及脚发生了哪些一系列的相对位移才能判断出挥拍动作。这些信息是将网球区别于其他运动的重要信息,因为静止来看运动员都拿着拍子站在那而已。而这些重要的全局位移信息很难被关注局部的卷积核收集到。
非局部神经网络(Non-local Neural Networks)
非局部操作(Non-local operation)
为了处理这些全局动作信息,文章借鉴NL-Means中利用整幅图去噪的思想。前面讲到 NL-Means利用了整幅图像来进行去噪,以图像块为单位在图像中寻找相似区域,再对这些区域求平均,它的滤波过程可以用下面公式来表示:
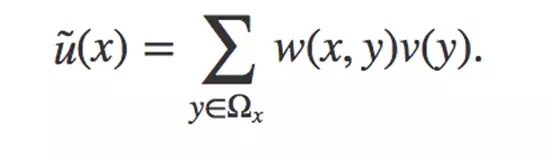
在这个公式中,w(x,y)是一个权重,表示在原始图像中,像素 x和像素 y 的相似度。这个权重要大于0,同时,权重的和为1。
类似的,该文章定义了一个用于处理当前动作点与全局所有信息关系的函数
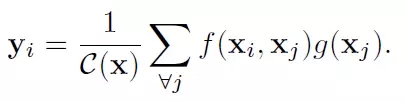
这里x是输入信号,也是和x尺寸一样的输出信号,i代表时间空间上的输出位置索引,j代表全图中所有可能位置的枚举索引。函数f(x_i, x_j)计算位置i和j的权重。函数g用来计算j位置输入信号的一个表示。文章中的Non-Local操作就是考虑了图像中的所有可能位置j。
文中还给出了具体的几种f(x_i,x_j)函数的实现形式
1. Gaussian
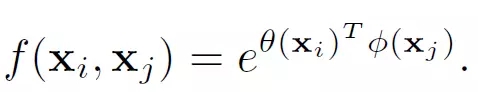
2. Embedded Gaussian
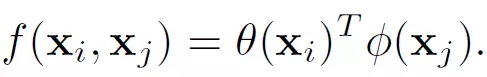
3. Dot product
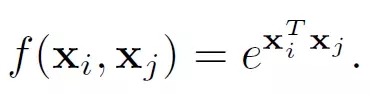
4. Concatenation
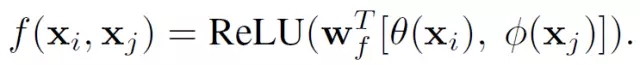
非局部模块(Non-local Block)
文章中还定义了Non-local Block,也就是把前面的这种Non-local操作封装起来作为一个模块可以很方便的用在现有的框架中。
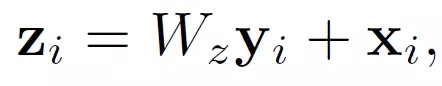
这里y_i就是公式(1)中的输出结果。“+x_i”表示残差连接。残差连接是何恺明在他的2016年CVPR较佳论文中提出的。这个残差连接使得我们可以将这个Non-local Block很方便的插入已有的预训练模型中,而不会破坏模型原有的操作。
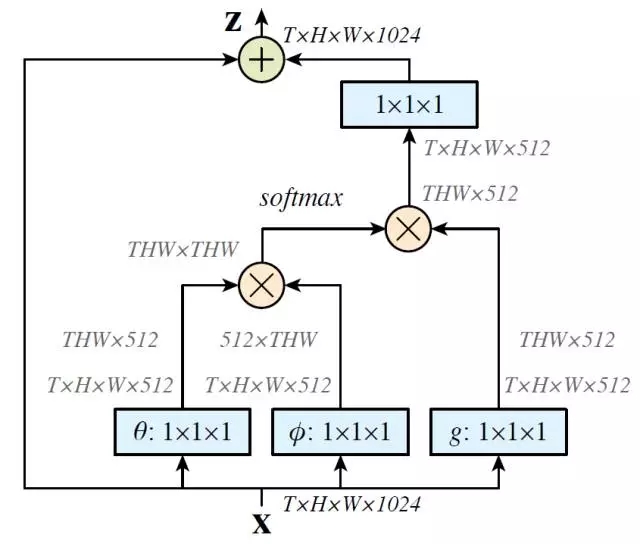
上图是一个Non-local Block的例子。特征图尺寸为T×H×W×1024 也就是有 1024 个通道。 f函数采用的是公式3中的Embedded Gaussian。蓝色框表示1×1×1 的卷积操作,这种结构为512通道的“瓶颈”(bottleneck)结构。
实验
视频分类
文章在Kinetics 和Charades两个视频数据集上进行实验,baseline选的是带残差结构的cnn网络。

表3是在Kinetics上的比较结果。标记"+"是指在测试集上的结果,其余没有标记的是在验证集的结果。我们包含了2017年包括Kinetics竞争冠军的结果,但是他们较好的结果利用了音频信号(标记为灰色),不是一个仅仅基于视觉的解决方法。
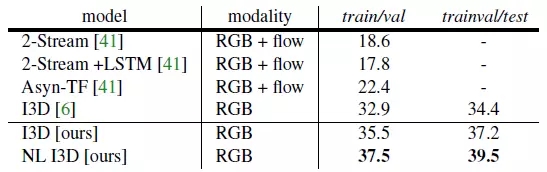
表4是在Charades数据集上的分类结果,数据集被划分成训练集/验证集,训练验证/测试集两种方式。我们的结果是基于ResNet-101, 我们提出的的NL I3D使用了5个non-local blocks.
COCO数据
文章还在静态图像数据识别进行实验。用在物体识别分割以及姿态识别任务上的Baseline是何恺明刚在ICCV上取得较佳论文的Mask R-CNN.
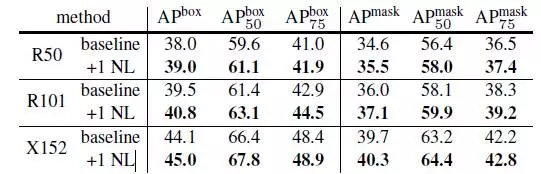
表5是在COCO物体检测和示例分割任务中增加一个non-local block到Mask R-CNN的结果。
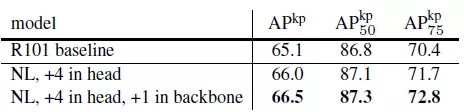
表6是在COCO关键点检测任务中增加non-local blocks到Mask R-CNN的结果。
在未来,我们也希望在未来网络结构设计中非局部层能成为一个不可或缺模块。
论文:Non-local Neural Networks
链接:https://arxiv.org/abs/1711.07971

(附上专知内容组翻译的摘要和引言,有错误和不完善的地方,请大家提建议和指正)
摘要
卷积和循环网络操作都是常用的处理局部领域的基础模块。在本文中,我们提出将非局部操作(non-local operations)作为捕获长距离依赖的通用模块。受计算机视觉中的经典非局部均值方法的启发,我们的非局部运算将位置处的响应计算为所有位置处的特征的加权和。这个构建模块可以应用到许多计算机视觉体系结构中。
在视频分类的任务上,即使没有用任何花里胡哨的技巧,我们的非局部模型也可以在Kinetics和Charades数据集上超过对手的效果。在静态图像识别中,我们的非局部模型在COCO比赛中的三个任务,对象检测/分割和姿态估计中都效果都有提升。代码将随后提供。
引言
在深层神经网络中,捕获长期依赖关系是至关重要的。对于连续的数据(例如演讲中语言),循环操作是时间域上长期依赖问题的主要解决方案。对于图像数据,长距离依赖关系是对大量的卷积操作形成的大的感受野进行建模的。
卷积操作或循环操作都是处理空间或者时间上的局部邻域的。这样,只有当这些操作被反复应用的时候,长距离依赖关系才能被捕获,信号才能通过数据不断地传播。重复的局部操作有一些限制:首先,计算效率很低;其次,增加优化难度;最后,这些挑战导致多跳依赖建模,例如,当消息需要在远距离之间来回传递时,是非常困难的。
本文中,我们提出将非局部操作作为一个高效的、简单的、通用的组件,并用深度神经网络捕捉长距离依赖关系。我们提出的非局部操作受启发于计算机视觉中经典非局部操作的一般含义。直观地说,非局部操作在一个位置的计算响应是输入特性图中所有位置的特征的加权总和(如图1)。一组位置可以在空间、时间或时空上,暗示我们的操作可以适用于图像、序列和视频问题。

图1是一个在视频分类应用中训练的网络包含的时空非局部操作示例。
非局部操作有以下优势:(a)与循环操作的反复性行为形成对比,非局部操作直接通过计算任意两个位置之间的相互作用来捕捉长距离依赖关系,而不需受两位置的位置距离约束。(b)正如我们在实验中展示的,非局部操作的效率高,而且在只有几层的情况下也能达到较好的结果。(c)最后,我们的非局部操作保持输入变量的大小,并且容易与其他操作进行结合(如卷积操作)。
我们将展示非局部操作在视频分类应用中的有效性。在视频中,远距离的相互作用发生在空间或时间中的长距离像素之间。一个非局部块是我们的基本单位,可以直接通过前馈方式捕捉这种时空依赖关系。在一些非局部块中,我们的网络结构被称为非局部神经网络,比2D或3D卷积网络(包括其变体)有更准确的视频分类效果。另外,非局部神经网络有比3D卷积网络有更低的计算开销。我们在Kinetics和Charades数据集上进行了详细的研究(分别进行了光流、多尺度测试)。我们的方法在所有数据集上都能获得比方法更好的结果。
为了证明非局部操作的通用性,我们进一步在COCO数据集上进行了目标检测/分割和姿势估计的实验。在MaskR-CNNbaseline的基础之上,我们的非局部块仅需要很小的额外计算开销,就可以提升在三个任务中的准确度。在视频和图像中的实验证明,非局部操作可以作为设计深度神经网络的一个通用的部件。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4694.html
摘要:大神何恺明受到了质疑。今天,上一位用户对何恺明的提出质疑,他认为何恺明年的原始残差网络的结果没有被复现,甚至何恺明本人也没有。我认为,的可复现性经受住了时间的考验。 大神何恺明受到了质疑。今天,Reddit 上一位用户对何恺明的ResNet提出质疑,他认为:何恺明 2015 年的原始残差网络的结果没有被复现,甚至何恺明本人也没有。网友称,他没有发现任何一篇论文复现了原始 ResNet 网络的...
摘要:为了探索多种训练方案,何恺明等人尝试了在不同的迭代周期降低学习率。实验中,何恺明等人还用预训练了同样的模型,再进行微调,成绩没有任何提升。何恺明在论文中用来形容这个结果。 何恺明,RBG,Piotr Dollár。三位从Mask R-CNN就开始合作的大神搭档,刚刚再次联手,一文终结了ImageNet预训练时代。他们所针对的是当前计算机视觉研究中的一种常规操作:管它什么任务,拿来ImageN...
摘要:目前目标检测领域的深度学习方法主要分为两类的目标检测算法的目标检测算法。原来多数的目标检测算法都是只采用深层特征做预测,低层的特征语义信息比较少,但是目标位置准确高层的特征语义信息比较丰富,但是目标位置比较粗略。 目前目标检测领域的深度学习方法主要分为两类:two stage的目标检测算法;one stage的目标检测算法。前者是先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本...
摘要:但是其仍然存在一些问题,而新提出的解决了式归一化对依赖的影响。上面三节分别介绍了的问题,以及的工作方式,本节将介绍的原因。作者基于此,提出了组归一化的方式,且效果表明,显著优于等。 前言Face book AI research(FAIR)吴育昕-何恺明联合推出重磅新作Group Normalization(GN),提出使用Group Normalization 替代深度学习里程碑式的工作B...
摘要:从标题上可以看出,这是一篇在实例分割问题中研究扩展分割物体类别数量的论文。试验结果表明,这个扩展可以改进基准和权重传递方法。 今年10月,何恺明的论文Mask R-CNN摘下ICCV 2017的较佳论文奖(Best Paper Award),如今,何恺明团队在Mask R-CNN的基础上更近一步,推出了(以下称Mask^X R-CNN)。这篇论文的第一作者是伯克利大学的在读博士生胡戎航(清华...

阅读 3653·2023-04-26 00:05
阅读 1007·2021-11-11 16:55
阅读 3646·2021-09-26 09:46
阅读 3577·2019-08-30 15:56
阅读 966·2019-08-30 15:55
阅读 2980·2019-08-30 15:53
阅读 2011·2019-08-29 17:11
阅读 862·2019-08-29 16:52






