
摘要:信息瓶颈理论由耶路撒冷希伯来大学的计算机与神经科学家等人提出。与我取得联系并分享了一篇已提交盲审的论文,论文作者对信息瓶颈理论的一些发现作了批判性分析。这是一个重要更新,指出了信息瓶颈理论的一些局限性。
「信息瓶颈」(Information Bottleneck)理论由耶路撒冷希伯来大学的计算机与神经科学家 Naftali Tishby 等人提出。该研究有望最终打开深度学习的黑箱,并解释人脑的工作原理(参见:揭开深度学习黑箱:希伯来大学计算机科学教授提出「信息瓶颈」)。Geoffrey Hinton 曾对此研究评论道:「信息瓶颈极其有趣,估计要再听 10000 遍才能真正理解它,当今能听到如此原创的想法非常难得,或许它就是解开谜题的那把钥匙。」
目前,一篇有关深度学习中信息瓶颈理论的论文《On the information bottleneck theory of deep learning》已提交 ICLR 2018 大会盲审,然而这篇论文的内容主要是指出信息瓶颈理论的局限。该论文已经引起了很多人的关注,有学者甚至在社交网络上评论道:这篇论文「戳穿了一个巨大的泡沫」。本文作者 Adrian Colyer 将对这一工作进行解读。
上周,我们研究了 Schwartz-Viz 和 Tishby 的深度学习论文《Opening the Black Box of Deep Neural Networks via Information》,其思想令人赞叹,从一种新视角展示了深度神经网络内部发生的一切。Sathiya Keerthi 与我取得联系并分享了一篇已提交 ICLR 2018 盲审的论文——《On the information bottleneck theory of deep learning》,论文作者对信息瓶颈理论的一些发现作了批判性分析。这是一个重要更新,指出了信息瓶颈理论的一些局限性。
在这篇论文中,作者首先从再现 Schwartz-Viz 和 Tishby 论文中的「信息平面动态」(information plane dynamics)开始,接着展开进一步实验:使用 ReLU 替代激活函数 tanh,观察有何影响;探索泛化与压缩之间的联系;研究训练期间随机性对压缩是否重要;以及研究在何种程度上与任务不相关的信息也被压缩。
简单来说,该论文发现 Schwartz-Viz 和 Tishby 论文中的结果无法很好地泛化到其他网络架构:训练期间的两个阶段依赖于激活函数的选择;无法证明压缩与泛化之间存在因果关系;当压缩确实发生时,它不一定依赖于来自随机梯度下降(SGD)的随机性。
我们的结果强调在应用信息理论分析深度学习系统时噪声假设的重要性,并且通过展示表征压缩与泛化性能存在分歧的实例来复杂化深度学习的信息瓶颈理论。
下面我们来更深入地理解
激活函数选择的影响
我们的分析起点是发现改变激活函数能显著地改变信息平面中的网络轨迹。
作者借助 Schwartz-Vis 和 Tishby 提供的代码首次再现了我们上周看到的结果(见下图 1A),接着改变网络以使用 ReLU——修正线性激活函数,最终获得的信息平面动态请见图 1B。

我们看到 tanh 激活函数的相移消失了!
输入的互信息在所有的 ReLu 层中单调递增,没有明显的压缩阶段。因此,非线性函数的选择实质上影响了信息平面的动态。
作者使用一个非常简单的三神经元网络进一步探讨了这一现象。标量高斯输入分布通过标量第一层权重 w1 馈送,并通过神经非线性函数 f(·) 传输以获取隐藏单元活动。
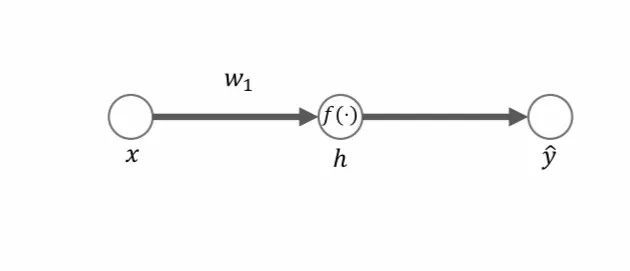
为了计算互信息,隐藏单元活动被离散化至 30 个统一的分箱(bin)中,以获得离散变量。
使用 tanh 非线性函数,互信息先增后降。使用 ReLU 非线性函数,互信息一直呈上升趋势。
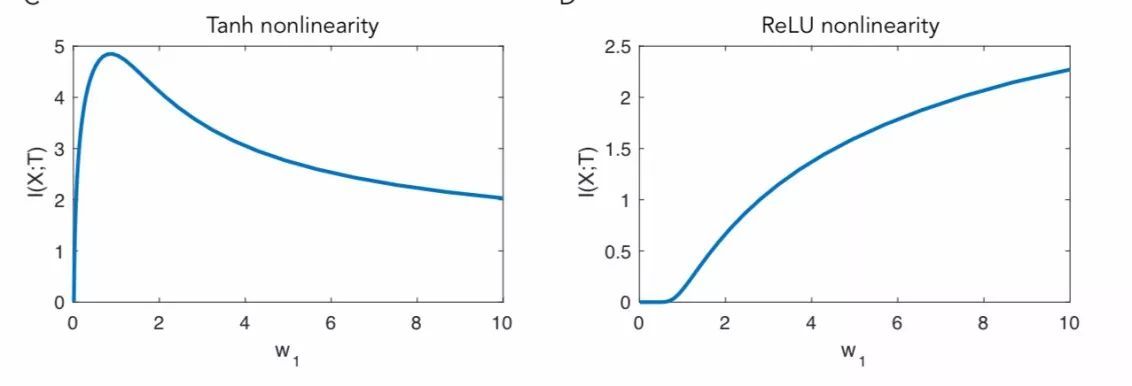
tanh 函数权重较大,饱和时会下降,以接近 1 比特的输入(即分散变量集中于 1 和 -1 周围的 bin)提供互信息。而使用 ReLU 函数,一半输入是负的,聚集在 0 周围的 bin,而另一半呈高斯分布,熵随权重的变化而单调递增。因此,tanh 的双面饱和特性是原始结果的关键。
……随着隐藏单元进入饱和态,由于用于计算互信息的分箱(binning)步骤,双饱和非线性(double-saturating nonlinearities)导致输入信息的压缩。我们注意到分箱可以看作是暗中向隐藏层活动中添加噪声:多个 X 映射至一个 bin,这样 X 和 T 之间的映射不再是完美可逆的。
分箱对信息理论分析非常关键,「但是,实践中噪声没有添加至这些神经网络的训练或测试过程中。」
tanh 的饱和说明互信息下降时出现了压缩阶段,以及 tanh 网络进入压缩阶段后训练过程变慢的原因:部分输入使非线性函数出现饱和,减少了反向传播的误差梯度。
独立于压缩的泛化
随后,作者使用信息平面镜头进一步研究了压缩和泛化之间的关系。
……我们利用 student-teacher 设置(Seung et al.,1992;Advani & Saxe, 2017)下训练的简单线性网络探索泛化动态的最近结果。该设置可以让我们较精确地计算网络泛化性能和表征的互信息(未经分箱),以及直接对比线性高斯问题已知的信息瓶颈边界。
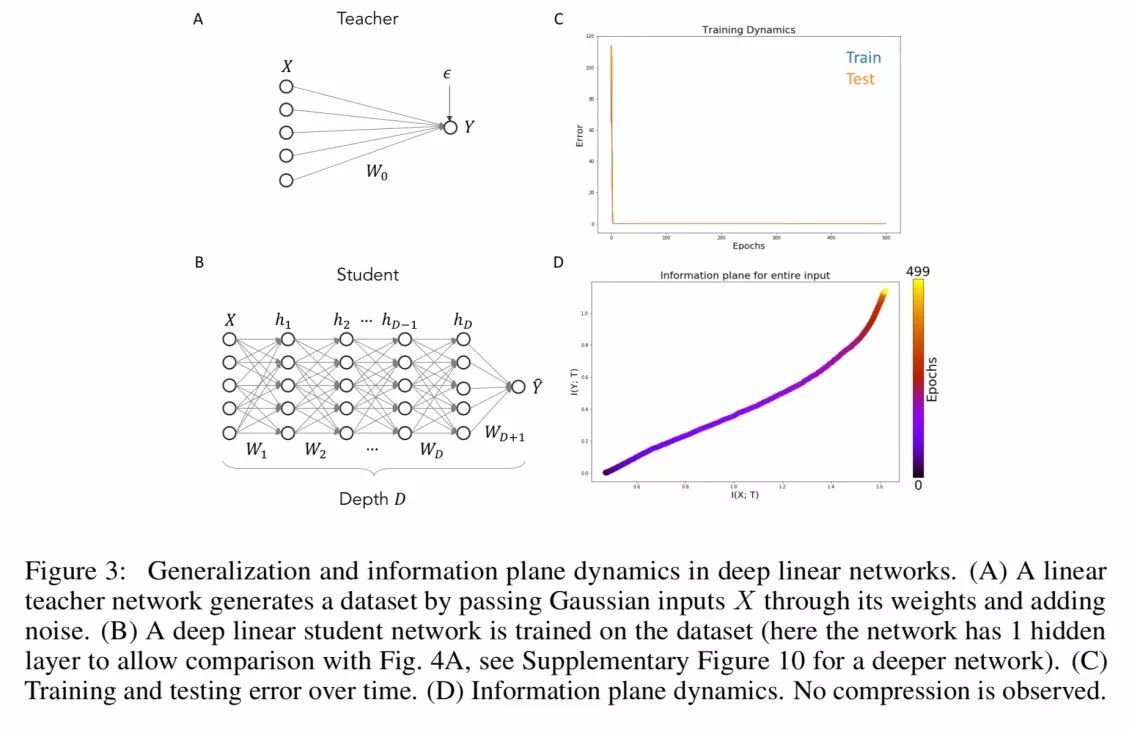
在信息平面中(上图 D)我们没有观察到压缩,尽管网络确实学习了一个可以很好地泛化至任务的路线图,并显示了最小的过度训练。在实验中执行不同程度的过拟合表明,信息平面中具有相似行为的网络可能具有不同的泛化性能。
这就建立了信息平面中行为与泛化动态之间的分离:压缩的网络可能会也可能不会很好地泛化,未压缩的网络也是如此。
随机有助于压缩吗?
接下来,作者首先研究了导致压缩的因素,分析了随机梯度下降(SGD)和批量梯度下降(BGD)的区别。SGD 从数据集中拿出一个样本,并计算相关的误差梯度,而批量梯度下降使用所有样本的整体误差:「关键是,在更新中没有随机或扩散性的行为。」
使用 SGD 和 BGD 对 tanh 和线性网络分别进行训练,信息平面动态如下:
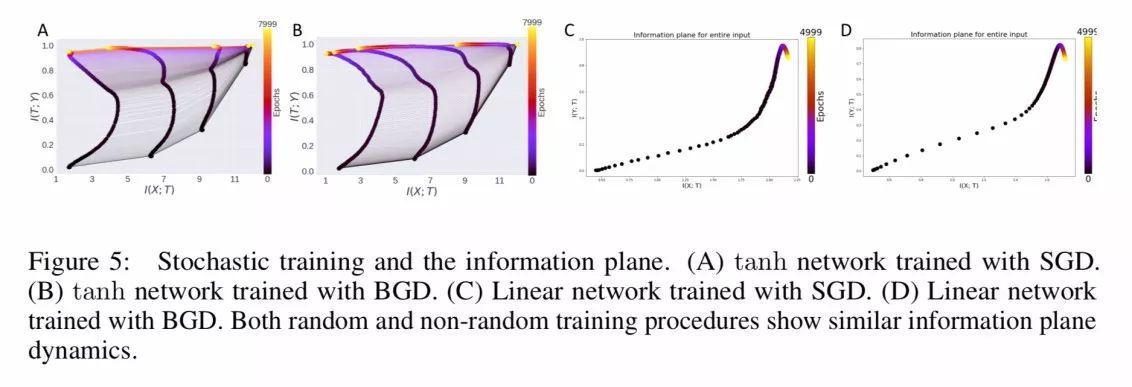
我们发现二者的信息动态大体一致,tanh 网络对于两种方法都有较鲁棒的压缩。因此训练过程中的随机性似乎对输入信息的压缩贡献不大。该发现与「压缩主要原因是双饱和非线性」的观点一致。
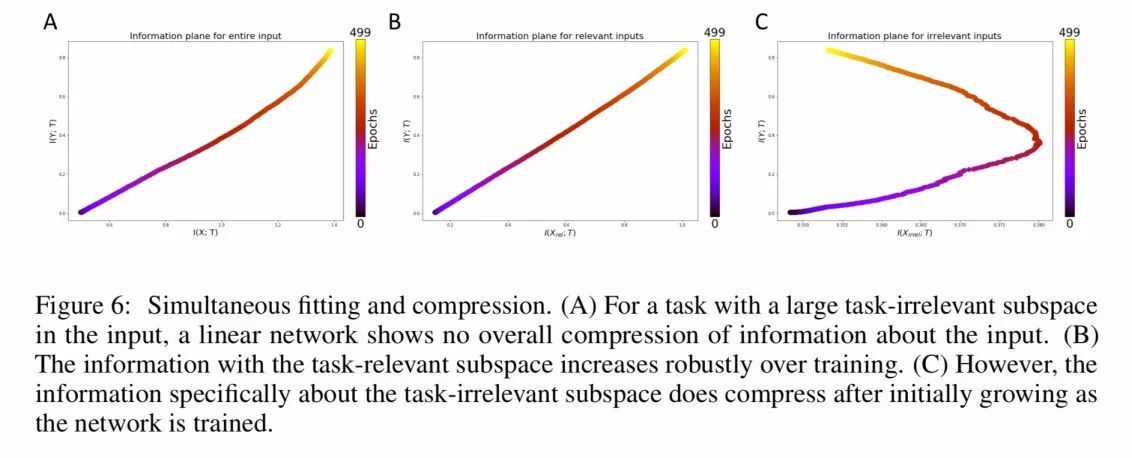
对任务不相关信息进行压缩
最后的实验将输入 X 分割成任务相关的输入和任务不相关的输入。前者贡献信号,后者贡献噪声。因此好的泛化似乎需要忽略噪声。论文作者发现当任务相关的信息发生拟合时,任务不相关的信息发生压缩,尽管整体看来没有观察到输入出现压缩阶段。
结果
我们的结果表明信息平台中的压缩动态不是深层网络的普遍特征,但是网络使用的非线性函数对此有很大影响……信息压缩可以与尖锐最小值(sharp minima)同时出现;尽管实验证明在特定设置中泛化误差和架构有关系,进一步的理论分析证明尖锐最小值也可以实现很好的泛化效果。
论文:On the Information Bottleneck Theory of Deep Learning

论文链接:https://openreview.net/forum?id=ry_WPG-A-
摘要:深度神经网络的理论与实践成果并不匹配,理论无法解释深度神经网络的行为。本论文研究了深度学习的信息瓶颈理论(IB),该理论有三个主要观点:(1)深度网络需要两个阶段:初始拟合阶段和后续压缩阶段;(2)压缩阶段和深度网络卓越的泛化性能之间存在因果关系;(3)压缩阶段由于随机梯度下降的扩散行为才会出现。本文中,我们证明了这些观点通常情况下是错误的。通过分析结果和模拟,我们展示了信息平面轨迹主要使用了一种神经非线性函数:双饱和非线性(double-sided saturating nonlinearities)函数,如 tanh 函数,当神经激活函数进入饱和态时,深度网络进入压缩阶段;而线性激活函数和单饱和非线性函数,如广泛使用的 ReLU 就不是这样。线性神经网络的泛化误差动态的近期结果表明压缩和泛化之间不存在因果关系:没有压缩的网络也能够泛化,反之亦然。通过使用全批量梯度下降代替随机梯度下降来复现瓶颈理论,我们还证明了压缩阶段不需要训练过程中的随机性。最后,我们证明当输入域包含任务相关或不相关信息的子集时,隐藏的表征(hidden representation)对任务不相关的信息进行压缩,尽管输入的整体信息随着训练时间而单调递增,压缩与拟合过程并行发生,而不是在后续的压缩阶段中出现。
一言以蔽之,我们验证了深度学习信息瓶颈理论中的多个观点在一般情况下并不正确。
争议
值得一提的是,在 Open Review 论文平台上,「信息瓶颈」理论的提出者 Naftali Tishby 等人也与论文作者展开了交锋。Tishby 表示,这篇新论文重复和验证了「信息瓶颈」理论先前研究的实验,证实并强化了这一理论,但同时又忽略了许多理论和实验结果,在许多方面都是有缺陷和误导性的。
相关链接
Ravid Shwartz-Ziv 与 Naftali Tishby 2017 年提交的论文《Opening the Black Box of Deep Neural Networks via Information》:https://arxiv.org/abs/1703.00810
原文链接:https://blog.acolyer.org/2017/11/24/on-the-information-bottleneck-theory-of-deep-learning/
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4692.html
摘要:我们称之为啤酒泡沫。是什么让牛顿这样的智者也变得如此疯狂第一,钱多路窄。这些发生在区块链领域的监管并不是坏事。 不知道大家有没有过倒啤酒的经验,当我们往杯中倒啤酒时,倒得越快,产生的泡沫就越多。这些泡沫很快会溢出杯外,而杯中的啤酒则会因泡沫的溢出迅速减少,甚至只留下不到一半。我们称之为啤酒泡沫。 showImg(https://segmentfault.com/img/bVbggjL?...
摘要:认为,深度神经网络根据一种被称为信息瓶颈的过程在学习,他和两位合作者最早在年对这一过程进行了纯理论方面的描述。另外一些研究人员则持怀疑态度,认为信息瓶颈理论不能完全解释深学习的成功。 利用深度神经网络的机器已经学会了交谈、开车,在玩视频游戏和下围棋时击败了世界冠军,还能做梦、画画,帮助进行科学发现,但同时它们也深深地让其发明者困惑,谁也没有料到所谓的深度学习算法能做得这么好。没有基本的原则指...
摘要:耶路撒冷希伯来大学的计算机与神经科学家提出了一项名为信息瓶颈的新理论,有望最终打开深度学习的黑箱,以及解释人脑的工作原理。 耶路撒冷希伯来大学的计算机与神经科学家 Naftali Tishby 提出了一项名为「信息瓶颈」(Information Bottleneck)的新理论,有望最终打开深度学习的黑箱,以及解释人脑的工作原理。这一想法是指神经网络就像把信息挤进瓶颈一样,只留下与一般概念更为...
摘要:创新萌芽期望最顶点下调预期至低点回归理想生产率平台。而大数据已从顶峰滑落,和云计算接近谷底。对于迅速成长的中国市场,大公司也意味着大数据。三家对大数据的投入都是不惜余力的。 非商业转载请注明作译者、出处,并保留本文的原始链接:http://www.ituring.com.cn/article/177529 董飞,Coursera数据工程师。曾先后在创业公司酷迅,百度基础架构组...

阅读 3150·2021-08-03 14:05
阅读 2200·2019-08-29 15:35
阅读 725·2019-08-29 13:30
阅读 3225·2019-08-29 13:20
阅读 2583·2019-08-23 18:15
阅读 1852·2019-08-23 14:57
阅读 2268·2019-08-23 13:57
阅读 1387·2019-08-23 12:10





