
摘要:要理解网络中的单个特征,比如特定位置的某个神经元或者一整个通道,就可以找让这个特征产生很高的值的样本。另一方面,也能看到一些神经元同时对多个没什么关系的概念产生响应。实际操作经验中,我们也认为是一组神经元的组合共同表征了一张图像。
深度神经网络解释性不好的问题一直是所有研究人员和商业应用方案上方悬着的一团乌云,现代CNN网络固然有强大的特征抽取能力,但没有完善的理论可以描述这个抽取过程的本质,人类也很难理解网络学到的表征。
当然了,研究人员们从来都不会放弃尝试。IMCL 2017的较佳论文奖就颁给了 Pang Wei Koh 和 Percy Liang的「Understanding Black-box Predictions via Influence Functions」,探究训练数据对模型训练过程的影响;近期引发全面关注的 Geoffery Hinton的胶囊论文也通过多维激活向量带来了更好的解释性,不同的维度表征着不同的属性。
近日,来自谷歌大脑和谷歌研究院的一篇技术文章又从一个新的角度拓展了人类对神经网络的理解,得到的可视化结果也非常亮眼、非常魔性,比如下面这样,文中的结果也在Twitter上引发了许多关注和讨论。
用优化方法形成可视化
作者们的目标是可视化呈现让网络激活的那些特征,也就是回答“模型都在图像中找什么特征”这个问题。他们的思路是新生成一些会让网络激活的图像,而不是看那些数据集中已有的能让网络激活的图像,因为已有图像中的特征很可能只是“有相关性”,在分析的时候可能只不过是“人类从许多特征中选出了自己认为重要的”,而下面的优化方法就能真正找到图像特征和网络行为中的因果性。
总体来说,神经网络是关于输入可微的。如果要找到引发网络某个行为的输入,不管这个行为只是单个神经元的激活还是最终的分类器输出,都可以借助导数迭代地更新输入,最终确认输入图像和选定特征之间的因果关系。(实际执行中当然还有一些技巧,见下文“特征可视化的实现过程”节)

从随机噪音开始,迭代优化一张图像让它激活指定的某一个神经元(以4a层的神经元11为例)
作者们基于带有 Inception 模块的 GoogLeNet展开了研究,这是一个2014年的模型 (https://arxiv.org/pdf/1409.4842.pdf ),当年也以6.67%的前5位错误率拿下了 ILSVRC 2014图像分类比赛的冠军。模型结构示意图如下;训练数据集是 ImageNet。
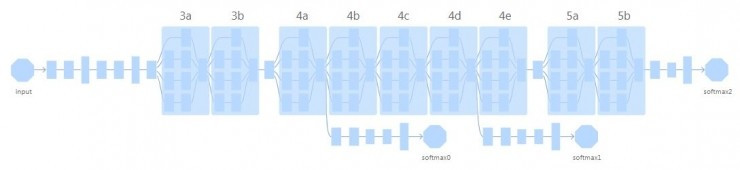
GoogLeNet 结构示意图。共有9个Inception模块;3a模块前有两组前后连接的卷积层和较大池化层;3b和4a、4e和5a之间各还有一个较大池化层。
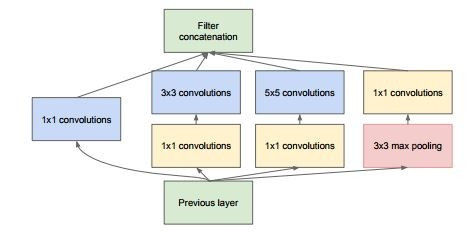
带有降维的 Inception 模块(单个模块)
优化目标
有了思路和网络之后就要考虑以网络的哪部分结构作为输入优化的目标;即便对于在数据集中找样本的方法也需要考虑这个。这里就有很多种选择,是单个神经元、某个通道、某一层、softmax前的类别值还是softmax之后的概率。不同的选择自然会带来不同的可视化结果,如下图

以不同的网络结构为目标可以找到不同的输入图像。这里 n 为层序号,x,y 为空间位置, z 为通道序号,k 为类别序号。
要理解网络中的单个特征,比如特定位置的某个神经元、或者一整个通道,就可以找让这个特征产生很高的值的样本。文中多数的图像都是以通道作为目标生成的。
要理解网络中的完整一层,就可以用 DeepDream的目标,找到整个层觉得“有兴趣”的图像。
要从分类器的阶段出发找到输入样本的话,会遇到两个选择,优化softmax前的类别值还是优化softmax后的类别概率。softmax前的类别值其实可以看作每个类别出现的证据确凿程度,softmax后的类别概率就是在给定的证据确凿程度之上的似然值。不过不幸的是,增大softmax后的某一类类别概率的最简单的办法不是让增加这一类的概率,而是降低别的类的概率。所以根据作者们的实验,以softmax前的类别值作为优化目标可以带来更高的图像质量。
可视化结果一:不同的层优化得到不同的图像
3a层

第一个Inception层就已经显示出了一些有意思的纹理。由于每个神经元只有一个很小的感受野,所以整个通道的可视化结果就像是小块纹理反复拼贴的结果。
3b层

纹理变得复杂了一些,但还都是比较局部的特征
4a层

4a层跟在了一个较大池化层之后,所以可以看到复杂性大幅度增加。图像中开始出现更复杂的模式,甚至有物体的一部分。
4b层

可以明显看到物体的某些部分了,检测台球的例子中就能清楚看到球的样子。这时的可视化结果也开始带有一些环境信息,比如树的例子中就能看到树背后的蓝天和树脚下的地面。
4c层

这一层的结果已经足够复杂了,只看几个神经元的优化结果可以比看整个通道更有帮助。有一些神经元只关注拴着的小狗,有的只关注轮子,也有很多其它的有意思的神经元。这也是作者们眼中最有收获的一层。
4d层

这一层中有更复杂的概念,比如第一张图里的某种动物的口鼻部分。另一方面,也能看到一些神经元同时对多个没什么关系的概念产生响应。这时需要通过优化结果的多样性和数据集中的样本帮助理解神经元的行为。
4e层

在这一层,许多神经元已经可以分辨不同的动物种类,或者对多种不同的概念产生响应。不过它们视觉上还是很相似,就会产生对圆盘天线和墨西哥宽边帽都产生反应的滑稽情况。这里也能看得到关注纹理的检测器,不过这时候它们通常对更复杂的纹理感兴趣,比如冰激凌、面包和花椰菜。这里的第一个例子对应的神经元正如大家所想的那样对可以乌龟壳产生反应,不过好玩的是它同样也会对乐器有反应。
5a层

这里的可视化结果已经很难解释了,不过它们针对的语义概念都还是比较特定的
5b层

这层的可视化结果基本都是找不到任何规律的拼贴组合。有可能还能认得出某些东西,但基本都需要多样性的优化结果和数据集中的样本帮忙。这时候能激活神经元的似乎并不是有什么特定语义含义的结构。
可视化结果二:样本的多样性
其实得到可视性结果之后就需要回答一个问题:这些结果就是全部的答案了吗?由于过程中存在一定的随机性和激活的多重性,所以即便这些样本没什么错误,但它们也只展示了特征内涵的某一些方面。
不同激活程度的样本
在这里,作者们也拿数据集中的真实图像样本和生成的样本做了比较。真实图像样本不仅可以展现出哪些样本可以极高程度地激活神经元,也能在各种变化的输入中看到神经元分别激活到了哪些程度。如下图



可以看到,对真实图像样本来说,多个不同的样本都可以有很高的激活程度。
多样化样本
作者们也根据相似性损失或者图像风格转换的方法产生了多样化的样本。如下图

多样化的特征可视化结果可以更清晰地看到是哪些结构能够激活神经元,而且可以和数据集中的照片样本做对比,确认研究员们的猜想的正确性(这反过来说就是上文中理解每层网络的优化结果时有时需要依靠多样化的样本和数据集中的样本)。

比如这张图中,多带带看第一排第一张简单的优化结果,我们很容易会认为神经元激活需要的是“狗头的顶部”这样的特征,因为优化结果中只能看到眼睛和向下弯曲的边缘。在看过第二排的多样化样本之后,就会发现有些样本里没有包含眼睛,有些里包含的是向上弯曲的边缘。这样,我们就需要扩大我们的期待范围,神经元的激活靠的可能主要是皮毛的纹理。带着这个结论再去看看数据集中的样本的话,很大程度上是相符的;可以看到有一张勺子的照片也让神经元激活了,因为它的纹理和颜色都和狗的皮毛很相似。
对更高级别的神经元来说,多种不同类别的物体都可以激活它,优化得到的结果里也就会包含这各种不同的物体。比如下面的图里展示的就是能对多种不同的球类都产生响应的情况。

这种简单的产生多样化样本的方法有几个问题:首先,产生互有区别的样本的压力会在图像中增加无关的瑕疵;而且这个优化过程也会让样本之间以不自然的方式产生区别。比如对于上面这张球的可视化结果,我们人类的期待是看到不同的样本中出现不同种类的球,但实际上更像是在不同的样本中出现了各有不同的特征。
多样性方面的研究也揭露了另一个更基础的问题:上方的结果中展示的都还算是总体上比较相关、比较连续的,也有一些神经元感兴趣的特征是一组奇怪的组合。比如下面图中的情况,这个神经元对两种动物的面容感兴趣,另外还有汽车车身。

类似这样的例子表明,想要理解神经网络中的表义过程时,神经元可能不一定是合适的研究对象。
可视化结果三:神经元间的互动
如果神经元不是理解神经网络的正确方式,那什么才是呢?作者们也尝试了神经元的组合。实际操作经验中,我们也认为是一组神经元的组合共同表征了一张图像。单个神经元就可以看作激活空间中的单个基础维度,目前也没发现证据证明它们之间有主次之分。
作者们尝试了给神经元做加减法,比如把表示“黑白”的神经元加上一个“马赛克”神经元,优化结果就是同一种马赛克的黑白版本。这让人想起了Word2Vec中词嵌入的语义加减法,或者生成式模型中隐空间的加减法。
联合优化两个神经元,可以得到这样的结果。


也可以在两个神经元之间取插值,便于更好理解神经元间的互动。这也和生成式模型的隐空间插值相似。


不过这些也仅仅是神经元间互动关系的一点点皮毛。实际上作者们也根本不知道如何在特征空间中选出有意义的方向,甚至都不知道到底有没有什么方向是带有具体的含义的。除了找到方向之外,不同反向之间如何互动也还存在疑问,比如刚才的差值图展示出了寥寥几个神经元之间的互动关系,但实际情况是往往有数百个神经元、数百个方向之间互相影响。
特征可视化的实现过程
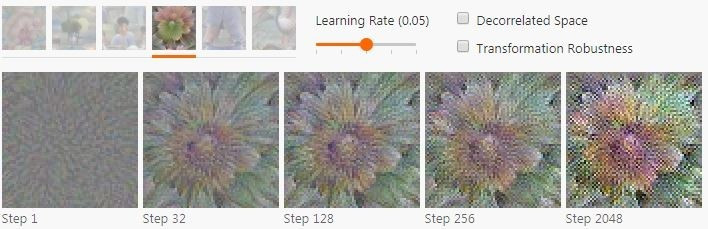
如前文所说,作者们此次使用的优化方法的思路很简单,但想要真的产生符合人类观察习惯的图像就需要很多的技巧和尝试了。直接对图像进行优化可能会产生一种神经网络的光学幻觉 —— 人眼看来是一副全是噪声、带有看不出意义的高频图样的图像,但网络却会有强烈的响应。即便仔细调整学习率,还是会得到明显的噪声。(下图学习率0.05)

这些图样就像是作弊图形,用现实生活中不存在的方式激活了神经元。如果优化的步骤足够多,最终得到的东西是神经元确实有响应,但人眼看来全都是高频图样的图像。这种图样似乎和对抗性样本的现象之间有紧密的关系。
作者们也不清楚这些高频图样的具体产生原因,他们猜想可能和带有步幅的卷积和较大池化操作有关系,两者都可以在梯度中产生高频率的图样。

通过反向传播过程作者们发现,每次带有步幅的卷积或者较大池化都会在梯度维度中产生棋盘般的图样
这些高频图样说明,虽然基于优化方法的可视化方法不再受限于真实样本,有着极高的自由性,它却也是一把双刃剑。如果不对图像做任何限制,最后得到的就是对抗性样本。这个现象确实很有意思,但是作者们为了达到可视化的目标,就需要想办法克服这个现象。
不同规范化方案的对比
在特征可视化的研究中,高频噪音一直以来都是主要的难点和重点攻关方向。如果想要得到有用的可视化结果,就需要通过某些先验知识、规范化或者添加限制来产生更自然的图像结构。
实际上,如果看看特征可视化方面最著名的论文,它们最主要的观点之一通常都是使用某种规范化方法。不同的研究者们尝试了许多不同的方法。
文章作者们根据对模型的规范化强度把所有这些方法看作一个连续的分布。在分布的一端,是完全不做规范化,得到的结果就是对抗性样本;在另一端则是在现有数据集中做搜索,那么会出现的问题在开头也就讲过了。在两者之间就有主要的三大类规范化方法可供选择。
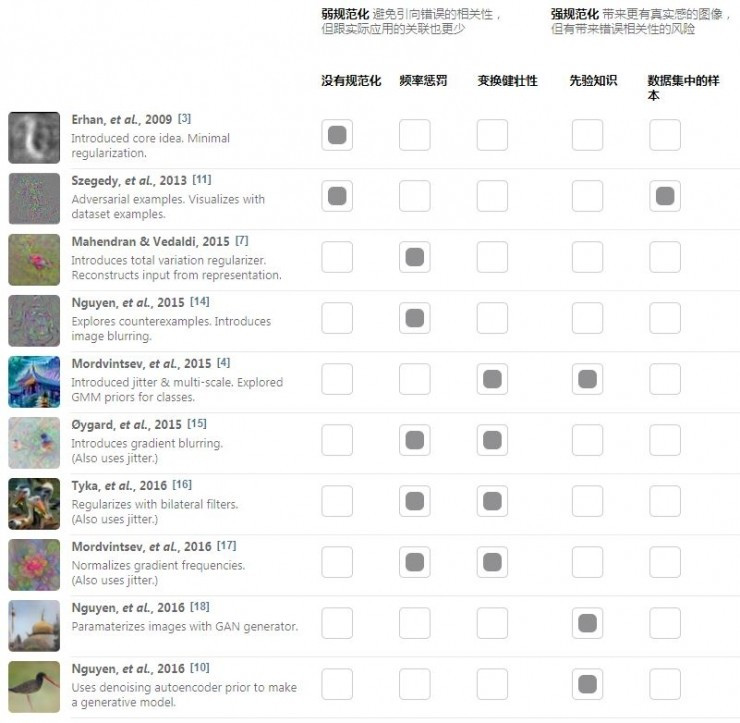
频率惩罚直接针对的就是高频噪音。它可以显式地惩罚相邻像素间出现的高变化,或者在每步图像优化之后增加模糊,隐式地惩罚了高频噪音。然而不幸的是,这些方法同时也会限制合理的高频特征,比如噪音周围的边缘。如果增加一个双边过滤器,把边缘保留下来的话可以得到一些改善。如下图。

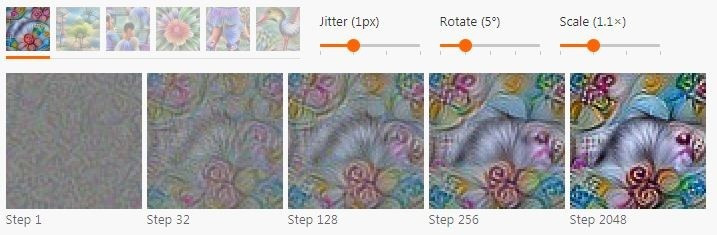
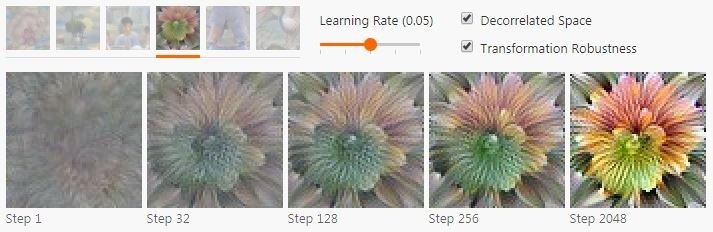
变换健壮性会尝试寻找那些经过小的变换以后仍然能让优化目标激活的样本。对于图像的例子来说,细微的一点点变化都可以起到明显的作用,尤其是配合使用一个更通用的高频规范器之后。具体来说,这就代表着可以随机对图像做抖动、宣传或者缩放,然后把它应用到优化步骤中。如下图。
先验知识。作者们一开始使用的规范化方法都只用到了非常简单的启发式方法来保持样本的合理性。更自然的做法是从真实数据学出一个模型,让这个模型迫使生成的样本变得合理。如果有一个强力的模型,得到的效果就会跟搜索整个数据集类似。这种方法可以得到最真实的可视化结果,但是就很难判断结果中的哪些部分来自研究的模型本身的可视化,哪些部分来自后来学到的模型中的先验知识。
有一类做法大家都很熟悉了,就是学习一个生成器,让它的输出位于现有数据样本的隐空间中,然后在这个隐空间中做优化。比如GAN或者VAE。也有个替代方案是学习一种先验知识,通过它控制概率梯度;这样就可以让先验知识和优化目标共同优化。为先验知识和类别的可能性做优化是,就同步形成了一个限制在这个特定类别数据下的生成式模型。
预处理与参数化
前面介绍的几种方法都降低了梯度中的高频成分,而不是直接去除可视化效果中的高频;它们仍然允许高频梯度形成,只不过随后去减弱它。
有没有办法不让梯度产生高频呢?这里就有一个强大的梯度变换工具:优化中的“预处理”。可以把它看作同一个优化目标的最速下降法,但是要在这个空间的另一个参数化形式下进行,或者在另一种距离下进行。这会改变最快速的那个下降方向,以及改变每个方向中的优化速度有多快,但它并不会改变最小值。如果有许多局部极小值,它还可以拉伸、缩小它们的范围大小,改变优化过程会掉入哪些、不掉入哪些。
最终的结果就是,如果用了正确的预处理方法,就可以让优化问题大大简化。
那么带有这些好处的预处理器如何选择呢?首先很容易想到的就是让数据去相关以及白化的方法。对图像来说,这就意味着以Fourier变换做梯度下降,同时要缩放频率的大小这样它们可以都具有同样的能量。
不同的距离衡量方法也会改变最速下降的方向。L2范数梯度就和L∞度量或者去相关空间下的方向很不一样。
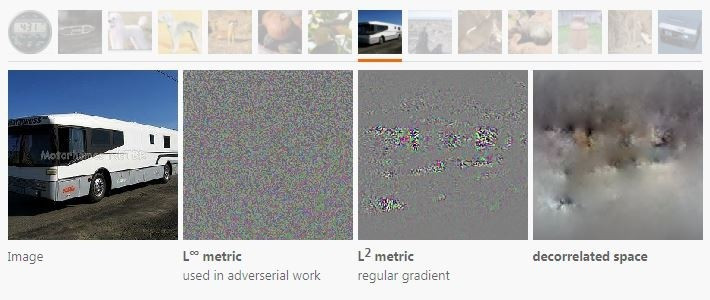
所有这些方向都是同一个优化目标下的可选下降方向,但是视觉上看来它们的区别非常大。可以看到在去相关空间中做优化能够减少高频成分的出现,用L∞则会增加高频。
选用去相关的下降方向带来的可视化结果也很不一样。由于超参数的不同很难做客观的比较,但是得到的结果看起来要好很多,而且形成得也要快得多。这篇文章中的多数图片就都是用去相关空间的下降和变换健壮性方法一起生成的(除特殊标明的外)。

那么,是不是不同的方法其实都能下降到同一个点上,是不是只不过正常的梯度下降慢一点、预处理方法仅仅加速了这个下降过程呢?还是说预处理方法其实也规范化(改变)了最终达到的局部极小值点?目前还很难说得清。一方面,梯度下降似乎能一直让优化过程进行下去,只要增加优化过程的步数 —— 它往往并没有真的收敛,只是在非常非常慢地移动。另一方面,如果关掉所有其它的规范化方法的话,预处理方法似乎也确实能减少高频图案的出现。
结论
文章作者们提出了一种新的方法创造令人眼前一亮的可视化结果,在呈现了丰富的可视化结果同时,也讨论了其中的重大难点和如何尝试解决它们。
在尝试提高神经网络可解释性的漫漫旅途中,特征可视化是最有潜力、得到了最多研究的方向之一。不过多带带来看,特征可视化也永远都无法带来完全让人满意的解释。作者们把它看作这个方向的基础研究之一,虽然现在还有许多未能解释的问题,但我们也共同希望在未来更多工具的帮助下,人们能够真正地理解深度学习系统。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4675.html
摘要:从到,计算机视觉领域和卷积神经网络每一次发展,都伴随着代表性架构取得历史性的成绩。在这篇文章中,我们将总结计算机视觉和卷积神经网络领域的重要进展,重点介绍过去年发表的重要论文并讨论它们为什么重要。这个表现不用说震惊了整个计算机视觉界。 从AlexNet到ResNet,计算机视觉领域和卷积神经网络(CNN)每一次发展,都伴随着代表性架构取得历史性的成绩。作者回顾计算机视觉和CNN过去5年,总结...

阅读 1978·2021-11-24 09:39
阅读 2759·2021-10-14 09:43
阅读 3394·2021-10-08 10:10
阅读 2406·2021-09-22 15:54
阅读 2400·2019-08-29 17:20
阅读 1616·2019-08-28 18:14
阅读 2423·2019-08-26 13:28
阅读 1163·2019-08-26 12:16



