
摘要:的这项研究,总共生成了篇深度学习论文的和代码,还创建了一个网站,供同行们众包编辑这些代码。来自印度研究院。目前是印度研究院的实习生。
深度学习的论文越来越多了~
多到什么程度?Google scholar的数据显示,2016年以来,人工智能领域新增的论文已经超过3.5万篇。arXiv上,AI相关的论文每天都不下百篇。
刚刚结束不久的计算机视觉会议ICCV上,发表了621篇论文;2018年的ICLR,有1004篇论文正在匿名开放评审;NIPS 2017共收到3240篇论文投稿。
研究成果极大丰富了,但离应用到产品中,还差一大步:把论文转化成代码。毕竟,作者顺便提供源码的是少数。
怎么办?
IBM印度研究院最近公布了一项新研究:DLPaper2Code,顾名思义,这个程序能够用深度学习技术,将论文转化成代码。

论文转代码的过程
这么神奇?!该不是看到一篇假研究?
坦白讲,相关论文DLPaper2Code: Auto-generation of Code from Deep Learning Research Papers已经被AAAI 2018接收为会议论文。
AAAI是人工智能顶会之一,明年就是第32届了,2月2-7日在美国路易斯安那州的新奥尔良召开。百度、京东是大会的黄金赞助商。

深度学习论文自动转代码
这篇论文中指出,由于大部分深度学习论文都会用流程图来表示神经网络模型的设计模式,因此,在论文转换成代码的过程中,DLPaper2Code首先提取、理解论文中描述的深度学习设计流程图和表格,将它们转化成抽象的计算图。
然后,它会把抽取的计算图转换成Keras和Caffe框架下的可执行源代码。
IBM的这项研究,总共生成了5000篇arXiv深度学习论文的Caffe和Keras代码,还创建了一个网站,供同行们众包编辑这些代码。不过,这个网站的地址还没有公布,目前只能看到截图:
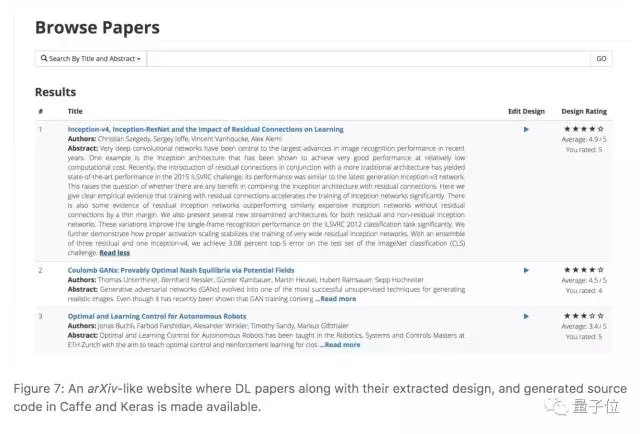
在提取流程图的过程中,IBM的研究员们遇到了一些障碍:他们需要让程序提取论文中所有图表之后,再进行一次分类,找出包含深度学习模型设计的那些,去掉那些和模型相关性不大的描述性图片和展示结果的表格。
但是,论文中介绍深度学习模型设计的图千奇百怪,表格的结构也各不相同。
怎样让程序自动找出有用的图表呢?IBM研究员们人肉处理了论文中的3万张图,将深度学习模型设计图分成了5大类:
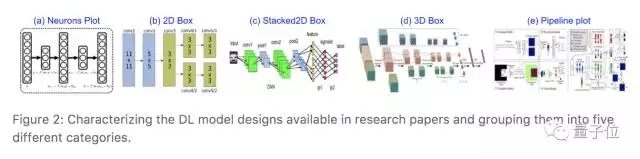
5大类深度学习模型设计图
1. 神经元分布图;
2. 2D Box:将每个隐藏层表示为一个2D方块;
3. Stacked2D Box:将神经网络每一层表示为堆叠的2D方块,表示层的深度;
4. 3D Box:将每个隐藏层表示为一个3D立方体结构;
5. 表示整个流程的Pipeline plot。
而表格,主要包括横排表示模型设计流程和纵列表示模型设计流程两类。
在此基础上,他们构建了一个细粒度的分类器,来把图表分到上面提到的5类图2类表之中,然后就可以使用OCR等工具将图表中的内容提取出来。
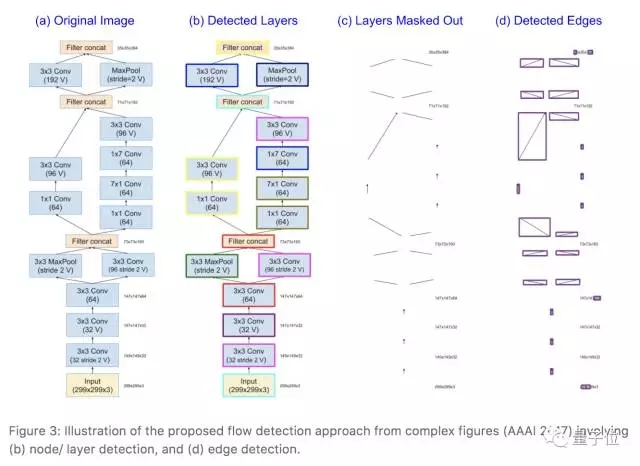
从图中提取内容的过程
图表内容提取出来之后,就可以根据这些信息构建计算图并生成源代码了。
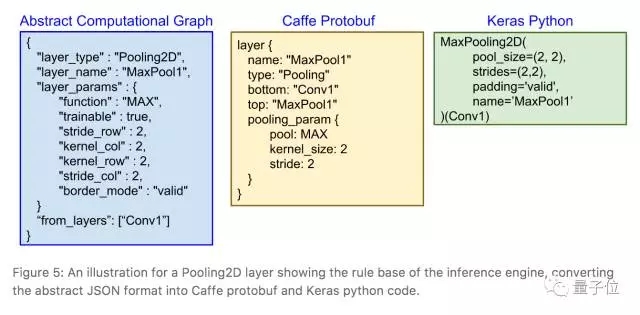
池化2D层对应的计算图、Caffe(Protobuf)和Keras(Python)代码
自动生成的代码究竟怎么样呢?
为了对DLPaper2Code进行评估,IBM研究员们创建了一个包含21.6万份设计可视化图的模拟数据集,在这些数据集上的实验显示,上面讲的模型,在流程图内容提取上准确率可达93%。
AI自动化畅想曲
上面这个研究。来自IBM印度研究院。
共有五位署名作者:Akshay Sethi、Anush Sankaran、Naveen Panwar、Shreya Khare、Senthil Mani。其中第一作者Akshay Sethi,明年才会本科毕业。目前是IBM印度研究院的实习生。
嗯,实习生又开挂了。中外概莫能外~
但这么一篇清新脱俗的研究,真能在实践中应用么?
在reddit上,不少人还是对这篇论文有点心生疑虑。比方有人觉得这个论文很有意思,但是细细读下来,还是有些地方比较奇怪。但也有人觉得虽然标题有点唬人,但这项研究感觉还是不错。当然也有人直言:浪费时间。
更多的结论还有待时间考验,但归根结底,这些都是AI自动化方向的一种探索。让AI自己搞定AI,让软件自己编写软件,一直都是研究人员追逐的目标。
比方今年5月,Google发布了AutoML。对,就是跟今天正式推出的TensorFlow Lite同天发布的AutoML。
AutoML就是要让神经网络去设计神经网络。谷歌希望能借AutoML来促进深度学习开发者规模的扩张,让设计神经网络的人,从供不应求的PhD,变成成千上万的普通工程师。

也是在今年,MIT学者开发出一套系统,能够自动给代码打补丁。
听起来,以后码农越来越好干了呢。其实不是。
要知道,微软和剑桥联合开发了一个系统:DeepCoder。就能够通过搜索一系列代码建立一个完整的程序,可达到编程比赛的水平。而且,这个系统还能通过自我训练能够变得更聪明。未来程序员的饭碗也不是很铁了。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4673.html
摘要:期间,我从爬虫入手,一路摸爬滚打,实现了千万级微博评论自动抓取,在即将成为爬虫专家前,受师兄指点转向算法。确定研究方向经过前面的理论学习,你应该发现深度学习领域有很多细分方向,例如语音自然语言处理视觉强化学习纯深度学习理论。 最近很多刚入学的学弟学妹给我们留言,听说算法岗现在竞争很激烈,...
摘要:不过,苹果实验室作为计算机学院的学习类组织,撰写此贴的内容集中于本科期间学习路线的宏观规划建议。其中主要问题大概是初入大学的迷茫与美好大学愿景之间的矛盾自主学习能力的欠缺与远大志向的矛盾。 ...
摘要:主流机器学习社区对神经网络兴趣寡然。对于深度学习的社区形成有着巨大的影响。然而,至少有两个不同的方法对此都很有效应用于卷积神经网络的简单梯度下降适用于信号和图像,以及近期的逐层非监督式学习之后的梯度下降。 我们终于来到简史的最后一部分。这一部分,我们会来到故事的尾声并一睹神经网络如何在上世纪九十年代末摆脱颓势并找回自己,也会看到自此以后它获得的惊人先进成果。「试问机器学习领域的任何一人,是什...

阅读 2764·2023-04-25 17:58
阅读 3026·2021-11-15 11:38
阅读 2442·2021-11-02 14:48
阅读 1247·2021-08-25 09:40
阅读 1878·2019-08-30 15:53
阅读 1151·2019-08-30 15:52
阅读 1072·2019-08-30 13:55
阅读 2497·2019-08-29 15:21




