
摘要:在现有深度学习框架下,我们所编写的卷积层往往是一个单行语句,它可以抽象出许多结构细节。本文试图阐述卷积层的一个特定的解剖特征,而这是在大多数文章和相关讨论中被忽略的问题。来自卷积层的输出经常用作后续卷积层的输入。
近来,深度学习的火爆程度显而易见,而在深度学习领域,卷积网络则是引起这许多令人惊叹的结果的主要原因。自从2012年AlexNet公开亮相之后,现如今,我们很难列举一个根本不使用卷积架构,具有突破性的计算机视觉架构。
在现有深度学习框架下,我们所编写的卷积层往往是一个单行语句,它可以抽象出许多结构细节。不过,有时候后退一步去揭开一些抽象概念也是一个不错的选择。本文试图阐述卷积层的一个特定的解剖特征,而这是在大多数文章和相关讨论中被忽略的问题。
许多卷积架构是从一个外部卷积单元开始的,它将信道RGB的输入图像映射到一系列内部过滤器中。在当下最通用的深度学习框架中,这个代码可能如下所示:
out_1=Conv2d(input=image, filter=32, kernel_size=(3,3), strides=(1,1))
relu_out=relu(out_1)
pool_out=MaxPool(relu_out, kernel_size=(2,2), strides=2)
对许多人来说,我们都很清楚,上面的结果是一系列的具有32层深度的过滤器。我们不知道的是,该如何将具有3个信道的图像较精确地映射到这32层中!另外,我们也不清楚该如何应用较大池(max-pool)操作符。例如,是否一次性将较大池化应用到了所有的过滤层中以有效地生成一个单一的过滤映射?又或者,是否将较大池独立应用于每个过滤器中,以产生相同的32层的池化过滤器?
如何做
一张图胜过千言万语,下面有一个图表,可以显示上述代码片段中所有的操作。
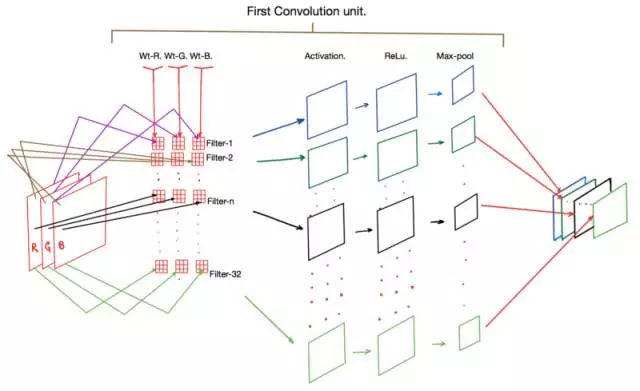
卷积层的应用
观察上图,可以看到最显著的一点是,步骤1中的每个过滤器(即过滤器-1、过滤器-2……)实际上包含一组3个卷积核(Wt-R、Wt-G和WT-B)。这些内核中的每一个分别保存为输入图像中的红(R)、绿(G)和蓝(B)信道。
在正向传播期间,图像中的R、G和B像素值分别与Wt-R、Wt-G和Wt-B内核相乘以产生一个间歇激活映射(intermittent activation map)(图中未标出)。然后将三个核的输出相加以为每个过滤器产生一个激活映射。
随后,这些激活中的每一个都要受到ReLu函数的支配,最后运行到较大池化层,而后者主要负责减少输出激活映射的维度。最后,我们得到的是一组激活映射,通常其维数是输入图像的一半,但现在其信号跨越了一组32个选择(我们选择作为过滤器的数量)作为二维张量。
来自卷积层的输出经常用作后续卷积层的输入。因此,如果我们的第二个卷积单元如下:
conv_out_2 = Conv2d(input = relu_out,filters = 64)
那么框架就需要实例化64个过滤器,每个过滤器使用一组32个独特的核。
为什么
另一个微妙的但重要的一点,就是为什么我们为第一个卷积层使用了32个过滤器。在许多常用的体系结构中,随着我们深入网络,所使用的过滤器数量也越来越大(例如,第二个为64,第三个为128,依此类推)。
在本文中,Matt Zeiler使用了一个反卷积算子,以便可视化深度卷积结构的不同层次和深度的核在训练过程中得到调谐。普遍的共识是,在经过最优训练的卷积网络中,在边缘(接近图像)的滤波器对基本边缘和图案变得敏感。深层中的过滤器对逐渐升高的阶数形状和模式敏感。这些现象在Matt论文的图表中得到了很好的总结:

在第一层和第二层(最外层)上过滤器激活的可视化

第三层过滤器激活的可视化

第4层和第5层的过滤器的可视化激活
另一个我想了很长一段时间的问题是,为什么不同的过滤器,即使在任何给定的层,都会被调整到一个特定的形状或模式。毕竟,任何内核的权重都没有什么异常的,这可以保证观察到的结果。正是到了这一点:随机梯度下降(SGD)的过程自动纠正权重,使内核获得以上的特征。重要的是:
•核(或权重矩阵)被随机初始化,以确保每个核都被优化到一个独特的解决方案空间。
•我们定义了足够多的过滤器来较大限度地捕获我们数据集中的各种特征,同时针对所发生的计算成本实现了平衡。
最后,许多论文还提出,过滤器激活的可视化为卷积结构的性能提供了一个窗口。一个平衡的和高性能的网络通常显示如上所述的激活,具有明确的边缘和形状检测器的表现。一个过度拟合、欠拟合和泛化的网络往往无法显示这些观察结果。因此,使用(2)中使用的过程来测试网络是一个好主意,以查看实验性的卷积网络是否产生了良好的结果。
参考文献:
深度卷积神经网络的ImageNet分类,Alex Krizhevsky,Ilya Sutskever,Geoffrey E. Hinton,https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks
卷积网络的可视化与理解,Matthew D Zeiler,Rob Fergus https://arxiv.org/abs/1311.2901
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4665.html
摘要:第二部分高级概念我们现在对卷积有了一个良好的初步认识,也知道了卷积神经网络在干什么为什么它如此强大。 译自Tim Dettmers的Understanding Convolution in Deep Learning。有太多的公开课、教程在反复传颂卷积神经网络的好,却都没有讲什么是卷积,似乎默认所有读者都有相关基础。这篇外文既友好又深入,所以翻译了过来。文章高级部分通过流体力学量子力学等解释...
摘要:文章第一部分旨在帮助读者理解卷积的概念和深度学习中的卷积网络。卷积定理要理解卷积,不得不提,它将时域和空域上的复杂卷积对应到了频域中的元素间简单的乘积。 译者按:本文译自 Tim Dettmers 的 Understanding Convolution in Deep Learning。有太多的公开课、教程在反复传颂卷积神经网络的好,却都没有讲什么是「卷积」,似乎默认所有读者都有相关基础。这...
摘要:年,发表,至今,深度学习已经发展了十几年了。年的结构图图片来自于论文基于图像识别的深度卷积神经网络这篇文章被称为深度学习的开山之作。还首次提出了使用降层和数据增强来解决过度匹配的问题,对于误差率的降低至关重要。 1998年,Yann LeCun 发表Gradient-Based Learning Applied to Document Recognition,至今,深度学习已经发展了十几年了...

阅读 2095·2021-11-08 13:22
阅读 2564·2021-09-04 16:40
阅读 1207·2021-09-03 10:29
阅读 1761·2019-08-30 15:44
阅读 2163·2019-08-30 11:13
阅读 2844·2019-08-29 17:07
阅读 2016·2019-08-29 14:22
阅读 1301·2019-08-26 14:00




