
摘要:近日,团队提出了基于近邻节点注意机制的网络架构,可用于处理复杂不规则结构的计算图,并在三种困难的基准测试中得到了业内较佳水平,研究人员称该模型有望在未来处理任意不规则结构图。
近日,Bengio 团队提出了基于近邻节点注意机制的网络架构 GAT,可用于处理复杂、不规则结构的计算图,并在三种困难的基准测试中得到了业内较佳水平,研究人员称该模型有望在未来处理任意不规则结构图。该论文现已提交至 ICLR 2018 大会。
卷积神经网络已成功应用于解决图像分类、语义分割、机器翻译等问题,其中背后的数据表证有着网格状的结构。这些结构通过把学习到的参数应用到所有的输入位置,能高效的重复使用局部过滤器。
然而,许多有趣任务的数据并不能表示为网格状的结构,而是分布在不规则的区域。这就像是 3D 网格、社交网络、通信网络、生物网络或者大脑连接组一样。这样的数据通常用图(graph)的形式表示。
目前的文献中,已经有很多尝试来拓展神经网络以解决图随意的架构。早期的研究使用递归神经网络在图域中把数据直接表达为有向非循环图。图神经网络网络(GNN)首次出现于 Gori 等人(2005)与 Scarselli 等人(2009)的论文,把它作为递归神经网络的泛化形式,能够直接处理更普遍的图类,比如循环图、有向和无向的图。GNN 包括一个迭代过程,来传播节点状态直到平衡;然后是一个神经网络,基于其状态为每个节点生成一个输出;之后,这种思路被 Li 等人(2016)采用并改进,提出在传播步骤中使用门控循环单元(Cho et al.,2014)。
因此,把卷积泛化到图域中一直是个引发研究者兴趣的课题。在这个方面的进步通常可被归类为光谱方法与非光谱方法。
在这篇论文中,作者们提出了一种基于注意机制的架构,能够完成图结构数据的节点分类。该方法的思路是通过注意其邻位节点,计算图中每个节点的隐藏表征,还带有自注意策略。这种注意架构有多重性质:
(1)运算高效,因为临近节点对可并行;
(2)可以通过对近邻节点指定任意的权重应用于不同 degree 的图节点;
(3)该模型可以直接应用于归纳学习问题中,其中包括了需要将模型泛化到此前未见的图的任务。
作者们提出的通过节点连接共享神经网络计算的方法和关系网络(Santoro et al., 2017)的形式类似,其中对象之间的关系(用卷积神经网络提取图像中的区域特征)通过应用一种共享机制将所有的对象两两配对然后聚合而成。他们在三种有挑战性的基准测试上验证了提出的方法:Cora 和 Citeseer 引用神经网络数据集和一个蛋白质与蛋白质相互作用的数据集,新方法在这些测试中均获得了当前较佳的结果,展现了基于注意的模型处理任意结构图的潜力。
论文:Graph Attention Networks

论文链接:https://arxiv.org/abs/1710.10903
我们提出了图注意网络(graph attention networks,GATs),这是一种新型的神经网络架构,用于处理图结构化的数据(graph-structured data),利用隐藏的自注意层克服了过去的基于图卷积或其近似的方法的缺点。这些层的节点可以注意近邻节点的特征,通过将这些层堆叠起来,我们可以为不同节点的近邻指定不同的权重,而不需要耗费任何繁重的矩阵计算(比如矩阵求逆),也不需要预先知道图的结构。通过这种方法,我们同时解决了多个基于频谱的图神经网络的关键挑战,并准备将模型应用于归纳问题以及直推问题。我们的 GAT 模型在三种公认的直推和归纳图基准测试中取得了当前较佳的结果:Cora 和 Citeseer 引用神经网络数据集和一个蛋白质与蛋白质相互作用的数据集(其中的测试图在训练过程中完全不可见)。
GAT 的架构
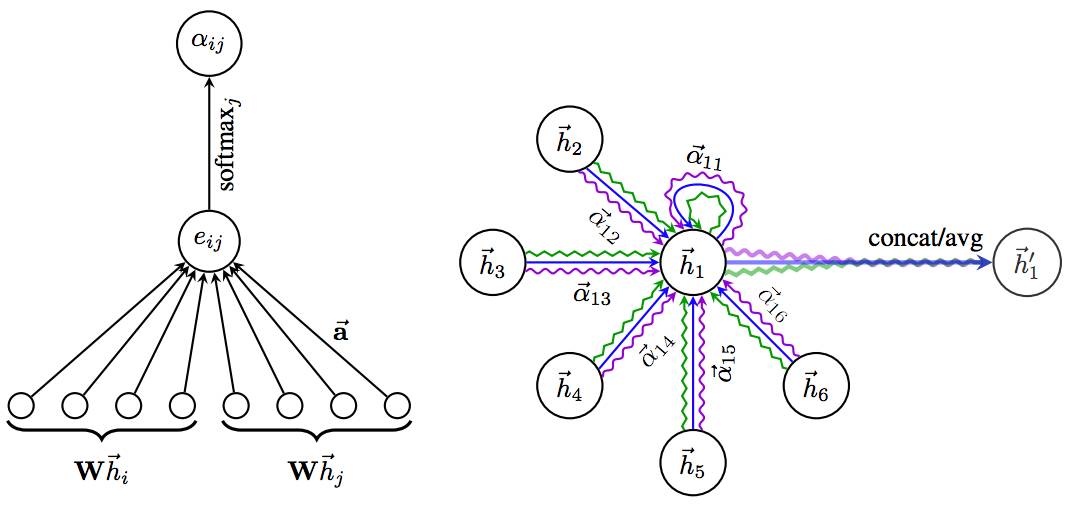
图 1. 左方:GAT 模型中应用的注意机制 a(W~hi ,W~hj ),通过一个权重向量参数化~a ∈ R^2F"。右方:节点 1 对其近邻节点的多头注意(其中 K=3 heads)。不同的箭头格式和颜色表示独立的注意计算。来自每个头的聚合特征连接或平均后得到 ~h1"。
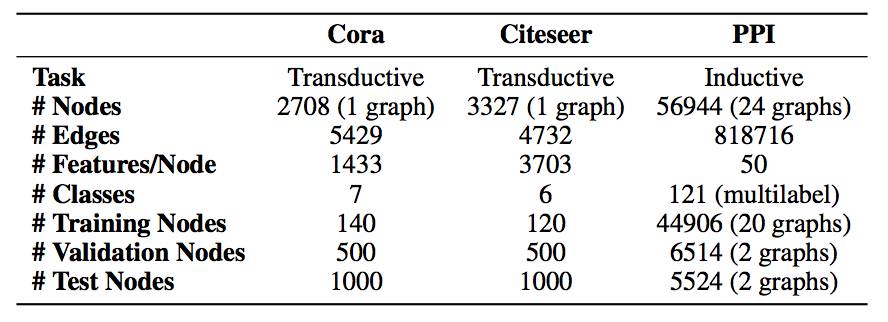
表 1:实验中使用的数据集。
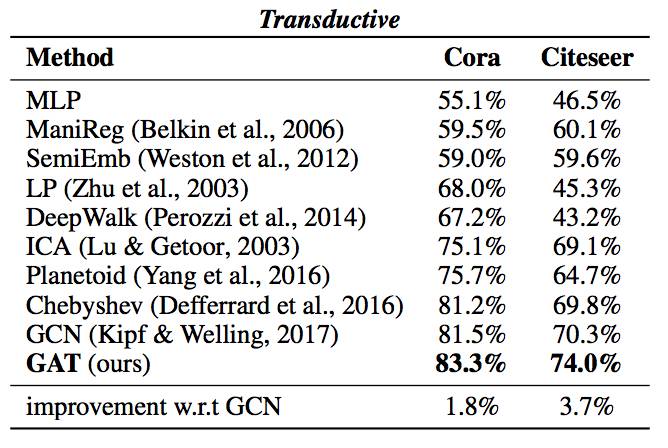
表 2:对 Cora 和 Citeseer 数据集的实验结果(分类准确度)的总结。

表 3:对 PPI 数据集的实验结果(微平均的 F1 分数)的总结。
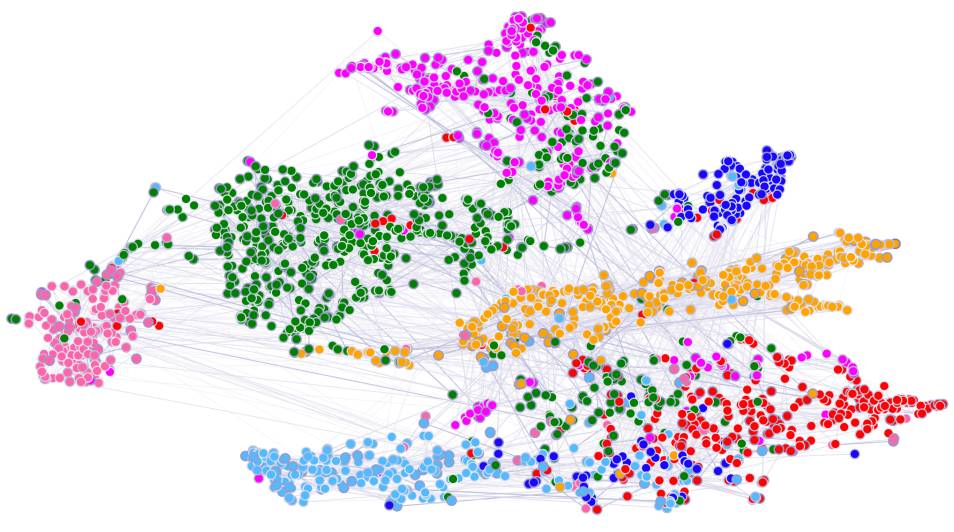
图 2. 在 Cora 数据集上对一个预训练的 GAT 模型的第一个隐藏层的计算特征表示的 t-SNE 图。节点颜色表示类别。边的粗细表示节点 i 和 j 之间的聚合归一化注意系数,由所有 8 个注意头计算得出:
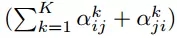 欢迎加入本站公开兴趣群
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4653.html
摘要:神经网络在自然语言处理方面,未来有巨大的应用潜力。讲座学者之一与深度学习大神蒙特利尔大学学者在大会上发表了论文,进一步展现神经机器翻译的研究结果。那些指令的语义就是习得的进入嵌入中,来较大化翻译质量,或者模型的对数似然函数。 在 8月7日在德国柏林召开的2016 计算语言学(ACL)大会上,学者Thang Luong、Kyunghyun Cho 和 Christopher D. Mannin...
摘要:另外,当损失函数接近全局最小时,概率会增加。降低训练过程中的学习率。对抗样本的训练据最近信息显示,神经网络很容易被对抗样本戏弄。使用高度正则化会有所帮助,但会影响判断不含噪声图像的准确性。 由 Yoshua Bengio、 Leon Bottou 等大神组成的讲师团奉献了 10 天精彩的讲座,剑桥大学自然语言处理与信息检索研究组副研究员 Marek Rei 参加了本次课程,在本文中,他精炼地...
摘要:深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。深度学习的概念由等人于年提出。但是自年以来,机器学习领域,取得了突破性的进展。 深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。深度学习是无监督学习的一种。 深度学习的概念源于人工神经网络的研究。含多隐层的多层感知...
摘要:八月初,我有幸有机会参加了蒙特利尔深度学习暑期学校的课程,由最知名的神经网络研究人员组成的为期天的讲座。另外,当损失函数接近全局最小时,概率会增加。降低训练过程中的学习率。对抗样本的训练据最近信息显示,神经网络很容易被对抗样本戏弄。 8月初的蒙特利尔深度学习暑期班,由Yoshua Bengio、 Leon Bottou等大神组成的讲师团奉献了10天精彩的讲座,剑桥大学自然语言处理与信息检索研...
摘要:因为深度学习的正统观念在该领域已经很流行了。在机器和深度学习空间中进行的大多数数学分析倾向于使用贝叶斯思想作为参数。如果我们接受了目前深度学习的主流观点任何一层的微分都是公平的,那么或许我们应该使用存储多种变体的复分析。 深度学习只能使用实数吗?本文简要介绍了近期一些将复数应用于深度学习的若干研究,并指出使用复数可以实现更鲁棒的层间梯度信息传播、更高的记忆容量、更准确的遗忘行为、大幅降低的网...

阅读 741·2021-09-30 09:47
阅读 2938·2021-09-04 16:40
阅读 916·2019-08-30 13:18
阅读 3494·2019-08-29 16:22
阅读 1612·2019-08-29 12:36
阅读 662·2019-08-29 11:11
阅读 1525·2019-08-26 13:47
阅读 1180·2019-08-26 13:32






