
摘要:亚马逊和华盛顿大学今天合作发布了开源的端到端深度学习编译器。项目作者之一陈天奇在微博上这样介绍这个编译器我们今天发布了基于工具链的深度学习编译器。陈天奇团队对的性能进行了基准测试,并与进行了比较。
亚马逊和华盛顿大学今天合作发布了开源的端到端深度学习编译器NNVM compiler。
先提醒一句,NNVM compiler ≠ NNVM。
NNVM是华盛顿大学博士陈天奇等人2016年发布的模块化深度学习系统,今年8月中旬,他们又推出了将深度学习工作负载部署到硬件的端到端IR堆栈TVM,也就是把深度学习模型更简单地放到各种硬件上。
当时,陈天奇把TVM+NNVM描述为“深度学习到各种硬件的完整优化工具链”,而这次推出的NNVM compiler,是一个基于TVM工具链的编译器。
项目作者之一陈天奇在微博上这样介绍这个编译器:
我们今天发布了基于TVM工具链的深度学习编译器NNVM compiler。支持将包括mxnet,pytorch,caffe2, coreml等在内的深度学习模型编译部署到硬件上并提供多级别联合优化。速度更快,部署更加轻量级。 支持包括树莓派,服务器和各种移动式设备和cuda, opencl, metal, Javascript以及其它各种后端。 欢迎对于深度学习, 编译原理,高性能计算,硬件加速有兴趣的同学一起加入dmlc推动领导开源项目社区。
NNVM compiler对CoreML的支持,让开发者可以在非iOS设备上部署CoreML模型。
AI开发界的挑战
AWS AI首席科学家李沐(MXNet作者)在亚马逊博客撰文介绍称,推出这个编译器,是为了应对深度学习框架多样化为AI开发界带来的三个挑战:
一、对于算法的开发者来说,由于各AI框架的前端交互和后端实现之间都存在很多区别,换框架很麻烦,而开发和交付过程中可能会用到的框架不止一个。
比如说有的亚马逊AWS云服务用户,为了获得EC2上的加速性能,会想要把Caffe模型部署到MXNet上。
为了应对这个问题,之前Facebook和微软也联合发布了模型间转换工具ONNX。
二、框架的开发者需要维护多个后端,来保证自己的框架能适用于从手机芯片到数据中心GPU的各种硬件。
比如说MXNet,要支持英伟达GPU的cuDNN,还要支持英特尔CPU的MKLML。
三、从芯片供应商的角度来看,他们每新开发一款芯片都需要支持多个AI框架,每个框架表示和执行工作负载的方式都不一样,所以,就连卷积这样一个运算,都需要用不同的方式来定义。
支持多个框架,就代表要完成巨大的工作量。
通过将框架中的深度学习模型直接部署到硬件,NNVM compiler自然也就解决了这些问题。
结构
NNVM compiler可以将前端框架中的工作负载直接编译到硬件后端,能在高层图中间表示(IR)中表示和优化普通的深度学习工作负载,也能为不同的硬件后端转换计算图、最小化内存占用、优化数据分布、融合计算模式。
编译器的典型工作流如下图所示:

这个编译器基于此前发布的TVM堆栈中的两个组件:NNVM用于计算图,TVM用于张量运算。
其中,NNVM的目标是将不同框架的工作负载表示为标准化计算图,然后将这些高级图转换为执行图。
TVM提供了一种独立于硬件的特定域语言,以简化张量索引层次中的运算符实现。另外,TVM还支持多线程、平铺、缓存等。
对框架和硬件的支持
编译器中的NNVM模块,支持下图所示的深度学习框架:
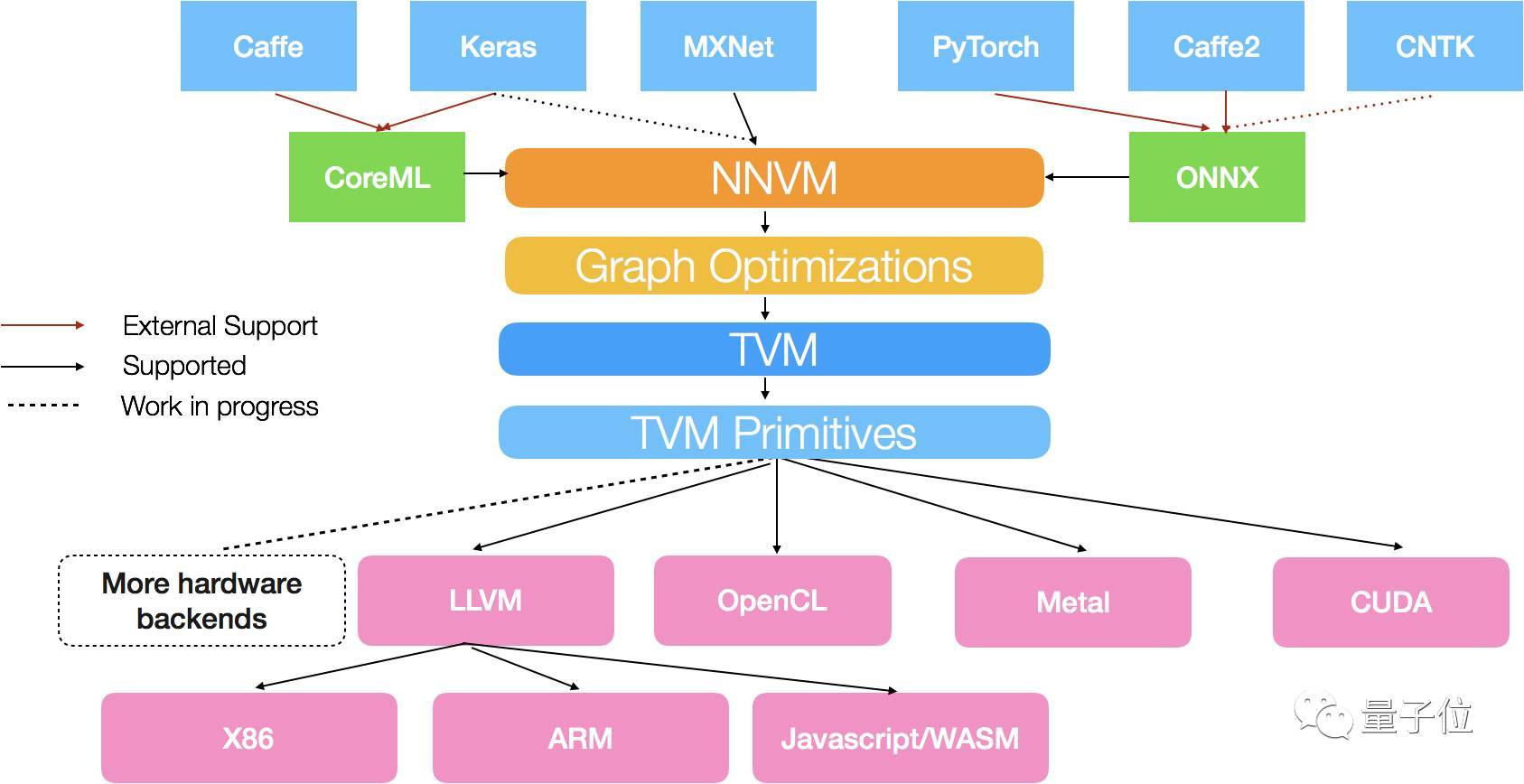
具体来说,MXNet的计算图能直接转换成NNVM图,对Keras计算图的直接支持也正在开发中。
同时,NNVM compiler还支持其他模型格式,比如说微软和Facebook前不久推出的ONNX,以及苹果CoreML。
通过支持ONNX,NNVM compiler支持Caffe2、PyTorch和CNTK框架;通过支持CoreML,这个编译器支持Caffe和Keras。
而编译器中的TVM模块,目前附带多个编码生成器,支持多种后端硬件,其中包括为X86和ARM架构的CPU生成LLVM IR,为各种GPU输出CUDA、OpenCL和Metal kernel。
性能

NNVM compiler联合使用图级和张量级优化以获得较佳性能。常规的深度学习框架会将图优化与部署runtime进行打包,而NNVM编译器将优化与实际部署运行时分离。
采用这种方法,编译的模块只需要依赖于最小的TVM runtime,当部署在Raspberry Pi或移动设备上时,只占用大约300KB。
陈天奇团队对NNVM compiler的性能进行了基准测试,并与MXNet进行了比较。这个测试基于两种典型的硬件配置:树莓派上的ARM CPU和AWS上的Nvidia GPU。
Nvidia GPU
GPU的基准和时间表由Leyuan Wang(AWS/UCDavis)和Yuwei Hu(图森)提供。他们在Nvidia K80上对NNVM编译器和MXNet进行了比较,以CUDA8和CuDNN7作为后端。这是一个非常强的基线,因为MXNet开启了从CuDNN中选择较佳内核的自动调整功能。另外,他们还使用了MXNet中优化深度内核来优化MobileNet工作负载。
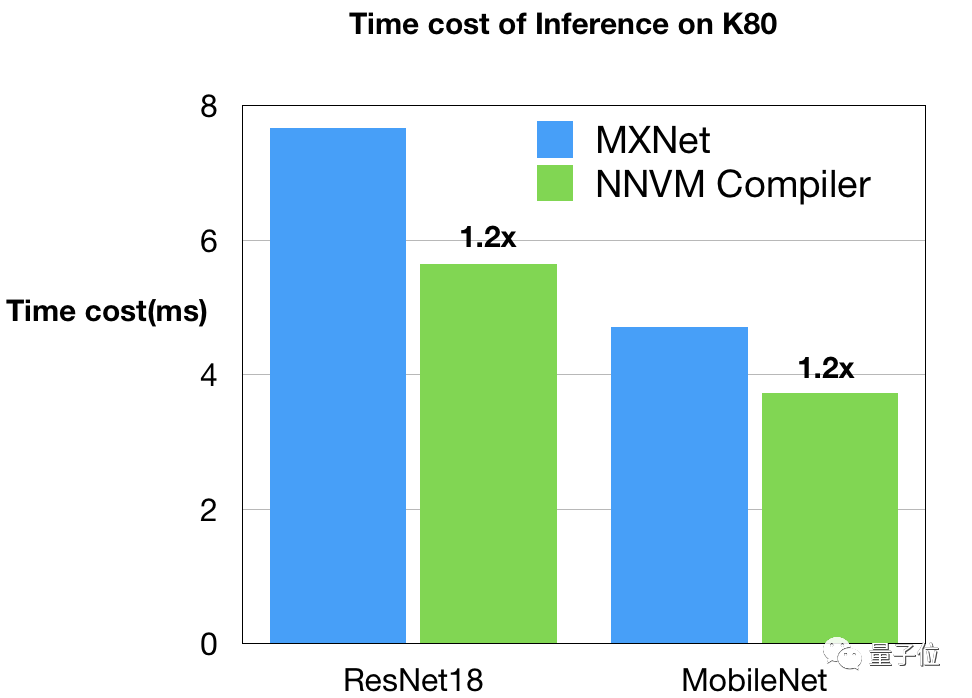
如图所见,NNVM编译器生成的代码在K80上优于MXNet。这些改进源于图和内核级别的优化。值得注意的是,NNVM编译器自己升恒所有的优化GPU内核,而不需要依赖诸如CuDNN这样的外部库。
树莓派3b
树莓派编译堆栈由Ziheng Jiang(AWS/FDU)提供。他们使用OpenBLAS和NNPack对NNVM和MXNet进行了比较,尝试不同的设置来获得MXNet的较佳表现,例如为3×3卷积在NNPack中开启Winograd卷积,启动多线程,并禁用了额外的调度程序(所有的线程都被NNPack使用)。
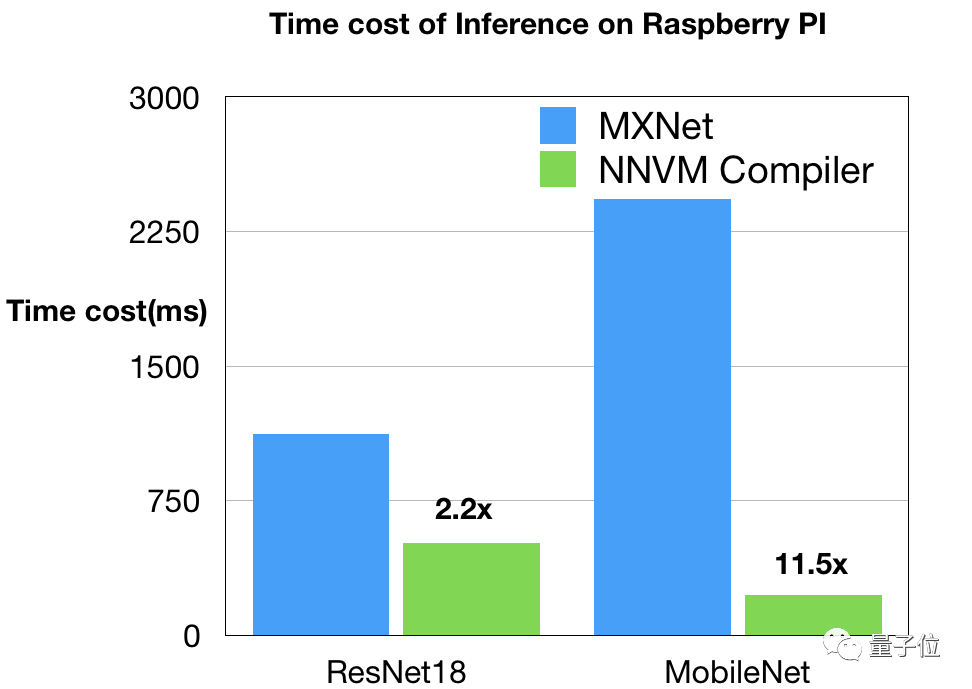
结果如上图所示,由NNVM编译器生成的代码在ResNet18上速度快两倍。MobileNet上的差距,主要是因为现有CPU DNN库中缺乏深度卷积。NNVM编译器受益于直接生成高效的ARM代码。
开发团队
NNVM编译器的GitHub地址:
https://github.com/dmlc/nnvm
开发这个项目的依然是TVM堆栈团队,包括华盛顿大学艾伦计算机学院的陈天奇、Thierry Moreau、Haichen Shen、Luis Ceze、Carlos Guestrin和Arvind Krishnamurthy,以及亚马逊AWS AI团队的Ziheng Jiang。
另外,在TVM博客最后还鸣谢了一群社区贡献者:
在这里特别感谢Yuwen Hu(图森)、Leyuan Wang(AWS/UCDavis)、Joshua Z. Zhang(AWS)以及Xingjian Shi(HKUST)的早期贡献。我们也要感谢所有的TVM堆栈贡献者。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4641.html
摘要:两者取长补短,所以深度学习框架在年,迎来了前后端开发的黄金时代。陈天奇在今年的中,总结了计算图优化的三个点依赖性剪枝分为前向传播剪枝,例已知,,求反向传播剪枝例,,求,根据用户的求解需求,可以剪掉没有求解的图分支。 虚拟框架杀入从发现问题到解决问题半年前的这时候,暑假,我在SIAT MMLAB实习。看着同事一会儿跑Torch,一会儿跑MXNet,一会儿跑Theano。SIAT的服务器一般是不...
摘要:是由华盛顿大学在读博士陈天奇等人提出的深度学习自动代码生成方法,去年月机器之心曾对其进行过简要介绍。目前的堆栈支持多种深度学习框架以及主流以及专用深度学习加速器。 TVM 是由华盛顿大学在读博士陈天奇等人提出的深度学习自动代码生成方法,去年 8 月机器之心曾对其进行过简要介绍。该技术能自动为大多数计算硬件生成可部署优化代码,其性能可与当前最优的供应商提供的优化计算库相比,且可以适应新型专用加...
摘要:在此,我们将借用和的算子,分析硬件加速的需求。池化层池化层主要用于尺度变换,提取高维特征。此种类型主要用于深度卷积神经网络中卷积部分与部分的连接。和可以认为是的特例。 NNVM是由陈天奇团队提出的一套可复用的计算流图中间表达层,它提供了一套精简的API函数,用以构建、表达和传输计算流图,从而便于高层级优化。另外NNVM也可以作为多个深度学习框架的共享编译器,可以优化、编译和部署在多种不同的硬...
摘要:所有需要跑任务的通过模版动态创建,当任务执行结束自动删除。同时也可以用配置完毕,可以点击按钮测试是否能够连接的到,如果显示则表示连接成功,配置没有问题。 介绍 基于Kubernetes和Jenkins来实现CI/CD。 所有需要跑任务的jenkins slave(pod)通过模版动态创建,当任务执行结束自动删除。 showImg(https://segmentfault.com/img...
摘要:系列安装报错结果一样的错解决方法成功了过拟合当你观察训练精度高但检测精度低很可能你遇到过度拟合问题。正如其名,它是的一个实现,作者为正在华盛顿大学研究机器学习的大牛陈天奇。为了方便大家使用,陈天奇将封装成了库。 xgboost系列 ubuntu14.04 安装 pip install xgboost 报错 sudo apt-get update 结果一样的错 解决方法: sudo -...

阅读 3404·2021-11-25 09:43
阅读 3236·2021-10-11 10:58
阅读 2820·2021-09-27 13:59
阅读 3129·2021-09-24 09:55
阅读 2218·2019-08-30 15:52
阅读 1883·2019-08-30 14:03
阅读 2295·2019-08-30 11:11
阅读 2066·2019-08-28 18:12






