
摘要:本图中的数据收集自利用数据集在英伟达上对进行训练的实际流程。据我所知,人们之前还无法有效利用诸如神威太湖之光的超级计算机完成神经网络训练。最终,我们用分钟完成了的训练据我们所知,这是使用进行训练的世界最快纪录。

图 1,Google Brain 科学家 Jonathan Hseu 阐述加速神经网络训练的重要意义
近年来,深度学习的一个瓶颈主要体现在计算上。比如,在一个英伟达的 M40 GPU 上用 ResNet50 去训练 ImageNet 需要 14 天;如果用一个串行程序在单核 CPU 上训练可能需要几十年才能完成。这个问题大大限制了科技的发展。为了设计新的模型,研究人员往往需要不断调整模型,再去做实验,每次实验结果都要等一天是无法接受的。所以,在半小时之内完成大型神经网络的训练对科技的进步意义重大,交互式研究能大大提高研发效率。
利用参数服务器实现的异构方法无法保证在大型系统之上稳定起效。而正如 Goyal 等人于 2017 年得出的结论,数据并行同步方法对于超大规模深度神经网络(简称 DNN)训练而言表现得更为稳定。其基本思路非常简单——在 SGD 中使用更大的 batch size,确保每一次迭代皆可被轻松分布至多处理器处。这里我们考虑以下理想条件。ResNet-50 在处理一张 225x225 像素图片时,需要进行 77.2 亿次单精度运算。如果我们为 ImageNet 数据集运行 90 epochs 的运算,则运算总量为 90x128 万 x77.2 亿(1018)。其实,现在世界上最快的计算机(中国的神威太湖之光)理论上可以每秒完成 2*10^17 个单精度浮点数计算。所以,如果我们有一个足够好的算法,允许我们充分利用这台超级计算机,应该能够在 5 秒内完成 ResNet-50 的训练。
为了实现这一目标,我们需要确保该算法能够使用更多处理器并在每次迭代时加载更多数据——也就是说,要在 SGD 采用更大的 batch size。这里我们用单一英伟达 M40 GPU 来假定单机器用例。在特定范围内,batch size 越大,则单一 GPU 的速度就越快(如图 2 所示)。其原因在于,低级矩阵计算库在这种情况下拥有更高的执行效率。在利用 ImageNet 训练 AlexNet 模型时,其中每 GPU 的最优批量大小为 512。如果我们希望使用大量 GPU 并保证每 GPU 皆拥有理想的执行效率,则应当将批量大小设定为 16 x 512 = 8192。
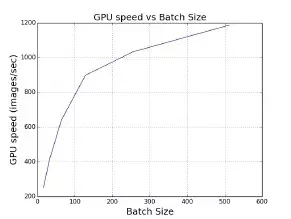
图 2,在特定范围内,批量处理方式能够显著提升系统性能(例如 GPU)。本图中的数据收集自利用 ImageNet 数据集在英伟达 M40 GPU 上对 AlexNet 进行训练的实际流程。其中 batch size 为每 GPU 512 时,处理速度最快;batch size 为每 GPU 1024 时会发生内存不足。
在理想情况下,如果我们固定数据整体访问量并根据处理器数量线性增加 batch size,每次迭代的 batch size 越大,所需要的迭代次数就越少。在增大 batch size 的同时,我们可以使用更多处理器以保持单次迭代时间基本维持恒定。如此一来,我们就可以获得线性加速比(如表 1 所示)。

表 1,comp 表示计算,comm 表示机器之间的通讯, t 表示单次迭代时间。只要我们在增大 batch size 的同时使用更多机器,就可以将迭代次数维持到基本恒定。这样总时间就能够以线性速度大大减少。
可惜,SGD 算法的 batch size 并不能无限制地增大。SGD 采用较大的 batch size 时,如果还是使用同样的 epochs 数量进行运算,则准确度往往低于 batch size 较小的场景 ; 而且目前还不存在特定算法方案能够帮助我们高效利用较大的 batch size。表 2 所示为基准测试下的目标准确度。举例来说,如果我们将 AlexNet 的 batch size 设置为 1024 以上或者将 ResNet-50 的 batch size 设置为 8192 以上,则准确度的测试结果将严重下降(如表 4 与图 3 所示)。
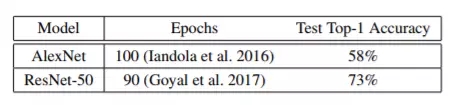
表 2,未配合数据增强情况下的 ImageNet 训练基准结果
对于大批量训练场景,我们需要确保使用较大的 batch size 训练能够在相同 epochs 前提下获得与较小的 batch size 相近的测试准确度。这里我们之所以保持 epochs 数量不变,是因为从统计学角度来讲,一个 epoch 代表着算法与整体数据集接触一次 ; 而从计算角度来讲,固定 epochs 数量意味着保证浮点运算次数不变。目前业界领先的大批量训练方案包含以下两种技术手段:
(1) 线性缩放(Krizhevsky 于 2014 年提出):如果我们将 batch size 由 B 增加至 kB,我们亦需要将学习率由η增加至 kη(其中 k 为倍数)。
(2) 预热模式(Goyal 等人于 2017 年提出):如果我们使用高学习率(η),则应以较小的η作为起点,而后在前几次 epochs 中逐步将其递增至较大η。
这里我们使用 B、η以及 I 来分别表示 batch size、学习率与迭代次数。如果我们将 batch size 由 B 增加到 kB,那么迭代次数将由 I 降低至 I/k。这意味着权重的更新频率减少为原本的 k 分之一。因此,我们可以通过将学习率提升 k 倍使每一次迭代的更新效率同样提升 k 倍。预热模式的目标在于避免算法在初始阶段因为使用基于线性缩放的高学习率而无法收敛。利用这些技术手段,研究人员们能够在特定范围之内使用相对较大的 batch size(如表 3 所示)。

表 3,业界领先的大批量训练方案与准确度测试结果
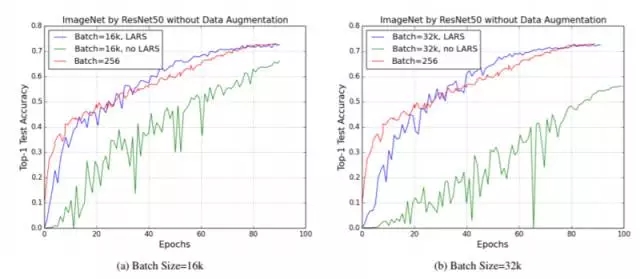
图 3:batch size 为 256 并配合 poly policy(乘方为 2)的基准学习率为 0.2。而在未使用 LARS 的版本中,我们使用业界领先的方法(由 Goyal 等人制定,2017 年):使用 5-epoch 进行预热并对 LR 进行线性扩展。对于使用 LARS 的版本,我们亦同样使用 5-epoch 进行预热。可以明显看到,现有方法无法处理 batch size 超过 8000 的任务;而 LARS 算法则能够配合 epoch 数量等同的基准确保大规模批量任务获得同样的准确度。
然而,我们亦观察到目前业界领先的各类方案的 batch szie 区间仍然比较有限,其中 AlexNet 为 1024,而 ResNet-50 为 8192。如果我们在 AlexNet 模型训练当中将 batch size 增加至 4096,则 100 epochs 情况下的准确度仅能达到 53.1%(如表 4 所示)。我们的目标是在使用更大 batch size 的情况下至少达到 58% 的准确度。
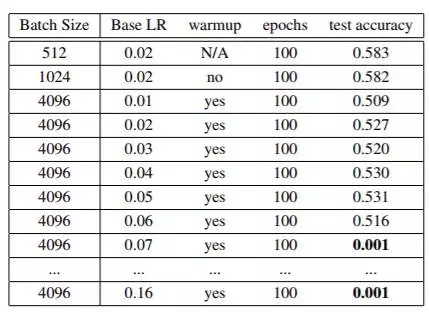
表 4,现有方法(线性缩放 + 预热)对于 batch size 大于 1024 的 AlexNet 无法正常工作。我们将预热时间从 0 调整到 10epoch,并从中选择较高准确度。基于线性缩放方法,当 batch size 为 4096 时,最优学习率(LR)应为 0.16。
据我所知,人们之前还无法有效利用诸如神威太湖之光的超级计算机完成神经网络训练。正如姚期智教授所说的那样,AI 的突破口在算法。这个问题的瓶颈就在算法层。我们有足够的计算能力,却无法充分利用。
为了解决大批量训练的准确度问题,我们设计了 LARS 算法(https://arxiv.org/pdf/1708.03888.pdf),允许我们将 AlexNet 的 batch size 提升到 32k(原来只有 1024),将 ResNet50 的 batch size 也提高到 32k。一旦我们完成了 batch size 的提升,用超级计算机加速神经网络就变得非常简单了。
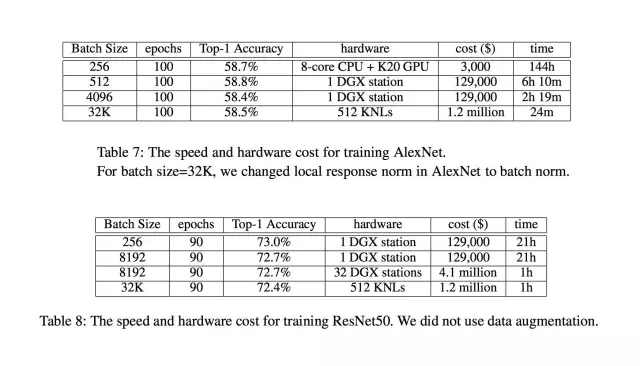
只需把数据均分到各个机器上,每次迭代完成一次对所有机器上参数的均值操作即可。最终,我们用 24 分钟完成了 AlexNet 的训练(据我们所知,这是使用 AlexaNet 进行 ImageNet 训练的世界最快纪录)。从下面的两个图表可以看出,我们同样可以在一小时内完成 ResNet-50 的训练。由于 LARS 使我们得以把 batch size 扩展到了 32k,我们可以使用更为廉价的芯片进行计算。我们选择了 Intel KNL(其实就是一种高端 CPU),最终总共用了 512 个 KNL,按照市场价的花费是 120 万美金,远远低于之前 Facebook 的 410 万美金 (32 台 NVIDIA DGX station)。正是大的 batch size 使我们大大降低了成本。
LARS 算法目前已经被用在 NVIDIA Caffe 和 Google Tensorflow 之中,NVIDIA Caffe 的 LARS 实现版本已经开源。当然,如果用更大的超级计算机,训练时间还会进一步缩短。
其实一年前,吴恩达教授在国际超算大会上 (ISC2016) 演讲时就预言,超级计算机将来对 AI 会非常重要。笔者认为,如果算法的扩展性足够好,超级计算机可以很快完成神经网络训练。那么,神经网络对单机 server 的需求可能会下降。相反,人们可能会去买超算中心的 computational hour。这样,普通人也可以廉价地用上 1000 台机器。并且超算中心会把这些机器维护好,普通用户不需要自己浪费大量的时间去管理机器和系统软件。当然这对 Intel 和 NVIDIA 的芯片厂家是没有影响的,因为他们可以将芯片大批量卖给超算中心。
作者介绍:尤洋,UC Berkeley 计算机科学博士在读,LARS 算法开发者之一。
http://www.cs.berkeley.edu/~youyang/
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4633.html
摘要:年月,腾讯机智机器学习平台团队在数据集上仅用分钟就训练好,创造了训练世界纪录。训练期间采用预定的批量变化方案。如此,我们也不难理解腾讯之后提出的层级的思想了。你可能觉得这对于索尼大法而言不算什么,但考虑到维护成本和占地,这就很不经济了。 随着技术、算力的发展,在 ImageNet 上训练 ResNet-50 的速度被不断刷新。2018 年 7 月,腾讯机智机器学习平台团队在 ImageNet...
摘要:最近,富士通实验室的一项研究刷新了一项纪录论文地址这项研究在秒内完成了上训练网络,使用个,准确率为,刷新了此前谷歌分钟的记录。准确性改良这部分采用了通常用于深度学习优化器的随机梯度下降。使用,我们的训练结果在秒内训练完,验证精度达到。 在过去两年中,深度学习的速度加速了 30 倍。但是人们还是对 快速执行机器学习算法 有着强烈的需求。Large mini-batch 分布式深度学习是满足需求...
摘要:在飞车类游戏中,开始状态和结束状态的标志如图所示。动作设计我们目前在设计飞车类游戏动作时,使用离散的动作,包括三种动作左转右转和。图训练过程中激励的趋势图总结本文介绍了如何使用在分钟内让玩飞车类游戏。 作者:WeTest小编商业转载请联系腾讯WeTest获得授权,非商业转载请注明出处。原文链接:https://wetest.qq.com/lab/view/440.html WeTest...

阅读 2148·2023-04-25 19:03
阅读 1306·2021-10-14 09:42
阅读 3507·2021-09-22 15:16
阅读 1058·2021-09-10 10:51
阅读 1724·2021-09-06 15:00
阅读 2462·2019-08-30 15:55
阅读 533·2019-08-29 16:22
阅读 937·2019-08-26 13:49




