
摘要:耶路撒冷希伯来大学的计算机与神经科学家提出了一项名为信息瓶颈的新理论,有望最终打开深度学习的黑箱,以及解释人脑的工作原理。
耶路撒冷希伯来大学的计算机与神经科学家 Naftali Tishby 提出了一项名为「信息瓶颈」(Information Bottleneck)的新理论,有望最终打开深度学习的黑箱,以及解释人脑的工作原理。这一想法是指神经网络就像把信息挤进瓶颈一样,只留下与一般概念更为相关的特征,去掉大量无关的噪音数据。深度学习先驱 Geoffrey Hinton 则在发给 Tishby 的邮件中评价道:「信息瓶颈极其有趣,估计要再听 10000 遍才能真正理解它,当今能听到如此原创的想法非常难得,或许它就是解开谜题的那把钥匙。」

一个称为「信息瓶颈」的新想法有助于解释当今人工智能算法的黑箱问题——以及人类大脑的工作原理。
如今「深度神经网络」已经学会对话、驾驶汽车、打视频游戏、玩围棋、绘画并辅助科研,这使其人类构建者很是困惑,并为深度学习算法的成果深感意外。这些学习系统的设计并没有一条明确的原则,除了来自大脑神经元的灵感(其实并没有人知道大脑是如何工作的),并且 DNN 早就和大脑神经元的原理相去甚远。
像大脑一样,深度神经网络具有神经元层——这些人工神经元构成了计算机的记忆。当一个神经元激活,它向连接到下一层的神经元发送信号。在深度学习中,网络连接按需强化或弱化(加权连接)从而更好地把来自输入数据的信号——比如,一张狗的图像像素点——发送到与高级概念(比如狗)相关联的神经元。当深度神经网络学习数以千计的狗的样本图像之后,它可像人一样较精确地从新图像中辨识出狗。这一魔术般的学习能力使其具备了可像人一样推理、创造进而拥有智能的基础。专家好奇深度学习是如何做到这一点的,并在何种程度上与人脑理解世界的方式相同。
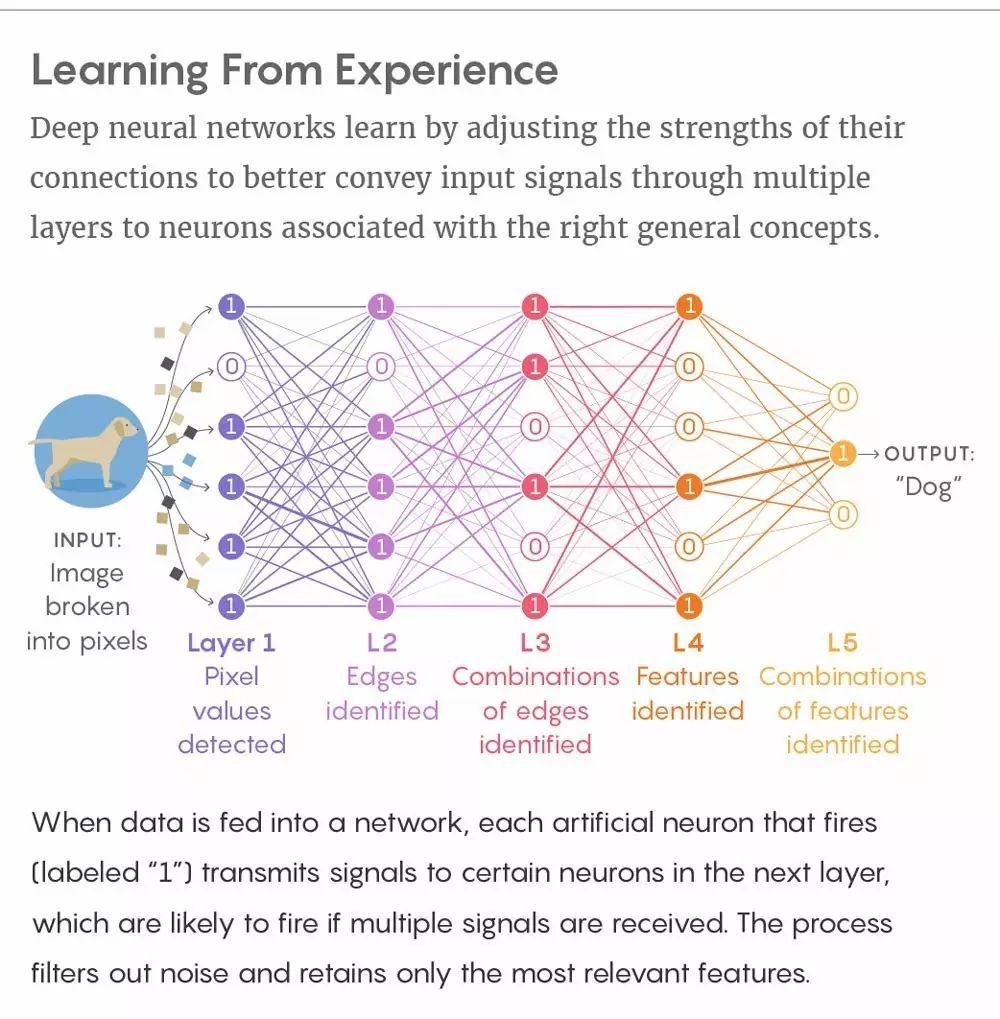
从经验中学习。深度神经网络通过调节连接权重以更好地传递输入信号,信号经过隐藏层,最终到达与正确概念相关联的神经元。当数据输入到神经网络,激活的每一个神经元(被标注为 1)把信号传递到下一层的特定神经元(如果接受到多个信号则很可能被激活)。这一过程会过滤掉噪声并只保留最相关的特征。
上月,一个在人工智能研究者之间广泛流传的柏林会议 YouTube 视频给出了黑箱可能的答案。会议中来自耶路撒冷希伯来大学的计算机与神经科学家 Naftali Tishby 为一项解释深度学习工作原理的新理论提供了证据。Tishby 论证道深度神经网络依据被称作「信息瓶颈」的步骤学习,这一术语其与另外两名合作者早在 1999 年就已提出。这一想法是指神经网络就像把信息挤进瓶颈一样,只留下与一般概念更为相关的特征,去掉大量无关的噪音数据。由 Tishby 及其学生 Ravid Shwartz-Ziv 联合进行的引人注目的实验揭示了发生在深度学习之中的挤压过程,至少在他们研究案例中是这样。Tishby 的发现在人工智能社区中引发了躁动。谷歌研究员 Alex Alemi 说:「我认为信息瓶颈对未来的深度神经网络研究很重要。我甚至发明了新的近似方法,从而把信息瓶颈分析应用到大型深度神经网络中。」他又说:「信息瓶颈不仅可以作为理论工具用来理解神经网络的工作原理,同样也可以作为构建网络架构和新目标函数的工具。」
一些研究者则仍怀疑该方法是否彻底解释了深度学习的成功,但是 Kyle Cranmer——一名来自纽约大学粒子物理学家,他曾使用机器学习分析了大量强子对撞机中的粒子对撞——则认为信息瓶颈作为一般性的学习原理,「多少还是正确的」。
深度学习先驱 Geoffrey Hinton 在柏林会议之后给 Tishby 发了邮件:「信息瓶颈极其有趣,估计要再听 10000 遍才能真正理解它,当今能听到如此原创的想法非常难得,或许它就是解开谜题的那把钥匙。」
据 Tishby 所讲,信息瓶颈是一个根本性的学习原则,不管是算法、家蝇、有意识的存在还是突发事件的物理计算。我们期待已久的答案即是「学习的关键恰恰是遗忘。」
瓶颈
Tishby 大概是在其他的研究者开始搞深度神经网络之时开始构思信息瓶颈的。那是 1980 年代,Tishby 在思考人类在语音识别上的极限是什么,当时这对人工智能来说是一个巨大的挑战。Tishby 意识到问题的关键是相关性:口头语言更为相关的特征是什么?我们如何从与之相随的变量中(口音、语调等)将其提取出来?一般来讲,当面对现实世界的海量数据之时,我们会保留哪些信号?

希伯来大学计算机科学教授 Naftali Tishby
「相关性的理念在历史上多有提及,但从未得到正确的阐述;从香农本人有误差的概念开始,多年来人们并不认为信息论是阐述相关性的正确方式。」Tishby 在上月的采访中说。
信息论的建立者香农通过抽象思考在一定意义上解放了始于 1940 年代的信息研究——1 和 0 只具有纯粹的数学意义。正如 Tishby 所说,香农认为信息与语义学无关,但是 Tishby 并不认同。借助信息论,Tishby 意识到可以较精确地定义相关性。
假设 X 是一个复杂的数据集,比如狗的图像像素,Y 是一个被这些数据表征的较简单的变量,比如单词「狗」。通过尽可能地压缩 X 而又不失去预测 Y 的能力,我们在关于 Y 的 X 中可以捕获所有的相关性信息。在 1999 年的论文中,Tishby 与联合作者 Fernando Pereira(现在谷歌)、William Bialek(现在普林斯顿大学)共同将这个概念阐述为一个数学优化问题。这是一个没有潜在黑箱问题的基本思想。
Tishby 说:「30 年来我在不同的环境下一直思考它,我的庆幸是深度神经网络变的如此重要。」
眼球长在脸上,脸长在人身上,人处于场景中
尽管这一隐藏在深度神经网络后面的概念已经讨论了几十年,但是它们在语音识别、图像识别等任务中的表现在 2010 年代才出现较大的发展,这和优化的训练机制、更强大的计算机处理器息息相关。2014 年,Tishby 阅读了物理学家 David Schwab 和 Pankaj Mehta 的论文《An exact mapping between the Variational Renormalization Group and Deep Learning》(变分重整化和深度学习之间的映射关系),认识到他们与信息瓶颈原则的潜在联系。
Schwab 和 Mehta 发现 Hinton 发明的深度学习算法「深度信念网络」在特定的情况下和重整化(renormalization)一样,重整化是一种通过粗粒化物理系统的细节、计算全局状态从而简化该系统的技术。二人将深度信念网络应用到分形(在不同的尺度上有自相似性)临界磁化系统模型中时,他们发现网络将自动使用一种类似重整化的过程寻找模型的状态。这令人印象深刻,正如生物物理学家所说,「统计物理学中的提取相关特征和深度学习中的提取相关特征不只是相似的词,它们的含义也是一样的。」
的问题是,现实世界一般而言不是分形的(fractal)。「自然世界并不是耳朵长在耳朵再长在耳朵上;而是眼球长在脸上,脸长在人身上,人处于场景中,」Cranmer 说,「因此我不会说,深度学习网络处理自然图像很优秀是因为其类似重整化的工作方式。」但是,Tishby 意识到,深度学习和粗粒化过程可以被包含于更广义的思维中。
![]()
Noga Zaslavsky(左)和 Ravid Shwartz-Ziv(右)作为 Naftali Tishby 的毕业生帮助建立了深度学习的信息瓶颈理论
在 2015 年,他和他的学生提出假设,(https://arxiv.org/abs/1503.02406)深度学习是一个信息瓶颈程序,尽可能的压缩数据噪声,保留数据想表达的信息。Tishby 和 Shwartz-Ziv 的新的深度神经网络实验揭示了瓶颈程序是如何工作的。在一个案例中,研究员训练小型网络使其将数据标记为 1 或 0(比如「狗」或「非狗」),网络一共有 282 个神经连接并随机初始化连接强度,然后他们使用 3000 个样本的输入数据集追踪网络究竟在做什么。
大多数深度学习网络训练过程中用来响应数据输入和调整神经连接强度的基本算法都是「随机梯度下降」:每当输入训练数据到网络中,一连串的激活行为将接连每一层的神经元。当信号到达最顶层时,最后的激活模式将对应确定的标签,1 或 0,「狗」或「非狗」。激活模式和正确的模式之间的不同将会「反向传播」回网络的层中,即,正如老师批改作业一样,这个算法将强化或者弱化每一个连接的强度以使网络能输出更产生的输出信号。经过训练之后,训练数据的一般模式将体现在神经连接的强度中,网络将变成识别数据的专家。
在他们的实验中,Tishby 和 Shwartz-Ziv 追踪了深度神经网络的每一层保留了多少输入数据的信息,以及每一层保留了多少输出标签的信息。他们发现,网络逐层收敛到了信息瓶颈的理论范围(Tishby 导出的理论极限)。Pereira 和 Bialek 最初的论文中展示了系统提取相关信息的较佳结果。在信息瓶颈的理论范围内,网络将尽可能地压缩输入,而无需牺牲较精确预测标签的能力。
Tishby 和 Shwartz-Ziv 还发现了一个很有趣的结果,深度学习以两个状态进行:一个短期「拟合」状态,期间网络学习标记输入数据,和一个时间长得多的长期「压缩」状态,通过测试其标记新测试数据的能力可以得出期间网络的泛化能力变得很强。

图片来自 arXiv:1703.00810
A. 初始状态:第一层的神经元编码输入数据的所有信息,包括其中的标签信息。较高层神经元处于几乎无序的状态,和输入数据或者其标签没有任何关联。
B. 拟合状态:深度学习刚开始的时候,高层神经元获得输入数据的信息,并逐渐学会匹配标签。
C. 状态变化:网络的层的状态突然发生变化,开始「遗忘」输入数据的信息。
D. 压缩状态:网络的高层压缩对输入数据的表示,保留与输出标签关联较大的表示,这些表示更擅长预测标签。
E. 最终状态:网络的较高层在准确率和压缩率之间取得平衡,只保留可以预测标签的信息。
当深度神经网络用随机梯度下降调整连接强度时,最初网络存储输入数据的比特数基本上保持常量或者增加很慢,期间连接强度被调整以编码输入模式,而网络标注数据的能力也在增长。一些专家将这个状态与记忆过程相比较。
然后,学习转向了压缩状态。网络开始对输入数据进行筛选,追踪最突出的特征(与输出标签关联最强)。这是因为在每一次迭代随机梯度下降时,训练数据中或多或少的偶然关联都驱使网络做不同的事情,使其神经连接变得或强或弱,随机游走。这种随机化现象和压缩输入数据的系统性表征有相同的效果。举一个例子,有些狗的图像背景中可能会有房子,而另一些没有。当网络被这些照片训练的时候,由于其它照片的抵消作用,在某些照片中它会「遗忘」房子和狗的关联。Tishby 和 Shwartz-Ziv 称,正是这种对细节的遗忘行为,使系统能生成一般概念。实际上,他们的实验揭示了,深度神经网络在压缩状态中提高泛化能力,从而更加擅长标记测试数据。(比如,被训练识别照片中的狗的深度神经网络,可以用包含或者不包含狗的照片进行测试。)
至于信息瓶颈是不是在所有深度学习中都存在,或者说有没有除了压缩以外的其它泛化方式,还有待近进一步考察。有些 AI 专家评价 Tishby 的想法是近来深度学习的重要理论洞察之一。哈佛大学的 AI 研究员和理论神经学家 Andrew Saxe 提出,大型深度神经网络并不需要冗长的压缩状态进行泛化。取而代之,研究员使用提前停止法(early stopping)以切断训练数据,防止网络对数据编码过多的关联。
Tishby 论证道 Saxe 和其同事分析的神经网络模型不同于标准的深度神经网络架构,但尽管如此,信息瓶颈理论范围比起其它方法更好地定义了这些网络的泛化能力。而在大型神经网络中是否存在信息瓶颈,Tishby 和 Shwartz-Ziv 最近的实验中部分涉及了这个问题,而在他们最初的文章中没有提过。他们在实验中通过包含 60,000 张图片的国家标准与技术局(National Institute of Standards and Technology)(http://yann.lecun.com/exdb/mnist/)的已完善数据集(被视为测量深度学习算法的基准)训练了 330,000 个连接的深度神经网络以识别手写体数字。他们观察到,网络中同样出现了收敛至信息瓶颈理论范围的行为,他们还观察到了深度学习中的两个确切的状态,其转换界限比起小型网络甚至更加锐利而明显。「我完全相信了,这是一个普遍现象。」Tishby 说道。
人类和机器
大脑从我们的感知中筛选信号并将其提升到我们的感知水平,这一奥秘促使 AI 先驱关注深度神经网络,他们希望逆向构造大脑的学习规则。然而,AI 从业者在技术进步中大部分放弃了这条路径,转而追寻与生物合理性几乎不相关的方法来提升性能。但是,由于他们的思考机器取得了很大的成绩,甚至引起「AI 可能威胁人类生存」的恐惧,很多研究者希望这些探索能够提供对学习和智能的洞察。

纽约大学心理学和数据科学助理教授 Brenden Lake 研究人类和机器学习方式的异同,他认为 Tishby 的研究成果是『打开神经网络黑箱的重要一步』,但是他强调大脑展示了一个更大、更黑的黑箱。成年人大脑包含 860 亿神经元之间的数百万亿连接,可能具备很多技巧来提升泛化,超越婴儿时期的基本图像识别和声音识别学习步骤,这些步骤可能在很多方面与深度学习类似。
比如,Lake 说根据他的研究,Tishby 确认的拟合和压缩词组看起来与孩子学习手写字的方式并不相同。孩子们并不需要看数千个字并经过一段时间的压缩心理表征,才能认识那个字,并学会写字。事实上,他们可以从单一样本中进行学习。Lake 及其同事制作的模型说明大脑可以将一个新的字解构成一系列笔画(先前存在的心理建构),使这个字的概念附加到先前知识之上。「并非像标准机器学习算法那样,把字的图像当作像素块,把概念当成特征映射进行学习。」Lake 解释道,「我的目的是构建该字的简单因果模型。」一种导致泛化的更短路径。
如此聪明的想法有助于人工智能社区增长经验,进一步加强两个领域的沟通。Tishby 相信信息瓶颈理论最终将会在两个学科发挥作用,即使它采取了一种在人类学习(而不是人工智能)中更普遍的形式。从该理论中,我们可以更好地理解哪些问题可被人类或人工智能解决。Tishby 说:「它给出了可以学习的问题的完整描述,在这些问题中我可以去除输入中的噪音而无损于我的分类能力。这是一个自然的视觉问题,语音识别。这也正是人脑可以应对的问题。」
同时,人类和人工神经网络很难解决每一个细节都很重要以及细微差别影响结果的问题。例如,大多数人无法快速心算两个大数字相乘的结果。「我们有一大堆这样的问题,对于变量的细微变化非常敏感的逻辑问题。」Tishby 说道。「分类问题、离散问题、加密问题。我不认为深度学习会帮助我们破解密码。」
泛化——测量信息瓶颈,或许意味着我们会丧失一些细节。这对于运行中的计算并不友好,但它并不是大脑的主要任务。我们在人群中找到熟悉的面孔,在复杂内容中找到规律,并在充满噪声的世界里提取有用的信息。
原文链接:https://www.quantamagazine.org/new-theory-cracks-open-the-black-box-of-deep-learning-20170921/
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4628.html
摘要:信息瓶颈理论由耶路撒冷希伯来大学的计算机与神经科学家等人提出。与我取得联系并分享了一篇已提交盲审的论文,论文作者对信息瓶颈理论的一些发现作了批判性分析。这是一个重要更新,指出了信息瓶颈理论的一些局限性。 「信息瓶颈」(Information Bottleneck)理论由耶路撒冷希伯来大学的计算机与神经科学家 Naftali Tishby 等人提出。该研究有望最终打开深度学习的黑箱,并解释人脑...
摘要:认为,深度神经网络根据一种被称为信息瓶颈的过程在学习,他和两位合作者最早在年对这一过程进行了纯理论方面的描述。另外一些研究人员则持怀疑态度,认为信息瓶颈理论不能完全解释深学习的成功。 利用深度神经网络的机器已经学会了交谈、开车,在玩视频游戏和下围棋时击败了世界冠军,还能做梦、画画,帮助进行科学发现,但同时它们也深深地让其发明者困惑,谁也没有料到所谓的深度学习算法能做得这么好。没有基本的原则指...
摘要:而这种举一反三的能力在机器学习领域同样适用,科学家将其称之为迁移学习。与深度学习相比,我们技术较大优点是具有可证明的性能保证。近几年的人工智能热潮中,深度学习是最主流的技术,以及之后的成功,更是使其几乎成为的代名词。 如今,人类将自己的未来放到了技术手里,无论是让人工智能更像人类思考的算法,还是让机器人大脑运转更快的芯片,都在向奇点靠近。谷歌工程总监、《奇点临近》的作者库兹韦尔认为,一旦智能...
摘要:但是在当时,几乎没有人看好深度学习的工作。年,与和共同撰写了,这本因封面被人们亲切地称为花书的深度学习奠基之作,也成为了人工智能领域不可不读的圣经级教材。在年底,开始为深度学习的产业孵化助力。 蒙特利尔大学计算机科学系教授 Yoshua Bengio从法国来到加拿大的时候,Yoshua Bengio只有12岁。他在加拿大度过了学生时代的大部分时光,在麦吉尔大学的校园中接受了从本科到博士的完整...

阅读 2727·2023-04-26 00:07
阅读 2471·2021-11-15 11:37
阅读 691·2021-10-19 11:44
阅读 2213·2021-09-22 15:56
阅读 1792·2021-09-10 10:50
阅读 1545·2021-08-18 10:21
阅读 2607·2019-08-30 15:53
阅读 1670·2019-08-30 11:11





