
摘要:损失代价的减小是一件好事只有在数据很庞大的时候在机器学习中,几乎任何时候都是,我们才需要使用,,迭代这些术语,在这种情况下,一次性将数据输入计算机是不可能的。
你肯定经历过这样的时刻,看着电脑屏幕抓着头,困惑着:「为什么我会在代码中使用这三个术语,它们有什么区别吗?」因为它们看起来实在太相似了。
为了理解这些术语有什么不同,你需要了解一些关于机器学习的术语,比如梯度下降,以帮助你理解。
这里简单总结梯度下降的含义...
梯度下降
这是一个在机器学习中用于寻找较佳结果(曲线的最小值)的迭代优化算法。
梯度的含义是斜率或者斜坡的倾斜度。
下降的含义是代价函数的下降。
算法是迭代的,意思是需要多次使用算法获取结果,以得到最优化结果。梯度下降的迭代性质能使欠拟合的图示演化以获得对数据的较佳拟合。

梯度下降中有一个称为学习率的参量。如上图左所示,刚开始学习率更大,因此下降步长更大。随着点下降,学习率变得越来越小,从而下降步长也变小。同时,代价函数也在减小,或者说代价在减小,有时候也称为损失函数或者损失,两者都是一样的。(损失/代价的减小是一件好事)
只有在数据很庞大的时候(在机器学习中,几乎任何时候都是),我们才需要使用 epochs,batch size,迭代这些术语,在这种情况下,一次性将数据输入计算机是不可能的。因此,为了解决这个问题,我们需要把数据分成小块,一块一块的传递给计算机,在每一步的末端更新神经网络的权重,拟合给定的数据。
EPOCHS
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一个 epoch。
然而,当一个 epoch 对于计算机而言太庞大的时候,就需要把它分成多个小块。
为什么要使用多于一个 epoch?
我知道这刚开始听起来会很奇怪,在神经网络中传递完整的数据集一次是不够的,而且我们需要将完整的数据集在同样的神经网络中传递多次。但是请记住,我们使用的是有限的数据集,并且我们使用一个迭代过程即梯度下降,优化学习过程和图示。因此仅仅更新权重一次或者说使用一个 epoch 是不够的。
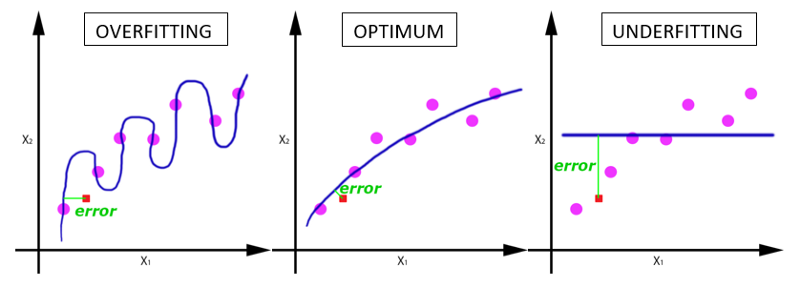
随着 epoch 数量增加,神经网络中的权重的更新次数也增加,曲线从欠拟合变得过拟合。
那么,几个 epoch 才是合适的呢?
不幸的是,这个问题并没有正确的答案。对于不同的数据集,答案是不一样的。但是数据的多样性会影响合适的 epoch 的数量。比如,只有黑色的猫的数据集,以及有各种颜色的猫的数据集。
BATCH SIZE
一个 batch 中的样本总数。记住:batch size 和 number of batches 是不同的。
BATCH 是什么?
在不能将数据一次性通过神经网络的时候,就需要将数据集分成几个 batch。
正如将这篇文章分成几个部分,如介绍、梯度下降、Epoch、Batch size 和迭代,从而使文章更容易阅读和理解。
迭代
理解迭代,只需要知道乘法表或者一个计算器就可以了。迭代是 batch 需要完成一个 epoch 的次数。记住:在一个 epoch 中,batch 数和迭代数是相等的。
比如对于一个有 2000 个训练样本的数据集。将 2000 个样本分成大小为 500 的 batch,那么完成一个 epoch 需要 4 个 iteration。
原文链接:https://medium.com/towards-data-science/epoch-vs-iterations-vs-batch-size-4dfb9c7ce9c9
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4624.html
摘要:本图中的数据收集自利用数据集在英伟达上对进行训练的实际流程。据我所知,人们之前还无法有效利用诸如神威太湖之光的超级计算机完成神经网络训练。最终,我们用分钟完成了的训练据我们所知,这是使用进行训练的世界最快纪录。 图 1,Google Brain 科学家 Jonathan Hseu 阐述加速神经网络训练的重要意义近年来,深度学习的一个瓶颈主要体现在计算上。比如,在一个英伟达的 M40 GPU ...
摘要:介绍本文我们将使用网络来学习莎士比亚小说,模型通过学习可以生成与小说风格相似的文本,如图所示虽然有些句子并没有实际的意思目前我们的模型是基于概率,并不是理解语义,但是大多数单词都是有效的,文本结构也与我们训练的文本相似。 介绍 本文我们将使用GRU网络来学习莎士比亚小说,模型通过学习可以生成与小说风格相似的文本,如图所示:showImg(https://segmentfault.com...
摘要:深度卷积对抗生成网络是的变体,是一种将卷积引入模型的网络。特点是判别器使用来替代空间池化,生成器使用反卷积使用稳定学习,有助于处理初始化不良导致的训练问题生成器输出层使用激活函数,其它层使用激活函数。 介绍 showImg(https://segmentfault.com/img/bVbkDEF?w=2572&h=1080); 如图所示,GAN网络会同时训练两个模型。生成器:负责生成数...

阅读 2953·2021-11-24 09:39
阅读 3550·2021-11-19 09:40
阅读 2394·2021-11-17 09:33
阅读 3874·2021-10-08 10:04
阅读 3183·2021-09-26 09:55
阅读 1830·2021-09-22 15:26
阅读 1084·2021-09-10 10:51
阅读 3281·2019-08-30 15:44




