
摘要:即便对于行家来说,调试神经网络也是一项艰巨的任务。神经网络对于所有失真应该具有不变性,你需要特别训练这一点。对于负数,会给出,这意味着函数没有激活。换句话说,神经元有一部分从未被使用过。这是因为增加更多的层会让网络的精度降低。
即便对于行家来说,调试神经网络也是一项艰巨的任务。数百万个参数挤在一起,一个微小的变化就能毁掉所有辛勤工作的成果。然而不进行调试以及可视化,一切就只能靠运气,最后可能浪费掉大把的青春岁月。
怎么办?这里是我总结的一些方法,希望对你有所帮助。
数据集问题
尝试用小数据集来过拟合你的模型
一般来说,几百次迭代后神经网络就会对数据过拟合。如果损失还不下降,那么问题可能就深了。
使用迭代逻辑来解决问题
先建立一个最小的网络来解决核心问题,然后一步一步扩展到全局问题。比方构建一个风格迁移网络,应该首先在一张图片上训练。成功之后,再构建一个可以对任意图片实现风格迁移的模型。
使用带有失真的平衡数据集
以训练模型进行数据分类为例,每一类的输入训练数据量应该一致。不然会出现某一类的过拟合。神经网络对于所有失真应该具有不变性,你需要特别训练这一点。所以输入一些失真数据,有助于提高网络的准确率。
网络容量与数据大小
数据集应该足以让网络完成学习。如果大网络配上小数据集,学习过程就会停止,有可能一大堆输入都得出同样的输出。如果小网络配上大数据集,你会遇见损失的跳跃,因为网络容量存储不了这么多信息。
使用平均中心化
这有助于从网络中去除噪音数据,并且提高训练效果,在某些情况下还有助于解决NaN问题。不过切记对于时间序列数据,应该使用批量中心化而不是全局。
神经网络问题
首先尝试简单的模型
我看到太多人一上来就尝试ResNet-50、VGG19等标准的大型网络,结果发现他们的问题其实只要几层网络就能解决。所以如果不是有什么恋大的情结,麻烦你从小型网络开始着手。
增加的东西越多,越难训练出一个解决问题的模型。从小网络开始训练,可以节省更多的时间。以及,大网络会占用更多的内存和运算。
必须可视化
如果用TensorFlow,那就必须用Tensorboard。否则,请为你的框架找到别的可视化工具,或者自己写一个。因为这有助于你在训练早期阶段发现问题。你应该明确的看到这些数据:损失、权重直方图、变量和梯度。
如果是处理计算机视觉方面的工作,始终要对过滤器进行可视化,这样才能清楚的了解网络正在看到的是什么内容。
权重初始化
如果不能正确的设置权重,你的网络可能会因为梯度消失等原因变得无法学习。以及你要知道权重和学习率互相结合,大学习率和大权重可能导致NaN问题。
对于小型网络,在1e-2~1e-3附近使用一些高斯分布初始化器就够了。
对于深层网络这没什么用,因为权重将相乘多次,这会带来非常小的数字,几乎可以消除反向传播那步的梯度。多亏了Ioffe和Szegedy,我们现在有了Batch-Normalization(批量归一化),这能减少好多麻烦。
标准问题使用标准网络
有很多你立马就能用的预训练模型。在某些情况下,你可以直接使用这些模型,也可以进行微调节省训练时间。核心思想是,对于不同的问题,大多数网络的容量是一样的。比方,搞计算机视觉,那么网络的第一层就是由简单的过滤器构成,例如线、点等等,所有的图片都是如此,根本不需要重新训练。
使用学习率衰减
这总能对你有所帮助。TensorFlow里面有很多可以用的衰减调度器。
使用网格搜索或随机搜索或配置文件来调整超参数
不要手动检查所有的参数,这样耗时而且低效。我通常对所有参数使用全局配置,检查运行结果之后,我回进一步研究改进的方向。如果这种方法没有帮助,那么你可以使用随机搜索或者网格搜索。
关于激活函数

1、关于梯度消失的问题
例如Sigmoid以及Tanh等激活函数存在饱和问题,也就是在函数的一端,激活函数的导数会趋近于零,这会“杀死”梯度和学习过程。所以换用不同的激活函数是个好主意。现在标准的激活函数是ReLU。
此外这个问题也可能出现在非常深或者循环网络中,例如对于一个150层的网络,所有的激活函数都给定为0.9,那么0.91⁵⁰ = 0,000000137。正如我上面提到的,批量归一化有助于解决这个问题。
2、非零中心激活函数
Sigmoid、ReLU都不是以零为中心的激活函数。这意味着在训练期间,所有的梯度都将是正(或者负)的,这会导致学习过程中出现问题。这也是为什么我们使用零中心化的输入数据。
3、无效ReLU
标准的ReLU函数也不完美。对于负数,ReLU会给出0,这意味着函数没有激活。换句话说,神经元有一部分从未被使用过。发生这种情况的原因,主要是使用了大学习率以及错误的权重初始化。如果参数调整不能帮你解决这个问题,可以尝试Leaky ReLU、PReLU、ELU或者Maxout等函数。
4、梯度爆炸
这个问题与梯度消失差不多,只不过是每一步梯度越来越大。一个解决的方案是使用梯度裁剪,也就是给梯度下了一个硬限制。
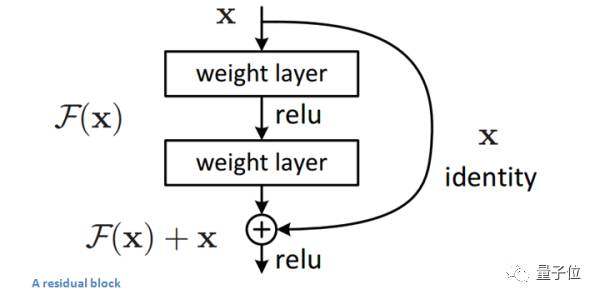
深层网络的网络精度退化
非常深层的网络有个问题,就是会从某些点开始表现就完全崩了。这是因为增加更多的层会让网络的精度降低。解决的办法是使用残差层,保证部分输入可以穿过所有层。残差网络如下图所示。
如果上述种种没有提到你遇见的问题,你可以联系作者进一步讨论,作者在推特上的ID是:creotiv。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4619.html
摘要:众所周知,利用本身内置的多人联网功能与高级应用程序接口可以实现创建多人工程。本次我们教大家的就是利用国内一个名叫的第三方插件工具来实现多人联网,实现过程十分简单且支持自定义拓展。具体教程如下新建游戏使用游戏云需要,通过官网创建游戏获取。 通常而言,对于不少开发人员而言,开发一款多人在线游戏通常是一件麻烦事,复杂的测试,繁琐的调试过程,还会时不时会出现一些几乎无法复现的BUG。另外,更让...
摘要:众所周知,利用本身内置的多人联网功能与高级应用程序接口可以实现创建多人工程。本次我们教大家的就是利用国内一个名叫的第三方插件工具来实现多人联网,实现过程十分简单且支持自定义拓展。具体教程如下新建游戏使用游戏云需要,通过官网创建游戏获取。 通常而言,对于不少开发人员而言,开发一款多人在线游戏通常是一件麻烦事,复杂的测试,繁琐的调试过程,还会时不时会出现一些几乎无法复现的BUG。另外,更让...
摘要:在生产环境里,这简直就是梦魇,因为没办法中止索引构建。最明智的建议是将索引构建当做某类数据库迁移来看待,确保应用程序的代码不会自动声明索引。索引的构建分为两步。如果发生在生产环境里,这无疑是很糟糕的,这也是长时间索引构建让人抓狂的原因。 声明索引时要小心 由于这个步骤太容易了,所以也很容易在无意间触发索引构建。如果数据集很大,构建会花很长时间。在生产环境里,这简直就是梦魇,因为没办法中...
摘要:背景背景大家都有学习如何规范简洁的编写代码,但却很少学习如何规范简洁的提交代码。背景 大家都有学习如何规范简洁的编写代码,但却很少学习如何规范简洁的提交代码。现在大家基本上都用 Git 作为源码管理的工具,Git 提供了极大的灵活性,我们按照各种 workflow 来提交/合并 code,这种灵活性把控不好,也会带来很多问题 最常见的问题就是乱成一团的 git log histo...

阅读 1588·2021-11-18 10:02
阅读 1774·2021-09-04 16:40
阅读 3229·2021-09-01 10:48
阅读 918·2019-08-30 15:55
阅读 1926·2019-08-30 15:55
阅读 1419·2019-08-30 13:05
阅读 3078·2019-08-30 12:52
阅读 1659·2019-08-30 11:24





