
摘要:谷歌也不例外,在大会中介绍了人工智能近期的发展及其对计算机系统设计的影响,同时他也对进行了详细介绍。表示,在谷歌产品中的应用已经超过了个月,用于搜索神经机器翻译的系统等。此外,学习优化更新规则也是自动机器学习趋势中的一个信号。
在刚刚结束的 2017 年国际高性能微处理器研讨会(Hot Chips 2017)上,微软、百度、英特尔等公司都发布了一系列硬件方面的新信息,比如微软的 Project Brainwave、百度的 XPU、英特尔的 14nm FPGA 解决方案等。谷歌也不例外,在大会 keynote 中 Jeff Dean 介绍了人工智能近期的发展及其对计算机系统设计的影响,同时他也对 TPU、TensorFlow 进行了详细介绍。文末提供了该演讲资料的下载地址。
在演讲中,Jeff Dean 首先介绍了深度学习的崛起(及其原因),谷歌在自动驾驶、医疗健康等领域取得的进展。
Jeff Dean 表示,随着深度学习的发展,我们需要更多的计算能力,而深度学习也正在改变我们设计计算机的能力。
我们知道,谷歌设计了 TPU 专门进行神经网络推断。Jeff Dean 表示,TPU 在谷歌产品中的应用已经超过了 30 个月,用于搜索、神经机器翻译、DeepMind 的 AlphaGo 系统等。
但部署人工智能不只是推断,还有训练阶段。TPU 能够助力推断,我们又该如何加速训练?训练的加速非常的重要:无论是对产品化还是对解决大量的难题。
为了同时加速神经网络的推断与训练,谷歌设计了 TPU 二代。TPU 二代芯片的性能如下图所示:
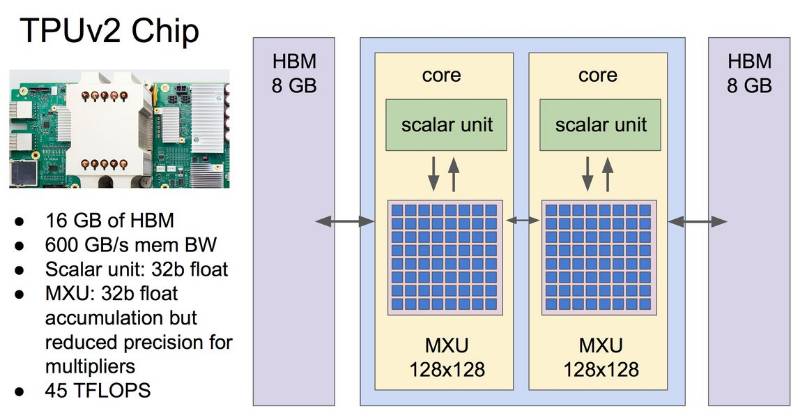
除了上图所述意外,TPU 二代的特点还有:
每秒的浮点运算是 180 teraflops,64 GB 的 HBM 存储,2400 GB/S 的存储带宽
设计上,TPU 二代可以组合连接成大型配置
下图是 TPU 组成的大型配置:由 64 块 TPU 二代组成,每秒 11.5 千万亿次浮点运算,4 太字节的 HBM 存储。

在拥有强大的硬件之后,我们需要更强大的深度学习框架来支持这些硬件和编程语言,因为快速增长的机器学习和深度学习需要硬件和软件都能具备强大的扩展能力。因此,Jeff Dean 还详细介绍了最开始由谷歌开发的深度学习框架 TensorFlow。
深度学习框架 TensorFlow

TensorFlow 是一种采用数据流图(data flow graphs),用于数值计算的开源软件库。其中 Tensor 代表传递的数据为张量(多维数组),Flow 代表使用计算图进行运算。数据流图用「节点」(nodes)和「边」(edges)组成的有向图来描述数学运算。
TensorFlow 的目标是建立一个可以表达和分享机器学习观点与系统的公共平台。该平台是开源的,所以它不仅是谷歌的平台,同时是所有机器学习开发者和研究人员的平台,谷歌和所有机器学习开源社区的研究者都在努力使 TensorFlow 成为研究和产品上较好的机器学习平台。
下面是 TensorFlow 项目近年来在 Github 上的关注度,我们可以看到 TensorFlow 是所有同类深度学习框架中关注度较大的项目。
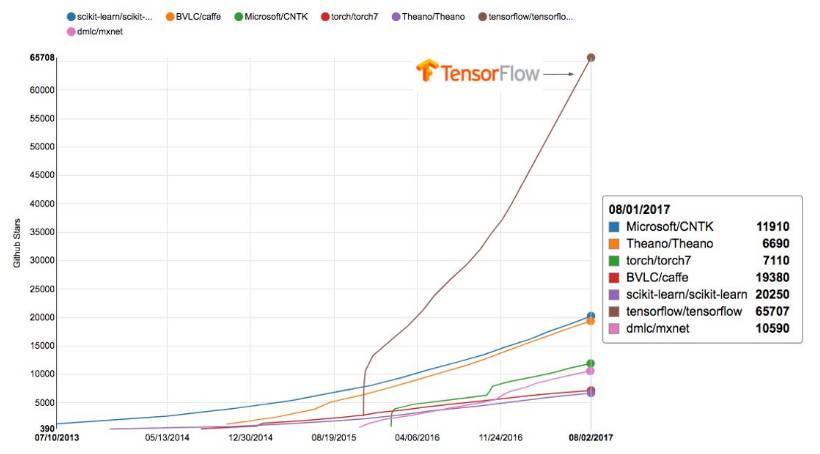
TensorFlow:一个充满活力的开源社区
TensorFlow 发展迅速,有很多谷歌外部的开发人员
超过 800 多位 TensorFlow 开发人员(非谷歌人员)。
21 个月内 Github 上有超过 21000 多条贡献和修改。
许多社区编写了 TensorFlow 的教程、模型、翻译和项目
超过 16000 个 Github 项目在项目名中包含了「TensorFlow」字段
社区与 TensorFlow 团队之间的直接联合
5000+已回答的 Stack Overflow 问题
80+ 每周解答的社区提交的 GitHub 问题
通过 TensorFlow 编程
在 TensorFlow 中,一个模型可能只需要一点点修改就能在 CPU、GPU 或 TPU 上运行。前面我们已经看到 TPU 的强大之处,Jeff Dean 表明,对于从事开放性机器学习研究的科学家,谷歌可以免费提供 1000 块云 TPU 来支持他们的研究。Jeff Dean 说:「我们很高兴研究者能在更强劲的计算力下进行更杰出的研究」
TensorFlow Research Cloud 申请地址:https://services.google.com/fb/forms/tpusignup/
机器学习需要在各种环境中运行,我们可以在下面看到 TensorFlow 所支持的各种平台和编程语言。

除此之外,TensorFlow 还支持各种编程语言,如 Python、C++、Java、C#、R、Go 等。
TensorFlow 非常重要的一点就是计算图,我们一般需要先定义整个模型需要的计算图,然后再执行计算图进行运算。在计算图中,「节点」一般用来表示施加的数学操作,但也可以表示数据输入的起点和输出的终点,或者是读取/写入持久变量(persistent variable)的终点。边表示节点之间的输入/输出关系。这些数据边可以传送维度可动态调整的多维数据数组,即张量(tensor)。
如下是使用 TensorFlow 和 Python 代码定义一个计算图:
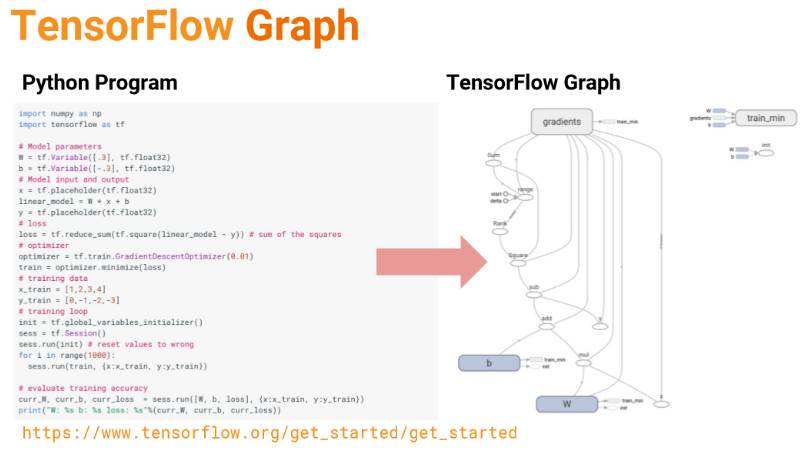
在 Tensorflow 中,所有不同的变量和运算都储存在计算图。所以在我们构建完模型所需要的图之后,还需要打开一个会话(Session)来运行整个计算图。在会话中,我们可以将所有计算分配到可用的 CPU 和 GPU 资源中。
如下所示代码,我们声明两个常量 a 和 b,并且定义一个加法运算。但它并不会输出计算结果,因为我们只是定义了一张图,而没有运行它:
a=tf.constant([1,2],name="a")
b=tf.constant([2,4],name="b")
result = a+b
print(result)
#输出:Tensor("add:0", shape=(2,), dtype=int32)
下面的代码才会输出计算结果,因为我们需要创建一个会话才能管理 TensorFlow 运行时的所有资源。但计算完毕后需要关闭会话来帮助系统回收资源,不然就会出现资源泄漏的问题。下面提供了使用会话的两种方式:
a=tf.constant([1,2,3,4])
b=tf.constant([1,2,3,4])
result=a+b
sess=tf.Session()
print(sess.run(result))
sess.close
#输出 [2 4 6 8]
with tf.Session() as sess:
a=tf.constant([1,2,3,4])
b=tf.constant([1,2,3,4])
result=a+b
print(sess.run(result))
#输出 [2 4 6 8]
TensorFlow + XLA 编译器

XLA(Accelerated Linear Algebra)是一种特定领域的编译器,它极好地支持线性代数,所以能很大程度地优化 TensorFlow 的计算。使用 XLA 编译器,TensorFlow 的运算将在速度、内存使用和概率计算上得到大幅度提升。
XLA 编译器详细介绍: https://www.tensorflow.org/performance/xla/
XLA 编译器开源代码: https://github.com/tensorflow/tensorflow/tree/master/tensorflow/compiler

TensorFlow 的优势
高性能机器学习模型
对于大型模型来说,模型并行化处理是极其重要的,因为单个模型的训练时间太长以至于我们很难对这些模型进行反复的修改。因此,在多个计算设备中处理模型并取得优秀的性能就十分重要了。如下所示,我们可以将模型分割为四部分,运行在四个 GPU 上。

高性能强化学习模型
通过强化学习训练的 Placement 模型将图(graph)作为输入,并且将一组设备、输出设备作为图中的节点。在 Runtime 中,给定强化学习的奖励信号而度量每一步的时间,然后再更新 Placement。
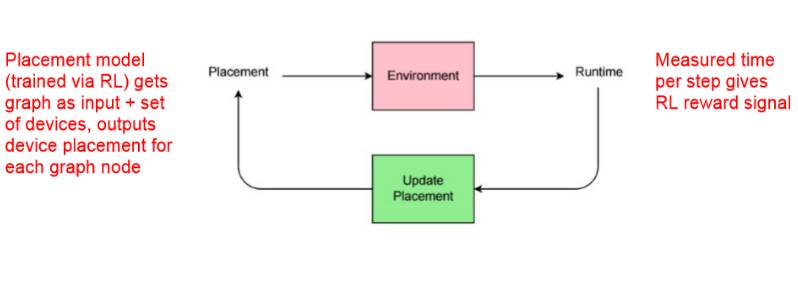
通过强化学习优化设备部署(Device Placement Optimization with Reinforcement Learning,ICML 2017)
论文地址:https://arxiv.org/abs/1706.04972
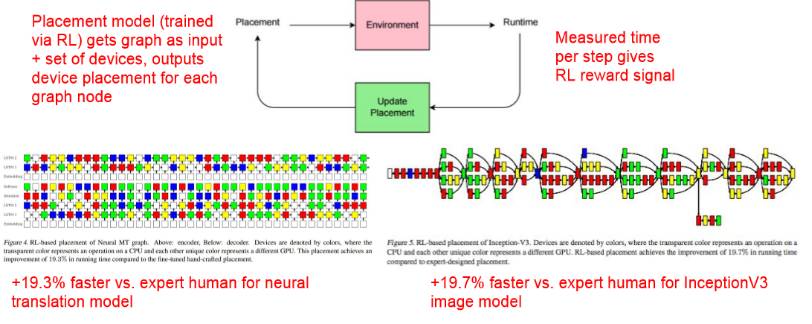
通过强化学习优化设备部署
降低推断成本
开发人员最怕的就是「我们有十分优秀的模型,但它却需要太多的计算资源而不能部署到边缘设备中!」
Geoffrey Hinton 和 Jeff Dean 等人曾发表过论文 Distilling the Knowledge in a Neural Network。在该篇论文中,他们详细探讨了将知识压缩到一个集成的单一模型中,因此能使用不同的压缩方法将复杂模型部署到低计算能力的设备中。他们表示这种方法显著地提升了商业声学模型部署的性能。
论文地址:https://arxiv.org/abs/1503.02531
这种集成方法实现成一个从输入到输出的映射函数。我们会忽略集成中的模型和参数化的方式而只关注于这个函数。以下是 Jeff Dean 介绍这种集成。

训练模型的几个趋势
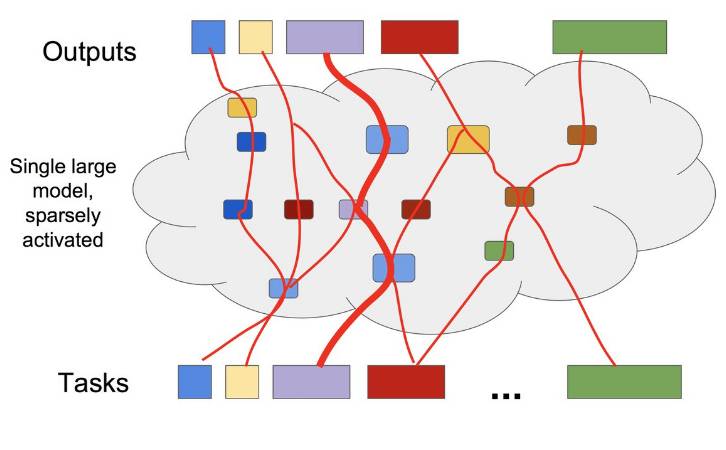
1. 大型、稀疏激活式模型
之所以想要训练这种模型是想要面向大型数据集的大型模型容量,但同时也想要单个样本只激活大型模型的一小部分。
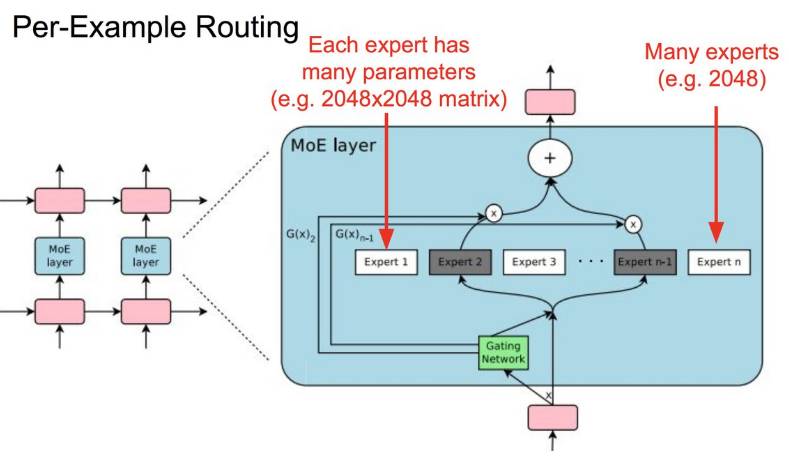
逐个样本路径选择图
这里,可参考谷歌 Google Brain ICLR 2017 论文《OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER》。
2. 自动机器学习
Jeff Dean 介绍说,目前的解决方式是:机器学习专家+数据+计算。这种解决方案人力的介入非常大。我们能不能把解决方案变成:数据+100 倍的计算。
有多个信号让我们看到,这种方式是可行的:
基于强化学习的架构搜索学习如何优化
如 Google Brain ICLR 2017 论文《Neural Architecture Search with Reinforcement Learning》,其思路是通过强化学习训练的模型能够生成模型。
在此论文中,作者们生成了 10 个模型,对它们进行训练(数个小时),使用生成模型的损失函数作为强化学习的信号。

在 CIFAR-10 图像识别任务上,神经架构搜索的表现与其他较高级成果的表现对比如上图所示。
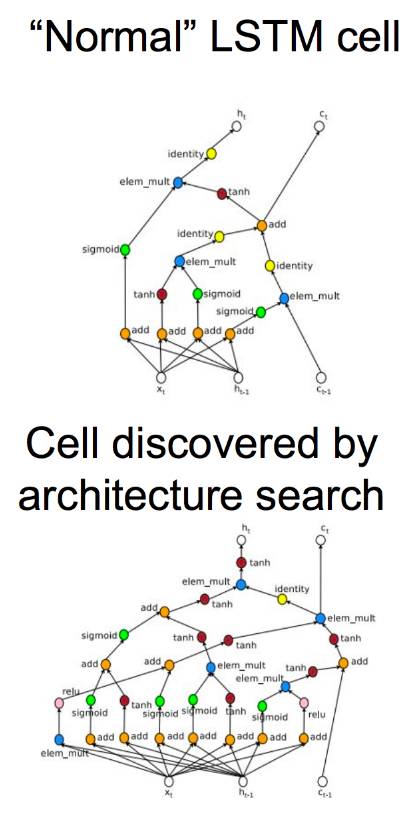
上图是正常的 LSTM 单元与架构搜索所发现的单元图。
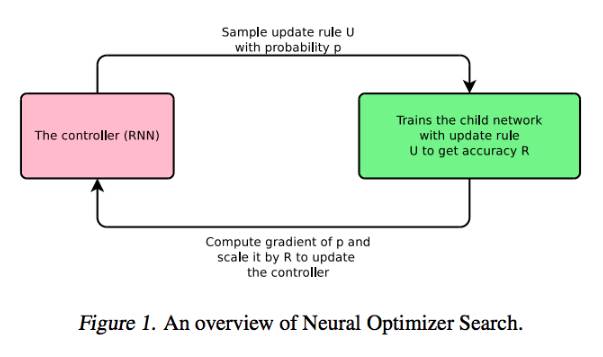
此外,学习优化更新规则也是自动机器学习趋势中的一个信号。通常我们使用的都是手动设计的优化器,如下图所示。

而 Google Brain 在 ICML 2017 的论文《Neural Optimizer Search with Reinforcement Learning》中,就讲到了一种学习优化更新规则的技术。神经优化器搜索如下图所示:
总结
最后,Jeff Dean 总结说,未来人工智能的发展可能需要结合以上介绍的所有思路:需要大型、但稀疏激活的模型;需要解决多种任务的单个模型;大型模型的动态学习和成长路径;面向机器学习超级计算的特定硬件,以及高效匹配这种硬件的机器学习方法。
当然,目前在机器学习与系统/计算机架构的交叉领域还存在一些开放问题,例如:
极为不同的数值是否合理(例如,1-2 位的激励值/参数)?
我们如何高效的处理非常动态的模型(每个输入样本都有不同的图)?特别是在特大型机器上。
有没有方法能够帮助我们解决当 batch size 更大时,回报变小的难题?
接下来 3-4 年中,重要的机器学习算法、方法是什么?
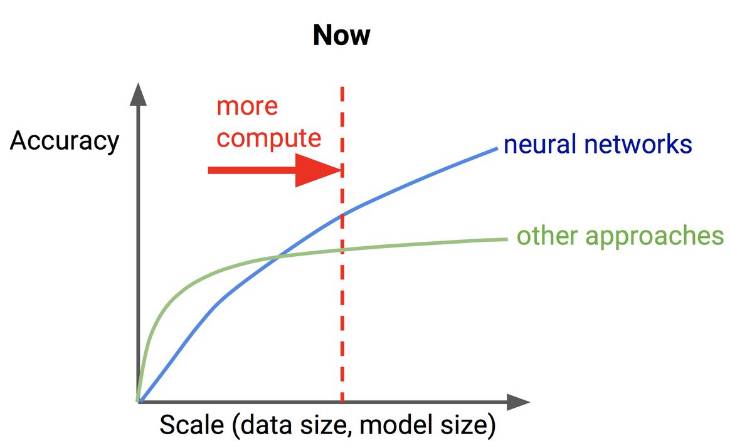
如今,神经网络与其他方法随数据、模型大小变化的准确率对比图如下:
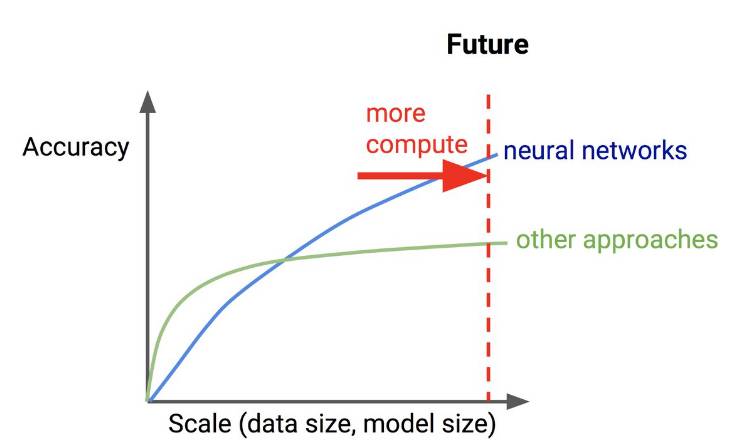
未来,可能又是一番境况。
演讲PPT地址:http://pan.baidu.com/s/1kVyxeB1
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4590.html
摘要:今年月,谷歌发布了。在谷歌内部被称为的方法中,一个控制器神经网络可以提出一个子模型架构,然后可以在特定任务中对其进行训练和评估质量。对于整个领域来说,一定是下一个时代发展重点,并且极有可能是机器学习的大杀器。 为什么我们需要 AutoML?在谈论这个问题之前,我们需要先弄清楚机器学习的一般步骤。其实,不论是图像识别、语音识别还是其他的机器学习项目,其结构差别是很小的,一个效果好的模型需要大量...
摘要:三人造神经元工作原理及电路实现人工神经网络人工神经网络,缩写,简称神经网络,缩写,是一种模仿生物神经网络的结构和功能的数学模型或计算模型。神经网络是一种运算模型,由大量的节点或称神经元,或单元和之间相互联接构成。 一、与传统计算机的区别1946年美籍匈牙利科学家冯·诺依曼提出存储程序原理,把程序本身当作数据来对待。此后的半个多世纪以来,计算机的发展取得了巨大的进步,但冯·诺依曼架构中信息存储...
摘要:在与李世石比赛期间,谷歌天才工程师在汉城校区做了一次关于智能计算机系统的大规模深度学习的演讲。而这些任务完成后,谷歌已经开始进行下一项挑战了。谷歌深度神经网络小历史谷歌大脑计划于年启动,聚焦于真正推动神经网络科学能达到的较先进的技术。 在AlphaGo与李世石比赛期间,谷歌天才工程师Jeff Dean在Google Campus汉城校区做了一次关于智能计算机系统的大规模深度学习(Large-...
摘要:深度学习现在被视为能够超越那些更加直接的机器学习的关键一步。的加入只是谷歌那一季一系列重大聘任之一。当下谷歌醉心于深度学习,显然是认为这将引发下一代搜索的重大突破。移动计算的出现已经迫使谷歌改变搜索引擎的本质特征。 Geoffrey Hiton说:我需要了解一下你的背景,你有理科学位吗?Hiton站在位于加利福尼亚山景城谷歌园区办公室的一块白板前,2013年他以杰出研究者身份加入这家公司。H...
摘要:我的核心观点是尽管我提出了这么多问题,但我不认为我们需要放弃深度学习。对于层级特征,深度学习是非常好,也许是有史以来效果较好的。认为有问题的是监督学习,并非深度学习。但是,其他监督学习技术同病相连,无法真正帮助深度学习。 所有真理必经过三个阶段:第一,被嘲笑;第二,被激烈反对;第三,被不证自明地接受。——叔本华(德国哲学家,1788-1860)在上篇文章中(参见:打响新年第一炮,Gary M...

阅读 946·2023-04-25 22:13
阅读 2385·2019-08-30 15:56
阅读 2272·2019-08-30 11:21
阅读 698·2019-08-30 11:13
阅读 2063·2019-08-26 14:06
阅读 2012·2019-08-26 12:11
阅读 2333·2019-08-23 16:55
阅读 585·2019-08-23 15:30






