
摘要:深度学习自动找到对分类重要的特征,而在机器学习,我们必须手工地给出这些特征。数据依赖深度学习和传统机器学习最重要的区别在于数据量增长下的表现差异。这是深度学习一个特别的部分,也是传统机器学习主要的步骤。
前言机器学习和深度学习现在很火!突然间每个人都在讨论它们-不管大家明不明白它们的不同!
不管你是否积极紧贴数据分析,你都应该听说过它们。
正好展示给你要关注它们的点,这里是它们关键词的google指数:

如果你一直想知道机器学习和深度学习的不同,那么继续读下去,下文会告诉你一个关于两者的通俗的详细对比。
我会详细介绍它们,然后会对它们进行比较并解释它们的用途。
1 机器学习和深度学习是什么?
1.1 什么是机器学习?
1.2 什么是深度学习?
2 机器学习和深度学习的比较
2.1 数据依赖
2.2 硬件依赖
2.3 问题解决办法
2.4 特征工程
2.5 执行时间
2.6 可解释性
3 机器学习和深度学习目前的应用场景?
4 测试
5 未来发展趋势
让我们从基础开始——什么是机器学习,什么是深度学习。如果你已经知道答案了,那么你可以直接跳到第二章。
“机器学习”更受广泛引用的定义是来自于Tom Mitchell对它的解释概括:
“如果一个计算机程序在任务T中,利用评估方法P并通过相应的经验E而使性能得到提高,则说这个程序从经验E中得到了学习”
这句话是不是听起来特别难以理解?让我们用一些简单的例子来说明它。
例子1-机器学习-基于身高预测体重
假如你现在需要创建一个系统,它能够基于身高来告诉人们预期的体重。有几个原因可能可以解释为什么这样的事会引起人们兴趣的原因。你可以使用这个系统来过滤任何可能的欺诈数据或捕获误差。而你需要做的第一件事情是收集数据,假如你的数据像这个样子:
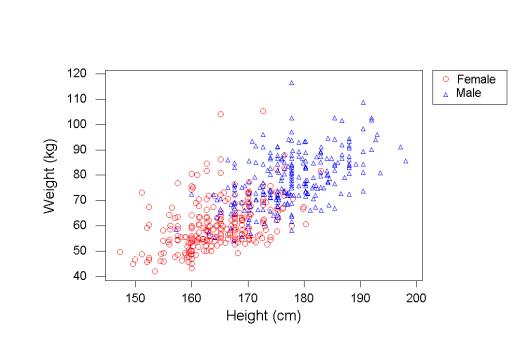
图中的每个点都代表一个数据点。首先,我们可以画一条简单的直线来根据身高预测体重。例如是这么一条直线:
Weight (in kg) = Height (in cm) - 100
它可以帮助我们做出预测。如果这条直线看起来画得不错,我们就需要理解它的表现。在这个例子中,我们需要减少预测值与真实值之间的差距,这是我们评估性能的办法。
进一步说,如果我们收集到更多的数据(经验上是这样),我们的模型表现将会变得更好。我们也可以通过添加更多的变量来提高模型(例如`性别`),那样也会有一条不一样的预测线。
例子2-风暴预测系统
让我们举个复杂一点点的例子。假设你在开发一个风暴预测系统,你手里有过往所有发生过的风暴数据,以及这些风暴发生前三个月的天气状况数据。
想一下,如果我们要去做一个风暴预测系统,该怎么做呢?

首先,我们需要探索所有数据并找到数据的模式(规则)。我们的任务是寻找什么情况下会引起风暴发生。
我们可以模拟一些条件,例如温度大于40摄氏度,温度介于80到100之间等等,然后把这些“特征”手动输入到我们的系统里。
或者,我们也可以让系统从数据中理解这些特征的合适值。
现在,找到了这些值,你就可以从之前的所有数据中预测一个风暴是否会生成。基于这些由我们的系统设定的特征值,我们可以评估一下系统的性能表现,也就是系统预测风暴发生的正确次数。我们可以迭代上面的步骤多次,给系统提供反馈信息。
让我们用正式的语言来定义我们的风暴系统:我们的任务`T`是寻找什么样的大气条件会引起一个风暴。性能`P`描述的是系统所提供的全部情况中,正确预测到风暴发生的次数。而经验`E`就是我们系统的不断重复运行所产生的。
1.2 什么是深度学习?深度学习并不是新的概念,它已经出现好一些年了。但在今时今日的大肆宣传下,深度学习变得越来越受关注。正如在机器学习所做的事情一样,我们也将正式的定义“深度学习”并用简单的例子来说明它。
“深度学习是一种特别的机器学习,它把世界当做嵌套的层次概念来学习从而获得强大的能力和灵活性,每一个概念都由相关更简单的概念来定义,而更抽象的表征则通过较形象的表征计算得到。”
现在-这看起来很令人困惑,让我们用简单的例子来说明。
例子1-形状检测
让我们从一个简单的例子开始,这个例子解释了概念层次上发生了什么。我们来尝试理解怎样从其他形状中识别出正方形。

我们的眼睛首先会做的是检查这个图形是否由4条边组成(简单的概念)。如果我们找到4条边,我们接着会检查这4条边是否相连、闭合、垂直并且它们是否等长的(嵌套层次的概念)
如此,我们接受一个复杂的任务(识别一个正方形)并把它转化为简单的较抽象任务。深度学习本质上就是大规模的执行这种任务。
例子2-猫狗大战
让我们举一个动物识别的例子,这个例子中我们的系统需要识别给定的图片是一只猫还是一只狗。

如果我们把这个当做典型的机器学习问题来解决,我们会定义一些特征,例如:这个动物有没有胡须,是否有耳朵,如果有,那是不是尖耳朵。简单来说,我们会定义面部特征并让系统识别哪些特征对于识别一个具体的动物来说是重要的。
深度学习走得更深一步。深度学习自动找到对分类重要的特征,而在机器学习,我们必须手工地给出这些特征。深度学习的工作模式:
首先识别一只猫或一只狗相应的边缘 然后在这个基础上逐层构建,找到边缘和形状的组合。例如是否有胡须,或者是否有耳朵等 在对复杂的概念持续层级地识别后,最终会决定哪些特征对找到答案是有用的 2.机器学习和深度学习的比较现在你已经了解机器学习和深度学习的概念了,我们接着将会花点时间来比较这两种技术。
2.1 数据依赖
深度学习和传统机器学习最重要的区别在于数据量增长下的表现差异。当数据量很少的时候,深度学习算法不会有好的表现,这是因为深度学习算法需要大量数据来完美地实现。相反,传统机器学习在这个情况下是占优势的。下图概括了这个事实。

深度学习算法高度依赖高端机器,相较之下传统的机器学习算法可以在低端机器中运行。这是因为深度学习算法对GPU的依赖是它在工作中的重要部分。深度学习算法内在需要做大量的矩阵乘法运算,这些运算可以通过GPU实现高效优化,因为GPU就是因此而生的。
2.3 特征工程特征工程是将领域知识引入到创建特征提取器的过程,这样做的目的在于减少数据的复杂性并且使模式更清晰,更容易被学习算法所使用。无论从对时间还是对专业知识的要求,这个过程都是艰难的而且是高成本的。
在机器学习中,绝大多数应用特征需要专业知识来处理,然后根据领域和数据类型进行硬编码。
举个例子,特征数据可以是像素值、文本数据、位置数据、方位数据。绝大多数的机器学习算法的性能表现依赖于特征识别和抽取的准确度。
深度学习算法尝试从数据中学习高级特征。这是深度学习一个特别的部分,也是传统机器学习主要的步骤。因此,深度学习在所有问题上都免除了特征提取器的开发步骤。就像卷积神经网络会尝试学习低级特征,例如在低层中学习边缘和线条,然后是部分的人脸,再接着是人脸的高层表征。

当使用传统机器学习算法求解一个问题时,它通常会建议把问题细分成不同的部分,然后独立地解决他们然后合并到一起从而获得最终结果。然而深度学习却主张端对端地解决问题。
让我们用一个例子来理解。
假设你现在有一个多目标检测任务。这个任务要求识别目标是什么和它出现在图像中的位置。

在一个传统机器学习方法中,你会把问题分成两个步骤:目标检测和目标识别。首先你会用一个像grabcut一样的边框检测算法来扫描图像并找到所有可能的目标。然后,对所有被识别的对象,你会使用对象识别算法,如带HOG特征的SVM,来识别相关对象。
相反地,在深度学习方法中,你会端对端地执行这个过程。例如,在一个YOLO网络中(一款深度学习算法),你传入一个图像,接着它会给出对象的位置和名称。
2.5 执行时间通常神经网络算法都会训练很久,因为神经网络算法中有很多参数,所以训练它们通常比其他算法要耗时。目前较好的深度学习算法ResNet需要两周时间才能完成从随机参数开始的训练。而机器学习相对而言则只需要很短的时间来训练,大概在几秒到几小时不等。
但在测试的时候就完全相反了。在测试的时候,深度学习算法只需要运行很短的时间。然而,如果你把它拿来与K-近邻(一种机器学习算法)来比较,测试时间会随着数据量的增长而增加。但是这也不意味着所有机器学习算法都如此,其中有一些算法测试时间也是很短的。
2.6 可解释性最后,我们也把可解释性作为一个因素来对比一下机器学习和深度学习。这也是深度学习在它被应用于工业之前被研究了很久的主要因素。
举个例子,假设我们使用深度学习来给文章自动打分。它打分的表现十分的好并且非常接近人类水平,但是有个问题,它不能告诉我们为什么它要给出这样的分数。实际在数学上,你可以找到一个深度神经网络哪些结点被激活了,但我们不知道这些神经元被模型怎么利用,而且也不知道这些层在一起做了点什么事情。所以我们不能结果进行合理的解释。
在另一方面,机器学习算法例如决策树,通过清晰的规则告诉我们为什么它要选择了什么,所以它是特别容易解释结果背后的原因。因此,像决策树和线性/逻辑回归一样的算法由于可解释性而广泛应用于工业界。
3.机器学习和深度学习目前的应用场景?维基百科文章给出了机器学习所有应用场景的概述,它们包括:

上图简要总结了机器学习的应用领域,尽管它描述的还包括了整个机器智能领域。
一个应用机器学习和深度学习较好的例子就是谷歌了。
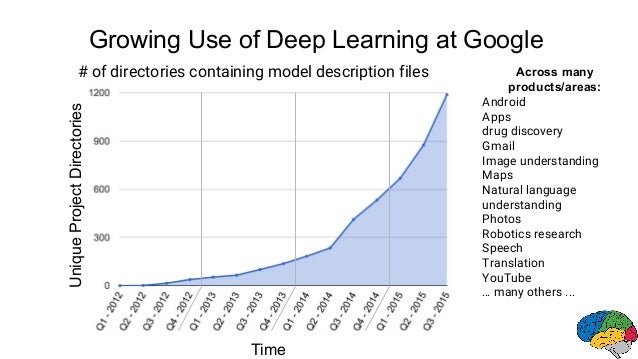
上图中,你可以看到谷歌把机器学习应用在它各种各样的产品中。机器学习和深度学习的应用是没有边际的,你需要的是寻找对的时机!
4.测试为了评估你是否真正了解这些差异,我们接着会来做一个测试。你可以在这儿发布你的答案。
请注意回答问题的步骤。
你会怎样用机器学习解决下面的问题? 你会怎样用深度学习解决下面的问题? 结论:哪个是更好的方法?
情节1:
你要开发一个汽车自动驾驶的软件系统,这个系统会从摄像机获取原始像素数据并预测车轮需要调整的角度。
情节2:
给定一个人的认证信息和背景信息,你的系统需要评估这个人是否能够通过一笔贷款申请。
情节3:
为了一个俄罗斯代表能解决当地群众的问题,你需要建立一个能把俄文翻译成印地语的系统。
5.未来发展趋势上述文章可以给了你关于机器学习和深度学习以及它们之间差异的概述。本章中,我想要分享一下我对机器学习和深度学习未来发展趋势的看法。
首先,由于工业界对数据科学和机器学习使用需求量的增长,在业务上应用机器学习对公司运营会变得更加重要。而且,每个人都会想要知道基础术语。 深度学习每天都给我们每个人制造惊喜,并且在不久的将来也会持续着这个趋势。这是因为深度学习已经被证明是能实现较先进表现的较佳技术之一。 机器学习和深度学习的研究会持续进行。但与前些年局限于学术上的研究有所区别,深度学习和机器学习领域上的研究会在工业界和学术界同时爆发。而且随着可用资金的增加,它会更可能成为整个人类发展的主题。我个人紧随着这些趋势。我通常在关于机器学习和深度学习的新闻中获得重要信息,那些信息会使我在最近发生事情中不断进步。而且,我也一直关注着arxiv上每天更新的论文以及相应的代码。
在这篇文章中,我们从一个相对高的角度进行了总结,并且比较了深度学习跟机器学习的算法之间的异同点。我希望这能让您未来在这两个领域中的学习中变得更有自信。这是关于机器学习以及深度学习的一个学习路线。
如果您有任何的疑问,完全可以放心大胆地在评论区提问。
英文原文链接:https://www.analyticsvidhya.com/blog/2017/04/comparison-between-deep-learning-machine-learning/
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4588.html
摘要:这是机器学习课程中的一个典型例子,他把演讲者的声音和背景音乐分开。虽然用于启动检测的技术主要依赖于音频特征工程和机器学习,但在这里可以很容易地使用深度学习来优化结果。 介绍 想象一个能理解你想要什么,且当你打电话给客户服务中心时能理解你的感受的机器--如果你对某件事感到不高兴,你可以很快地和一个人交谈。如果您正在寻找特定的信息,您可能不需要与某人交谈(除非您愿意!)。 ...
摘要:如今在机器学习中突出的人工神经网络最初是受神经科学的启发。虽然此后神经科学在机器学习继续发挥作用,但许多主要的发展都是以有效优化的数学为基础,而不是神经科学的发现。 开始之前看一张有趣的图 - 大脑遗传地图:Figure 0. The Genetic Geography of the Brain - Allen Brain Atlas成年人大脑结构上的基因使用模式是高度定型和可再现的。 Fi...

阅读 2780·2021-10-14 09:43
阅读 3746·2021-10-13 09:39
阅读 3442·2019-08-30 15:44
阅读 3295·2019-08-29 16:37
阅读 3867·2019-08-29 13:17
阅读 2875·2019-08-26 13:57
阅读 1982·2019-08-26 11:59
阅读 1439·2019-08-26 11:46



